Datenschutzkonformes Conversion Tracking für Google Ads
Die möglichst vollständige Messung von Conversions zur Werbeerfolgskontrolle ist ein wesentlicher Baustein des Marketings - nicht nur, aber vor allem im Online-Bereich.
Dazu hat viele fette Jahre das ungehinderte Ausspielen von Conversion-Tracking Codes zahlreicher Anbieter im Browser gute Dienste geleistet. Spätestens seit der DSGVO hat sich das Spielfeld jedoch deutlich geändert.
Angesichts laufender Entwicklungen rund um Tracking, Webanalyse und Datenschutz im Allgemeinen sowie Google Analytics im Speziellen, scheint eine Bestandsaufnahme der verschiedenen Wege angebracht, mit denen Erfolg im Web (und in Apps) zu messen ist. Das kann auch dabei helfen, die verschiedenen Ausweichoptionen, die sich Werbetreibenden derzeit durch den im Sommer anstehenden Wegfall von Universal Analytics aufdrängen, richtig einzuordnen. Daher ist dieser Beitrag entstanden - parallel zu einem Beitrag mit gleichem Titel bei Dr. DSGVO. Beide Artikel sind unabhängig voneinander erstellt worden, basieren aber auf einer vorherigen Diskussion der Rahmenbedingungen für Conversiontracking. Sie unterscheiden sich in Fokus und Detailtiefe in den Bereichen "Technik" und "Datenschutz", daher empfehle ich das Lesen beider Artikel, um ein möglichst rundes Bild zu erhalten.
Conversion-Tracking: drei Ausbaustufen
Vor der Klärung der Frage, ob und wie (möglichst) datenschutzkonformes Conversion-Tracking für Google Ads und andere Kanäle aussehen kann, müssen Spielfeld und Rahmenbedingungen geklärt werden, unter denen darauf agiert werden kann.
Denn nicht jede Form von Conversion-Tracking hat die gleichen Implikationen… und unter verschiedenen Voraussetzungen fallen selbst beim gleichen Verfahren unterschiedliche Ergebnisse an. Im Kern geht es aber stets darum, Ergebnisse messbar zu machen.
In einem Satz ist Conversion-Tracking die Messung von Ereignissen auf einer Website oder in einer App, die als Erfolg (=”Ziel” oder eben “Conversion”) aus Sicht des Betreibers der Website oder App zu betrachten sind.
Form und Umfang der Messung bestimmen dabei wesentlich, in welchem Kontext welche Fragen durch die Messung beantwortet werden können. Die folgenden Abschnitte zeigen auf, wie sich die Messung und deren Zweck in drei Kategorien - oder Stufen (des Umfangs und Nutzens) einteilen lässt. Mit jeder Stufe steigen üblicherweise die Wechselwirkungen mit Datenschutz-Themen.
Stufe 1 - Zählen von Events
Mit der Messung von Erfolg kann im einfachsten Fall die rein quantitative Betrachtung gemeint sein; sowohl für wesentliche Schritte auf dem Weg zu einem größeren Ziel (“Micro-Conversions”) als auch für das eigentliche Ziel selbst. Im E-Commerce ist dieses Ziel z. B. üblicherweise ein abgeschlossener Verkauf im Onlineshop. Micro-Conversions mögen Dinge wie erfolgte Anfragen, Abos für Newsletter oder das Befüllen einer Wunschliste oder des Warenkorbs sein.
Um zu wissen, wie oft ein Ereignis stattfindet, ist nur dessen Zählung erforderlich - ohne jeden Kontext wie Gerät, Cookies, genauer Zeitpunkt, Standort oder ähnliche Merkmale.
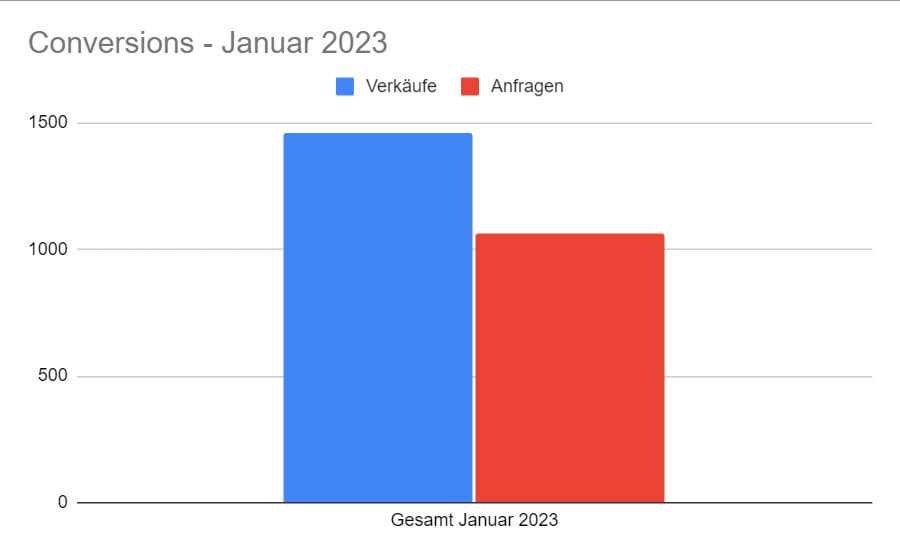
Das ist i. d. R. in einer datenschutzkonformen Weise einzurichten - selbst ohne, dass dazu eine Zustimmung erforderlich wäre. Sind keine unter die DSGVO fallenden Daten im Spiel und muss auch das Gerät weder ausgelesen noch mit gespeicherten Daten versehen werden, bleibt eine Zählung reine Statistik.
Kommen weitere Daten hinzu oder ist irgendwie auf andere Weise eine Verbindung zu anderswo gespeicherten Daten möglich (z. B. durch eine Transaktionsnummer beim gezählten Kauf) müssen aber ggf. bestimmte Bedingungen erfüllt sein. Vorrangig sollten weder Erhebung noch Speicherung und Auswertung der Daten weitere Parteien beinhalten, mit denen potenziell über die reine Zählung hinausgehende Informationen geteilt werden. Im besten Fall handelt es sich ungeachtet des Umfangs der Daten um ein echtes “First Party Setup”, bei dem die Daten komplett selbst (oder mit entsprechenden Verträgen ausgestatteten Dienstleistern als Prozessoren) erhoben und gespeichert werden, um auf Basis dieser Daten eine Zählung der Ereignisse vornehmen zu können.
Stufe 2 - Attribution (wenn die Anzahl allein nicht reicht)
Zu wissen, wie oft etwas stattgefunden hat, ist isoliert betrachtet bestenfalls interessant oder kann dabei helfen, Trends und Prognosen künftiger Zahlen zu ermitteln. Wenn es um Werbeerfolgskontrolle geht, will man die Zahl aufteilen und segmentiert betrachten können. Attribution ist das Stichwort. Dabei soll die Anzahl der Ereignisse und vor allem deren Verteilung auf die Quellen der auslösenden Besucher / Nutzer des eigenen Angebots herunterbrechen werden können. Je nachdem, wie tief man hier einsteigen will, soll idealerweise nicht nur der letzte Kontakt vor dem Erreichen des Ziels berücksichtigt werden, sondern auch ggf. vorherige Sitzungen, die auf andere Quellen zurückzuführen sind.
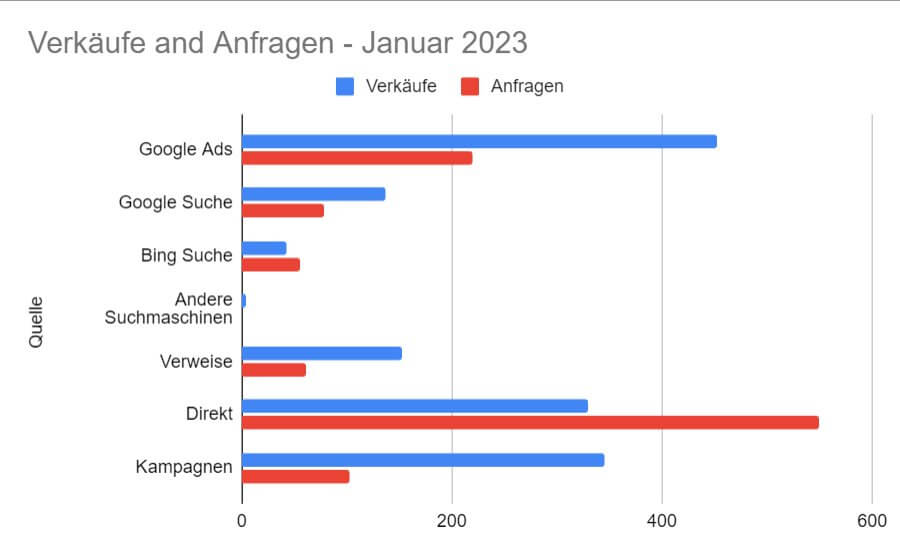
Quellen von Website-Besuchen
Um zu erkennen, woher ein Nutzer kommt, sind streng genommen nur zwei Angaben erforderlich: Der Referrer und die vollständige URL der Seite, auf der die Sitzung “angefangen” hat. Damit man diese Angaben noch kennt, wenn ein Ziel erreicht wird, können verschiedene Systeme verwendet werden.
Typische Kanalaufteilungen wie organischer und bezahlter Traffic, Verweise jenseits von Suchmaschinen, Social Media Sites, Kampagnen-Informationen, die in Form von Parametern der Eintritts-Adresse beigefügt sind - oder Kombinationen davon - leben allein davon, dass beim Start einer Sitzung genau diese Informationen vorhanden sind.
Wenn es um Parameter geht, sind dabei vor allem zwei Typen wichtig:
- Kampagnenparameter wie z. B. UTM-Parameter für Google Analytics oder ein beliebiges vergleichbares System. Das können auch individuelle und proprietäre Parameternamen und -werte sein, die nur der Betreiber der Website selbst in seinem Mess-System wieder in einen Werbe-Kanal, Quell-/Medium-Kombination, Kampagne oder noch granularere Einheiten seiner Werbemaßnahmen auflösen kann. Auch Affiliate Codes o. Ä. gehören in diese Kategorie
- Klick IDs, welche vom Werbesystem vergeben werden, damit deren Tracking-Systeme eine Brücke zwischen Werbemaßnahme / Klick und einem evtl. zurückgemeldeten Erfolg bilden kann. Evtl. dienen Klick IDs auch zur Identifizierung einzelner in einem System angemeldeten Nutzer (wie im Fall der fbclid von Meta). Im Fall von Google Ads spielt die Klick ID gclid auch die zusätzliche Rolle, den Einsatz von ind. Kampagnenparametern unnötig zu machen, wenn es um die Auswertung der Kampagnen mit Google Analytics geht.Unabhängig davon sind Parameternamen von Klick IDs dazu geeignet, aus deren Vorhandensein in einer URL auf den Eintritt aus einer bestimmten Quelle zu schließen.
Selbst ohne deren Speicherung erlauben beide Typen von Parametern also im Zusammenspiel mit dem Referrer, eine Quelle zu bestimmen, wenn ein Seitenaufruf einer Website erfolgt. Zumindest im Rahmen der für die eigene Website relevanten Kanäle / Quellen kann man diese üblicherweise mit einem überschaubaren Aufwand bestimmen.
Das Bindeglied zwischen Start und “Ende”: Identifier
Aus der Perspektive der Messung von Conversions ist es wesentlich, dass man bei Erreichen eines Ziels noch weiß, “woher” ein Nutzer vorher gekommen ist. Nicht immer finden Eintritt und Zielerreichung auf der gleichen Seite statt. Selbst in einer Single Page Application, bei der man in der Theorie eine einfache JavaScript Variable nutzen könnte, um URL nebst Parametern und Referrer noch zu kennen, wenn die Zielerreichung erfolgt, weil kein laufendes Neuladen von Seiten bei der Navigation / Nutzung der Site erforderlich ist, kann ein manueller Reload im Browser durch den Nutzer die Information der Herkunft “vernichten”.
Deshalb müssen die Quellinformationen selbst dann noch bekannt sein, wenn man ausschließlich Conversions vermessen will und den eigentlichen Eintritt und alles vor dem Erreichen des Ziels nicht. Oder es wird sowohl der Eintritt und die Conversion (sowie ggf. alles, was dazwischen passiert) vermessen und es muss möglich sein, das Ziel-Ereignis und das Eintritts-Ereignis nebst Quellinformationen zusammenzuführen.
In der Webanalyse ist es so z. B. üblich, dass Eintritte und Ziele (und der Rest) gemessen werden und dass es für alle Ereignisse einer Sitzung ein gemeinsames Merkmal gibt, das als “Klammer” um die Events / Messpunkte / Seitenaufrufe einer Sitzung gelegt werden kann.
Dazu braucht es einen möglichst eindeutigen Schlüssel, der die Sitzung und deren Quellinformationen mit dem Conversion-Ereignis verbindet. Oder kurz: eine ID, also einen “Identifier”. Wobei dieser Name nichts damit zu tun hat, dass dadurch zwingend eine konkrete Person identifiziert werden kann - oder soll. Es geht in diesem Stadium des Trackings (der reinen “First-Party-Kampagnen-Erfolgskontrolle”) nur darum, dass dadurch die o. A. “Brücke” zwischen Eintritten und Zielen existiert.
Das können sowohl im Browser gespeicherte Angaben wie Cookies oder Identifier im sonstigen Browserspeicher wie localStorage und sessionStorage etc. sein - oder serverseitig generierte Schlüssel, die auf Informationen basieren, die bei der Vermessung verfügbar sind. Für eine Attribution auf die Quelle, welche den zum Zeitpunkt der Zielerreichung aktiven Sitzung geführt hat, sind durchaus kurzlebige Identifier nutzbar. Und diese müssen auch nur vom Mess-System verstanden werden, um diese Aufgabe zu erfüllen.
Je nachdem, ob man serverseitig oder clientseitig solche Schlüssel bildet und ob man Zustimmung hat, Daten aus dem Browser auszulesen oder dort zu speichern, können so mal mehr und mal weniger Datenpunkte und Wege genutzt werden, um einen Identifier zu bilden und zu speichern. Auch dessen Lebensdauer ist an die Mittel gebunden, mit denen gearbeitet werden kann.
Datenschutzkonforme Identifier
Besteht Zustimmung im Browser, ist das Speichern eines Identifiers in einem Cookie oder dem Browserspeicher nach wie vor der beste Weg, um nicht nur eine Klammer um den aktuellen Besuch zu erhalten, sondern einen Besucher (oder besser: dessen gerade verwendeten Browser) auch dann wiederzuerkennen, wenn er zu einem späteren Zeitpunkt wiederkehrt.
Moderne Browser machen dies zwar immer schwieriger und gespeicherte Identifier sind heute nicht mehr so langlebig wie früher, aber dennoch sind sie im Consent-Fall eine gute Option.
Davon ausgehend, dass man auch dann eine minimale Form der Attribution zur letzten Quelle betrachten möchte, wenn keine Zustimmung erfolgt ist, ist die Bildung eines kurzlebigen Identifiers allerdings nicht trivial, denn man darf in diesem Fall nichts im Browser speichern und auch nichts dort auslesen, um aus verschiedenen Merkmalen einen möglichst eindeutigen Schlüssel - einen “Fingerprint” - zu erstellen. Da dazu im Gegensatz zu einem typischen Fingerprint unter Einbeziehung einer Vielzahl von Geräteeigenschaften nur "passiv erhaltene" Informationen genutzt werden, hört man gelegentlich auch Bezeichnungen wie "Soft-Fingerprint", "Passive Fingerprint" und andere.
“Messung ohne Consent”
Die meisten Webanalyse-Lösungen, die heute ein “DSGVO-konformes Tracking ohne Cookies” versprechen, arbeiten dazu mehr oder weniger nach dem gleichen Prinzip:
- Aus der (meistens zunächst gekürzten / anonymisierten) IP Adresse und evtl. anderen Merkmalen wie dem User Agent und / oder der Sprache (soweit diese nicht aus dem Browser ausgelesen werden muss, sondern in den Headern der Anfrage an den Webserver gesendet wird) wird ein Hash gebildet
- Oft wird dabei zusätzlich eine weitere Komponente in Form einer zufälligen Zeichenkette hinzugefügt (“Salt”), mit der verhindert wird, dass der Hash selbst bei Kenntnis der Merkmale wie IP und User Agent etc. eines konkreten Nutzers eine Verbindung mit den Daten erlaubt, ohne den Aufbau der Zeichenkette und eben diesen zusätzlichen Faktor zu kennen, der zu diesem Hash geführt hat
- Einige, aber nicht alle Lösungen arbeiten dabei mit einem Salt-Wert, welcher alle 24 Stunden (z. B. um 0:00 Uhr “Trackingserverzeit”) ausgetauscht wird, so dass nach spätestens einem Tag selbst diese sehr theoretische Rückentwicklung nicht mehr möglich ist, denn der alte Salt-Wert ist nicht mehr bekannt
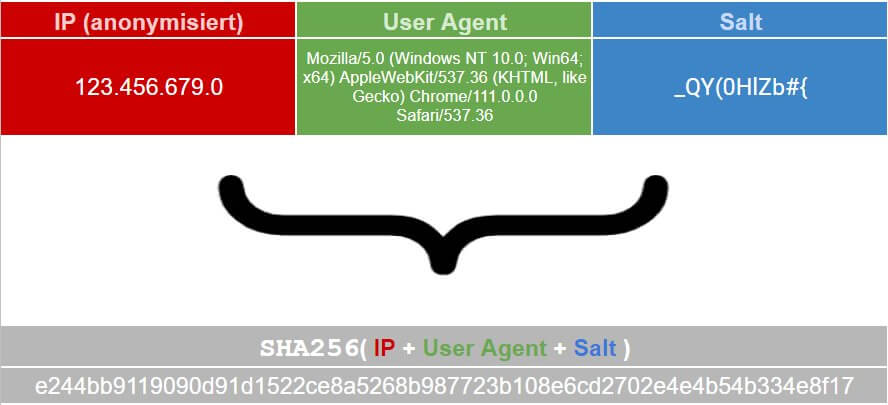
Ob diese Maßnahmen ausreichen, um aus dem Bermudadreieck aus Zustimmung, DSGVO und TTDSG zu entkommen, ist vom jeweiligen Nutzungskontext und Einzelfall sicher unterschiedlich zu bewerten. Datenschützer haben verschiedene Ansichten dazu, was wirklich “machbar” ist und was nicht. Dies zu beurteilen, ist daher stets auf Abstimmung zwischen Implementierung, Nutzung und dem Datenschutz im eigenen Haus angewiesen.
Davon ausgehend, dass es z. B. Datenschutzbehörden gibt, welche den Betrieb solcher Tools unter den richtigen Bedingungen in Ordnung finden, muss es Rahmenbedingungen geben, in denen eine Messung dem Datenschutz genügt. Die französische CNIL hat hier z. B. ganz konkrete Angaben zu Piwik PRO, Matomo und anderen gemacht.
Einschränkungen bei Nutzung kurzlebiger Identifier
Hash-Werte als kurzlebige Identifier haben freilich einige Nachteile gegenüber Cookies; auch jenseits der Lebensdauer. So sind IP Adressen selbst ohne Anonymisierung und regelmäßigen Wechsel durch die meisten Router eher unzuverlässige Indikatoren für einen einzelnen Browser. VPNs, Tracking-Schutz-Maßnahmen, große Firmennetzwerke und andere Faktoren beeinflussen die Auflösungsfähigkeit einer IP auf einen einzelnen Browser und führen zu anderen Zahlen, als es bei Erkennung mit Cookies der Fall wäre. User Agents sind da nicht besser - im Gegenteil. Daher ist die Kombination von User Agent und IP als Hash nicht der beste Weg, um die o. a. Brücke zwischen Ereignissen der gleichen Sitzung oder gar darüber hinaus zu schlagen. Aber immerhin ein Ausweg.
Selbst bei eingeschränkter Auflösung und Zuverlässigkeit haben sich die genannten Kandidaten wie Matomo, Piwik PRO, etracker und andere etabliert, wenn es um die bestmögliche Schließung der Lücke geht, die Consent in den Daten hinterlassen hat. Ein Hybrid-Betrieb, der bei Zustimmung Cookies nutzt und ohne Zustimmung eine eingeschränkte Vermessung und Nutzung der oben beschriebenen kurzlebigen IDs erlaubt, macht diese Tools für die Webanalyse bis zu einem gewissen Punkt zu attraktiven Ersatz- oder Ergänzungs-Systemen zu Google Analytics.
First Party Attribution und Conversion-Messung
Mit dem beschriebenen Rüstzeug ist es demnach durchaus machbar, sich über das, was auf der eigenen Website passiert, auf dem Laufenden zu halten und in gewissem Rahmen auch ohne Zustimmung datenschutzkonform Daten zu erheben. Mit Zustimmung ohnehin… Solange man nicht in eine von zwei Fallen tappt: Der komplette Google Stack ist aus verschiedensten Gründen eher problematisch.
Jenseits davon sollte ein Tracking-Setup, das als “möglichst datenschutzkonform” betrachtet werden kann, alle Anbieter und Infrastrukturen meiden, die auf US Anbieter oder andere aus Datenschutzsicht “unsichere” Drittländer zurückgehen. Nicht, dass es nicht möglich wäre. Google Dienste sind je nach technischen Maßnahmen wie der Entkopplung von Browser und Google durch einen “Proxy” nutzbar, ohne es sich komplett mit dem Datenschutz zu verscherzen. Einen eigenen Tracking-Endpunkt als Zwischenstation mit einer Möglichkeit zur Kontrolle über den Datenfluss zwischen Browser und Google zu betreiben - und diese Kontrolle tatsächlich in einem ausreichenden Umfang auszuüben - ist aber nicht trivial und bedeutet Aufwand (sowie meistens weitere laufende Kosten).
Spätestens bei Einsatz einer EU-gehosteten Lösung mit entsprechenden Maßnahmen und / oder einer komplett selbst betriebenen Vermessung der eigenen Website kann man eine ganze Menge an Kampagnen-Erfolgskontrolle betreiben, um den Erfolg von Werbung zu beurteilen oder Budgetentscheidungen datengestützt zu treffen; Budgets zwischen verschiedenen Kanälen zu verteilen etc.
Zwischenfazit: Attribution auf Basis komplett eigener Daten erlaubt üblicherweise die Nutzung der meisten Dimensionen, nach denen man Ereignisse, Sitzungen und Conversions üblicherweise segmentieren möchte. Klick IDs und andere Parameter dienen in diesem Stadium höchstens dazu, eine Quelle zu identifizieren. Anfragen an Drittserver zum Abruf von Tracking-Scripten oder Versand von Messungen sind entweder komplett unnötig oder unkritisch zu gestalten, wenngleich der Aufwand je nach eingesetztem Tool unterschiedlich groß sein mag.
Stufe 3 - Rückmeldung an Werbesysteme
Ganz anders sieht es allerdings aus, wenn Informationen über Ereignisse auf einer Website den First Party Kontext verlassen sollen. Eben genau das ist es, was bei dem Vorgang erforderlich ist, den man gemeinhin unter "Conversion-Tracking” versteht. Die Information über das Stattfinden von Conversions wird an ein Werbesystem zurückgemeldet.
Dabei sind zwei wesentliche Unterschiede zu beachten:
- Adressierbarkeit: Während ein Cookie oder Hash als ID zum Zusammenfassen einer Sitzung vollkommen ausreicht, solange diese ID im System, das die Daten erfasst, wiedererkennbar ist, muss bei einer Rückmeldung an ein Werbesystem eine ganz andere Voraussetzung erfüllt werden: Die ID, mit der z. B. eine Conversion (oder im Fall von Zielgruppen andere Ereignisse wie Seitenaufrufe etc.) an das System gemeldet wird, muss dort beim Empfänger dazu dienen können, das Werbemittel, Placement, die Kampagne - oder eben im Ernstfall den konkreten Browser - wiederzuerkennen. Dazu dienen entweder Cookies, die das Werbesystem selbst verwaltet und lesen kann, wenn sie Teil der Rückmeldung eines Ereignisses / einer Conversion sind - oder es werden beim Eintritt auf die Website eindeutige Identifier mitgeliefert. Das sind die oben bereits angesprochenen Klick IDs als Bestandteil von Ziel URL (und / oder manchmal dem Referrer) beim Eintritt auf die Website. Soll eine Rückmeldung an ein Werbesystem wie z. B. Google Ads erfolgen, ist dieser Identifier nötig, um den Erfolg auf die im System verwalteten Kampagnen, deren Assets oder den Browser (“Nutzer”) selbst zuzuordnen.
- Als Ersatz für Cookies etc. werden zur Herstellung von Adressierbarkeit heute (leider) vermehrt gehashte oder gar unverschlüsselte E-Mail-Adressen und andere personenbezogene Daten an alle möglichen Systeme gesendet. In der Hoffnung, dass auf der anderen Seite daraus dann wieder ermittelt werden kann, “wem” die Conversion zuzuordnen ist. Dass dies selbst bei Zustimmung problematisch sein kann, sollte auf der Hand liegen und daher (hier) nicht als realistische Option betrachtet werden.
- Der Empfänger der Daten: Wenn eine Rückmeldung an ein Werbesystem erfolgt, die dort nicht nur quantitativ und ohne sonstigen Kontext, sondern i. d. R.zusammen mit dem o. A. Bezug zum Zweck der Zuordnung zu Kampagnen etc. ausgewertet werden soll, werden aktiv Daten mit einem Dritten geteilt. Davon abgesehen, dass je nach Werbesystem also wieder die “Google Falle” oder das “US Problem” lauern, verlassen die Daten dabei oft den Zweck, zu dem sie eigentlich erhoben wurden (und es auch durften)
Ein erster Ausweg ist wiederum die Zustimmung (ungeachtet der Tatsache, dass man selbst bei Zustimmung immer noch in der “Google + US Problematik” stecken mag). Oder die Option, Daten deshalb teilen zu können, weil sie keinen Personenbezug haben und daher keine DSGVO - Anforderungen zu beachten sind und bei der Erhebung keine Informationen aus dem Browser ausgelesen oder dort gespeichert wurden (also der “TTDSG- / ePrivacy”-Teil der Datenschutz-Gleichung).
Lösungen für Google Ads Conversions
Selbst mit allen Infos und Details zu den einzelnen Ausbaustufen, deren Nutzen und Nutzbarkeit sowie den Faktoren, von denen eine Möglichkeit zur Rückmeldung an Google Ads abhängig ist, erscheint es schwierig, eine eindeutige Antwort darauf zu geben, wie man ein “möglichst datenschutzkonformes” Conversion-Tracking für Google Ads einrichten soll.
Das Erreichen von 100% scheint selbst dann Interpretationsspielraum zu bieten, wenn man sich auf das Ausspielen eines separaten Google Ads Trackingcodes oder Google Analytics als Zwischenstation nur ausschließlich nur bei erfolgter Zustimmung beschränkt. Zudem fehlen dann systematisch alle Daten, wenn keine Zustimmung gegeben wurde.
Daher gehen heute viele Lösungsansätze einen anderen Weg: Den Conversion-Import
Conversion-Import als Option
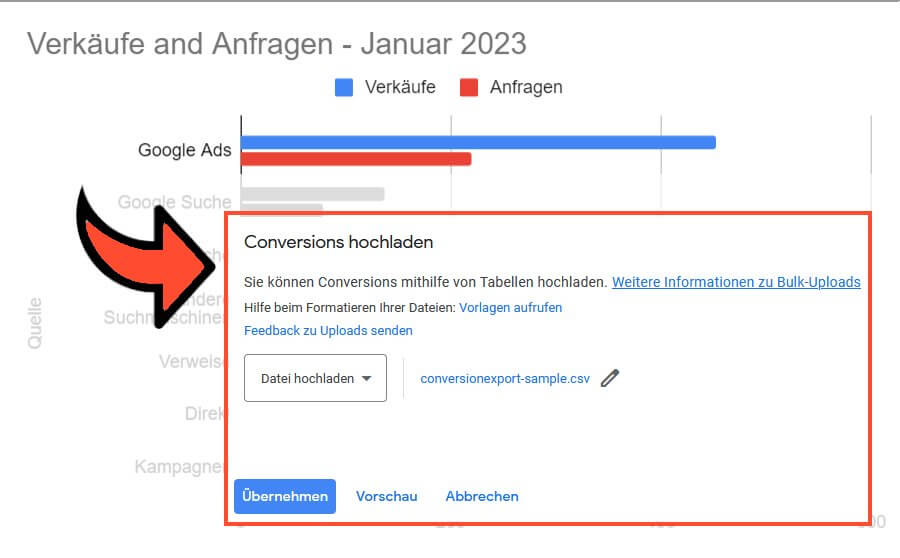
Gerade die o. A. Webanalyse-Lösungen wie Piwik PRO, Matomo und etracker (um diese exemplarisch zu nennen), andere “rohdaten-zentrierte” Angebote wie Snowplow oder Tracking im Selbstbau (wie hier oder hier) nutzen dabei mehr oder weniger stets den gleichen Weg:
- Eine Software zeichnet alle Eintritte auf der Website auf; einschließlich der Google Click ID “gclid”. Diese dient im Rahmen der Attribution der Sitzung zu einer Quelle und ist damit ein Merkmal, mit dem man das Tracking der zweiten Stufe “Attribution” nach der obigen Einteilung erlaubt
- Ebenso wird die Erreichung von Zielen / Conversions im gleichen System vermessen. Ein eigener Identifier oder Hash erlaubt es dabei, das Ziel auf den Eintritt / die Quelle des Besuchs zurückzuführen
- Eine Exportfunktion ermittelt alle Conversions, die auf einen Eintritt mit gclid zurückzuführen sind und listet die Conversions und IDs auf
- Diese Daten können regelmäßig manuell - oder täglich automatisiert - in Google Ads eingelesen werden
Ob dabei nun die gclid separat gespeichert wird, die Schritte zwischen Eintritt und Ziel ebenfalls vermessen werden und zu welchem eigentlichen Zweck die Daten erhoben worden sein mögen: Bei Punkt 4 verlassen sie i. d. R. den Kontext des eigentlichen Zwecks und werden zu einer Rückmeldung an Google Ads. Unter Verwendung eines Identifiers in Form der gclid, die zumindest für Google ein Schlüssel zu zahlreichen weiteren Angaben ist. Evtl. einschließlich des zum Zeitpunkt des Klicks bestehenden Logins mit einem Google Konto.
Darf man das denn?
Die Zwischenüberschrift stellt die Kernfrage, um die sich alle Lösungen drehen. Und mit der die jeweiligen Tools durchaus unterschiedlich umgehen.
Etracker zum Beispiel exportiert Conversions nur dann, wenn diese mit Zustimmung (also aktiven Cookies) gesammelt wurden. Aber hatte man Zustimmung zu “Statistik” bzw. der Webanalyse mit etracker oder tatsächlich zum Teilen der Conversion-Ereignisse mit Google?
Matomo ist auch bei 100% cookielosem Betrieb nach der “CNIL Anleitung” bereit, alle über die bestehenden Kurzzeit-IDs in Form von Hashes aus IP und User Agent in einer Exportdatei bereitzustellen. Oder besser: Es gibt eine entsprechende Erweiterung, mit der das geht, Eine solche steht z. B. bei Nutzung von Matomo Cloud jedem Nutzer zur Verfügung. Schlussendlich stecken die Informationen, die man für diese Form des Exports von Conversions benötigt, in den Rohdaten der Matomo Datenbank - wie bei vielen anderen Tools ebenfalls.
Nur weil es technisch geht, muss es nicht “in Ordnung” sein und Datenschützer und Anwälte mögen diese Form der Nutzung der Daten aus der Webanalyse zum Tracking von Conversions in Google Ads unterschiedlich bewerten. Sonst würde es diese Funktionen vermutlich nicht in mehreren Tools geben. Selbst ohne Anwalt zu sein, kann man sich vorstellen, dass ein solcher Export ein Vorgang ist, der zumindest einen “Edgecase” darstellt, wenn es um diese Form der Nutzung von zum Zweck der Statistik erhobenen Daten geht. Sinnvoll und frei von Risiko ist der Betrieb daher wohl nur mit Zustimmung (dazu hier erneut ein Hinweis auf den "Parallel-Artikel" bei Dr. DSGVO).
Dabei ist die “Klammer” in Form von gekürzter IP, Agent, Salt und Hashfunktion nicht das eigentliche Problem. Das Konfliktpotenzial steckt im Wesentlichen bei den Klick IDs, sobald man sie an Google Ads meldet. Das gilt allerdings ebenso für eine fbclid, die per Import zum gleichen Zweck an Meta zurückgespielt werden kann. Oder das Pendant msclkid aus dem Microsoft / Bing Universum.
Ermittlung von Conversions ohne separates Tracking
Wenn man die Kernfrage, ob man eine ID über den Offline-Import an Google zurückmelden kann, z. B. für Matomo auch bei Fehlen von Zustimmung mit “Ja” beantworten (oder sich bis dort verbiegen) kann, ist sogar ein kompletter Verzicht auf die Implementierung einer Webanalyse-Lösung denkbar.
Wichtiger Hinweis vorab: Die folgend beschriebene Vorgehensweise versteht sich als Konzept. Aus Datenschutzsicht ist es vergleichbar mit dem oben beschriebenen "Matomo Konzept". Denn anders als bei einem browserbasierten Verfahren ist spätestens in Logfiles nicht mehr zu erkennen, wie die Zustimmungslage ausgesehen hat.
Damit zum Konzept: Bei fast allen Websites existiert bereits eine Liste, in der alle URLs von Eintritten inkl. Klick IDs, URLs der erreichten Ziele (freilich nur, wenn diese auf einem Seitenaufruf basieren), IPs und User Agents gespeichert werden: Die Logfiles des Servers.
Logfile als Informationsquelle für Conversions?
Mit einigen Einschränkungen lassen sich allein aus Logfiles alle Informationen zur Generierung eines Conversion Exports für Google Ads (oder Meta oder MS Ads…) ermitteln. Dort finden sich üblicherweise Angaben zu jeder Anfrage an den Web server; gespeichert als einfache Textdatei oder ggf. auch im einlesefreundlichen JSON Format. Darunter Angaben wie…
- Zeitpunkt
- IP (meistens gekürzt, siehe unten)
- Request (Protokoll, vollständiger Pfad etc.)
- Statuscode
- Dateigröße
- User Agent
- Referrer
Damit zeichnet ein Log im Fall eines Eintritts mit einer Klick ID diese im Request auf. Ebenso wird das Erreichen einer Ziel-URL darüber zu finden sein.
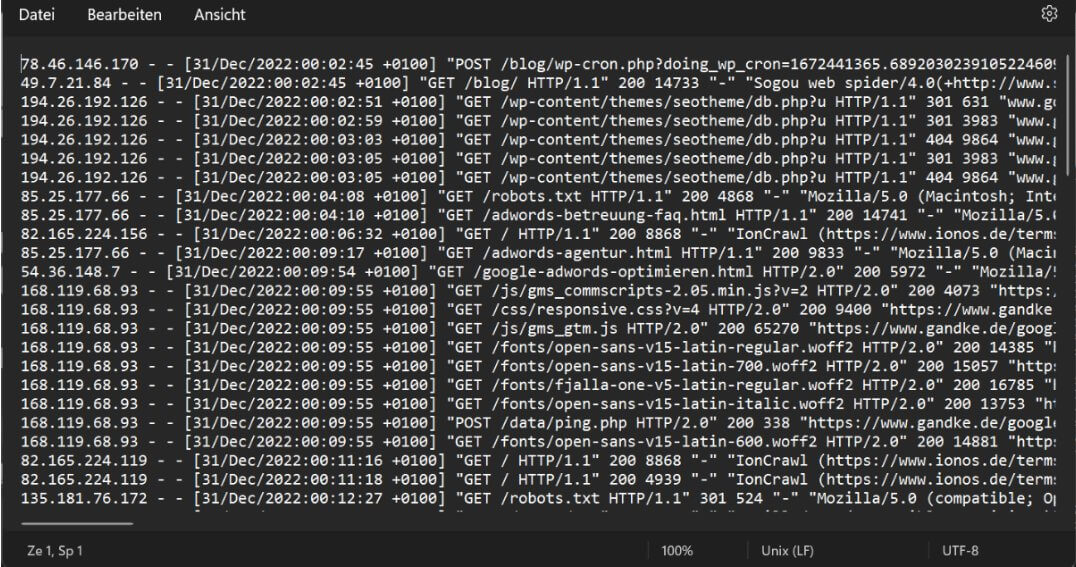
Nutzt man Request / Referrer zur Identifizierung von Quellen beim Eintritt und dem Erreichen von Zielen, können IP und User Agent wie zuvor als Identifier dienen - entweder direkt oder wieder als Hash. Reicht das, um Conversions zu ermitteln? Jein.
Denn zu o. a. Einschränkungen gehört zum Beispiel, dass das Erreichen eines Ziels anhand eines Aufrufs einer URL oder Ressource eindeutig mittels der wenigen im Logfile gespeicherten Informationen erkannt werden muss. Es darf daher kein Cache oder CDN o. Ä. verhindern, dass das Log den Aufruf der Conversion-Seite (oder den Eintritt mit der gclid) aufzeichnet.
Zudem werden die IPs in den Logs normalerweise vom Hoster / Server nicht vollständig gespeichert, sondern gekürzt oder mit Zufallswerten im C-Block befüllt, die somit selbst bei dauerhaft gleichen IPs eine Erkennung am Folgetag bereits nicht mehr ermöglichen. Damit sind IPs aus einem Log in etwa mit der gleichen Trennschärfe versehen, wie die meisten “Fingerprint-Hash-Werte” oben genannter Webanalyse-Lösungen.
Bots sind ein weiteres Problem, die in Logs ungleich mehr Spuren hinterlassen, als in einer über einen Browser mit Daten gefütterten Webanalyse. Nicht immer geben sie sich - wie in diesem Beispiel - im User Agent zu erkennen.
123.183.224.29 - - [04/Mar/2023:00:14:07 +0100] "GET / HTTP/1.1" 200 8428 "-" "Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)"
Davon ausgehend, dass Bots aber selten bis nie mit der gleichen IP eine URL mit einer gültigen gclid aufrufen und anschließend ein Ziel erreichen, kann dieses Problem in vielen Fällen komplett ignoriert werden und bietet kaum Nachteile ggü. Exportdateien aus einer Webanalyse. Das gilt vor allem in einem Online-Shop, wo die URL eines Ziels nicht ohne vorherigen Checkout erreicht werden kann.
Logdateien stehen mehr oder weniger jedem Website-Betreiber zur Verfügung, ohne dass es erforderlich ist, etwas auf der Website auszuspielen, was dem Tracking dient.
Die Ermittlung von Conversions kann manuell durch Herunterladen und Filtern der Logs geschehen oder mit überschaubarem Aufwand automatisiert werden. Nutzt man dabei den Weg des Offline-Conversion Imports, sind zudem alle Signale aus dem Browser eliminiert, die üblicherweise (bei regulären Tracking aus dem Browser) Datenschutz-Implikationen haben könnten. Selbst der Zeitpunkt der Conversion ist durch den gesammelten Import (einmal am Tag oder noch seltener bei manuellem Vorgehen) kein Merkmal mehr, das eine Verbindung zwischen anderen Signalen und der Rückmeldung der Conversion erlaubt.
Allein die Natur der Klick IDs bleibt der kritische Punkt. Daran ändert sich auch nichts; egal ob man als Quelle Logfiles oder eine Webstatistik-Software nutzt, die entweder eingeschränkt ohne Zustimmung oder mit “Statistik-Consent” betrieben wird. Daher ist es wichtig, genau diesen Aspekt nicht nur genau zu verstehen, sondern vor einer Implementierung bzw. Nutzung eines der vorgestellten Wege mit den Anforderungen des Datenschutzes abzustimmen. Oder - wenn das der Ansatz ist, mit dem man dem Thema Datenschutz begegnen will - zumindest das Risiko,welches zweifelsfrei in dieser Vorgehensweise steckt, abzuwägen gegen den wirtschaftlichen Nutzen.
Fazit und Handlungsempfehlung
Eines ist klar: Werbung kostet Geld und ist nur dann sinnvoll, wenn sie auf die eine oder andere Weise profitabel ist. Dazu erscheint nicht nur eine Kontrolle (Stufe 1 und 2), sondern eine Rückmeldung an die Werbesysteme nahezu unverzichtbar. Auch deshalb, weil die dortigen modernen automatisierten Gebotsstrategien sonst nicht betrieben werden können. Der Algo will gefüttert werden, um Entscheidungen auf Basis möglichst vieler Daten zu treffen. Wer dazu Conversions zurückmelden will, muss sich der Implikationen ebenso bewusst sein, wie derjenige, der sich gegen eine Conversion-Messung entscheidet.
Dazu kommt: Mit Zustimmung allein ist es oft nicht getan. Dazu ist die typische Implementierung eines Consent Tools auf vielen Websites ohnehin meistens unzureichend. Wer eine Rückmeldung mit Statistik-Consent - oder selbst ohne dies - im Sinn hat und dazu die Export-Funktionen der Webanalyse-Tools (oder “nur” aus Logfiles ermittelt) einsetzt, sollte sich wegen der ganzen in diesem Beitrag angesprochenen Details unbedingt der Unterschiede zwischen “einfachen Identifiern” und Adressierbarkeit im Klaren sein und die Feinheiten beachten, wenn Daten den Kontext der eigentlichen Zwecke verlassen. Nach dem Lesen dieser 3000+ Wörter kann man zumindest eine informierte Entscheidung als Betreiber treffen, ob, unter welchen Bedingungen und in welcher Form Tracking von Conversions auf der eigenen Website stattfinden soll. Diesen Luxus hat man als Besucher einer Website ja in diesen verrückten Zeiten eher selten 😉
Grundlage Nummer Eins für Conversion-Tracking bleibt die explizite Zustimmung. Spätestens zur Bildung von Zielgruppen kommt man ohnehin nicht daran vorbei; sei es über Google Ads Tagging oder Google Analytics.
Wem es ausschließlich um Conversions geht, kann sich den ganzen “Overhead” einer Webanalyse hingegen sparen; egal ob mit oder (wenn man daran “glaubt”) ohne Zustimmung. Die Vermessung aller Eintritte ohne erkennbare Quelle ist für Conversion-Tracking z. B. unnötig; zumindest bei fehlenden Identifiern, die eine Wiedererkennung und Attribution jenseits der aktuellen Sitzung erlauben.
Gleichfalls verzichtbar sind alle Aufrufe und Events, die auf dem Weg zum Ziel geschehen mögen. Das macht zumindest die technische Einrichtung einer auf Conversions fokussierten Messung überschaubar. Im Sinne einer möglichst reduzierten Erfassung bei gleichzeitig hoher Abdeckung sind Spezial-Lösungen oder selbst Logfiles ggf. eine Option. Matomo & Co. sind hingegen erst dann eine gute Wahl, wenn es wirklich Bedarf für Webanalyse gibt. Unter allen Bedingungen scheint aber eine Zustimmung unverzichtbar (und zwar nicht nur zur “Statistik”), wenn Klick IDs an Google gesendet werden. Und ohne geht es (jedenfalls derzeit) nicht (wenn man nicht den dunklen Weg beschreiten will, auf dem E-Mail-Adressen und andere Daten als Ersatz-IDs herhalten). Ob die nicht auf einen einzelnen Klick zurückgehenden (und mäßig dokumentierten) IDs gbraid und wbraid, die unter gewissen Umständen entstehen, hier einen Unterschied ergeben? Ich weiß es nicht. Aber wie es scheint, sind diese ohnehin für den Offline Import bei Google ungeeignet (ich habe es in Tests jedenfalls vergeblich versucht).
Damit: Happy Tracking!