Logalytrix: "Logfile-Analyse Showcase" Tool für Webserver-Logs
Damals, als mein Haar noch voll war und bevor es Webanalyse mit "Tracking-Pixeln" gab, waren Logfiles mal sexy. Seither hat mein Kopf reichlich Haare - und das Thema jenseits von Monitoring und IT immer mehr an Relevanz - verloren. Obschon doch so viel mehr in Logs seht als Seitenaufrufe. Einiges davon war und ist auch im Marketing interessant. Mit der wachsenden Relevanz von KI Crawlern für Training und Grounding erinnern sich nun verschiedenste Disziplinen wieder an den Wert von Logfiles. Die Ironie: In den Übersichten im Backend der meisten Hoster und Server ist die Zeit stehen geblieben. Wir sehen Balkendiagramme und "Hit-Zähler", wie es sie schon in den Neunzigern gab. Wer mehr wissen will, muss sich auch heute noch oft selbst einen passende Stack dazu aufbauen... mit entsprechendem Aufwand und technischen Hürden.
Logalytrix ist mein Versuch, das zu ändern: Ein Logfile-Analyzer, der aus Rohdaten echte Analyse ermöglicht... wenngleich nicht perfekt. Aber anders als typische und meist statische Reports und Auswertungen. Das ganze passiert lokal, in einer einzigen HTML-Datei, ohne Backend - und mit ein paar Fähigkeiten, die man in diesem Segment nicht erwartet. Neugierig geworden? Hier die Story dazu und ein Blick in die Funktionen und Besonderheiten.
Logalytrix als "Missing Link"
Das Spektrum der Logfile-Analyse scheint zwei Enden und eine auffällige Leere in der Mitte zu haben. Auf der einen Seite stehen die Hoster-Statistiken. AWStats, Webalizer, oder was auch immer das Webhosting-Panel mit bunten Diagrammen produziert. Hits pro Tag, Top-10-Seiten, ein paar Länderfähnchen, fertig. Wer sich fragt, ob die Website noch läuft: ja, reicht. Wer aber wissen will, welcher Traffic von KI-Bots kommt, was genau diese tun oder wo sie Probleme a) verursachen oder b) bei der Erfassung der Inhalte haben, steht wegen der statischen Natur dieser Reports schnell auf dem Schlauch.
Auf der anderen Seite steht der ELK Stack - Elasticsearch, Logstash, Kibana. Oder ELG, Grafana mit Loki oder tausend andere Kombinationen. Und selbstverständlich gibt es inzwischen einen Haufen von SaaS Tools, die den KI-Crawlern ihre digitalen Spuren abringen. Mächtige Werkzeuge, keine Frage. Aber auch: eigene Server, eigene Pipelines, eigene Query-Sprache, eigene Wartung und so weiter. Für ein Team mit DevOps-Kapazität ist das eine Option. Fremd gehostet hingegen ggf. ein Datenschutzproblem. Und für einen Website-Betreiber, der einfach mal verstehen will was in seinen Logdateien steht, ist das allerdings kein einfach zur Hand genommenes Werkzeug, sondern ein erschreckend komplexes Projekt.
Dazwischen gibt es durchaus GoAccess und eine Handvoll ähnlicher Tools. Gut für einen schnellen Überblick auf der Kommandozeile. Aber auch hier: Hit-Zählung, Top-Listen, fertig. Keine Session-Bildung, keine Bot-Klassifizierung nach Kategorien, keine Attribution, keine Angriffserkennung. Was fehlt, ist nicht noch ein Tool das Hits zählt. Logalytrix soll dabei helfen, aus Logdaten die Fragen zu beantworten, die man eigentlich stellen will: Wer kommt wirklich? Was tun die Besucher? Wo laufen Browser oder Bots gegen Fehler oder versuchen, der Website zu schaden? Überhaupt: Welche Bots sind nützlich, welche nicht? Und eben auch die Frage was machen KI-Crawler auf meiner Seite?
Eine Datei, kein Stack, breites Spektrum an Funktionen. Warum das?
Logalytrix ist eine einzige HTML-Datei. Kein Server, kein Backend, kein Account, keine Installation. Das ist sowohl Absicht als auch die einzige Option für mich, dieses Tool mit anderen zu teilen, denn es ist entstanden, weil ich nach meinem Relaunch wissen wollte, ob die Umstrukturierung "gut verdaulich" ist. Also habe ich ein Logfile-Analyse Tool für meinen Server realisiert, das neue Logs automatisch einlesen und mir aus verschiedenen Perspektiven zeigen kann, was auf meiner Website passiert.
Wie das heute dank Agentic Coding ist, sind dabei einige Funktionen in das Tool eingeflossen, einfach deshalb, weil ich sie "schon hatte": Vor Jahren schon ist aus A.T.Z.E. (Repo) die Logfile-basierte Variante L.A.T.Z.E. geworden (hier ab Slide 34 kurz erklärt), also lag es nah, auch diesem Tool Konzepte wie Sessions, Users und Conversions hinzuzufügen. Ideen wie die Pfadanalyse in Analytrix hingegen sind hier zuerst entstanden und einfach drin geblieben.
Damit ich das Werkzeug mit anderen teilen kann, habe ich das Projekt umgestellt, so dass ich sowohl meine Server-Version als auch diese einfache Single-File-Variante parallel pflegen kann. Datei öffnen - fertig. Das funktioniert sogar über file:// direkt von der Festplatte, ganz ohne Webserver. Vanilla JavaScript, Vanilla CSS, keine externen Abhängigkeiten und alles lokal.
Was nach Kompromiss klingt, ist aber eine bewusste Entscheidung. Server-Logdaten sind sensibel - möglicherweise vollständige und ungekürzte IP-Adressen, (weniger problematisch) User-Agents, manchmal (sehr problematisch) Query-Parameter mit persönlichen Daten wie Mailadressen und Namen etc. Ein Tool, das diese Daten zur Analyse in eine Cloud schickt oder auch nur einen Server benötigt, erzeugt genau die Datenschutzprobleme, die man vermeiden will. Bei Logalytrix verlassen die Daten den Browser nicht. IndexedDB speichert alles lokal, die Analyse überlebt einen Browser-Neustart, und beim nächsten Öffnen sind die Daten noch da.
Unterstützt werden zur Zeit Apache Combined Log (das Standardformat, das fast jeder Webserver spricht), inklusive Varianten mit Host-Feld, Response Time am Zeilenende oder im Hetzner-Format. Dazu JSON-Logdateien (ein Objekt pro Zeile, flexible Feldnamen) und Gzip-komprimierte Dateien, die der Browser nativ entpackt. Das Import-Limit skaliert dynamisch mit dem verfügbaren Browser-Speicher - Minimum zwei Millionen Zeilen, bei genügend RAM auch deutlich mehr. Klingt absurd für eine Browser-Anwendung? Funktioniert aber. Weil man schon beim Import wählen kann, was man sich überhaupt anschauen will. Damit beginnen schon die Besonderheiten.
Import als Analysewerkzeug
Die meisten Log-Analyzer laden alles und filtern danach. Bei Millionen von Zeilen im Browser ist das keine Option - oder genauer: es ist eine Option, aber eine schlechte. Logalytrix dreht das deshalb um: Schon beim Import entscheidet man, was überhaupt in die Datenbank des Browsers soll.
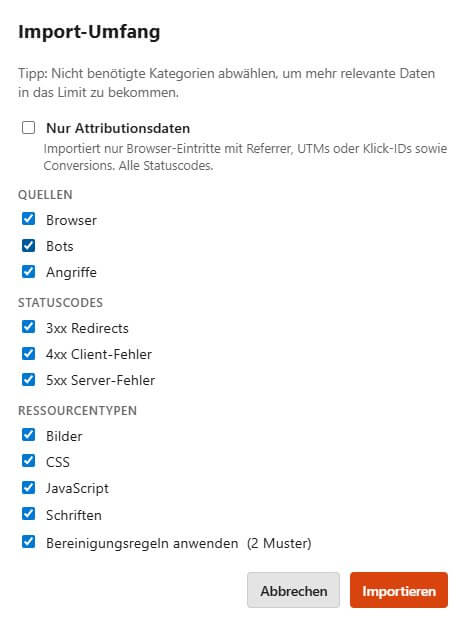
Der Import-Dialog bietet neben Filtern für Statuscodes und Ressourcentypen auch Kategorien: Browser-Traffic, Bot-Traffic, Angriffe - jeweils einzeln an- oder abwählbar. Wer sich für das Verhalten echter Besucher interessiert, importiert nur Browser-Traffic und Seiten - und hat damit mehr Platz für relevante Daten innerhalb des Limits. Wer Bot-Verhalten analysieren will, macht es umgekehrt. Die Klassifizierung als "Angriff" ist dabei ein echtes "Pareto-Feature": Es konzentriert sich (hart im Code verdrahtet, damit es einfach bleibt) auf typische Muster und Pfade, kombiniert mit Statuscodes. Wer also ein "wp-admin" irgendwo hat, wird es nicht als Angriff in Logalytrix sehen. Laufen diese aber gegen etwas anderes als 2xx Statuscodes, sind es vermutlich vergebliche Scans nach offenen Backends und bekannten Sicherheitslücken oder Path-Traversal-Versuchen. Das alles wird als "Angriff" klassifiziert. Nicht perfekt (das gebe ich gern zu und in "meiner" Variante kann ich die Muster auch bearbeiten), aber dennoch hilfreich genug, um diese Dinge einigermaßen gezielt ein- oder auszuschließen.
In die gleiche Richtung gehen Bereinigungsmuster. Health-Checks, Monitoring-Pings, interne Pfade, der eigene Tracking-Endpunkt an der Cloud Edge via Tag Gateway - das alles sind Dinge, die in jedem Log stehen und fast nie interessieren. Diese Muster (per Substring, Prefix oder Regex) lassen sich schon vor dem Import einmal definieren und dann anwenden. Treffer werden gar nicht erst importiert und zählen nicht gegen das vom Browserspeicher gestimmte Limit. Die gleichen Muster funktionieren zudem auch nachträglich als Filter - reversibel, als Chip in der Filter-Leiste sichtbar - oder zur "permanenten" Bereinigung der Datenbank.
Das ergibt zwei Ebenen: Der Import bestimmt, was in der Datenbank ist. Die Filter bestimmen, was man gerade sieht. Zusammen machen sie das Browser-Limit zum erträglich, weil man nicht alles laden muss, um alles Relevante zu haben.
Dreiklassengesellschaft in einer Tabelle
Die Rohdaten-Ansicht zeigt alle Log-Einträge nach dem Import als sortierbare Tabelle.
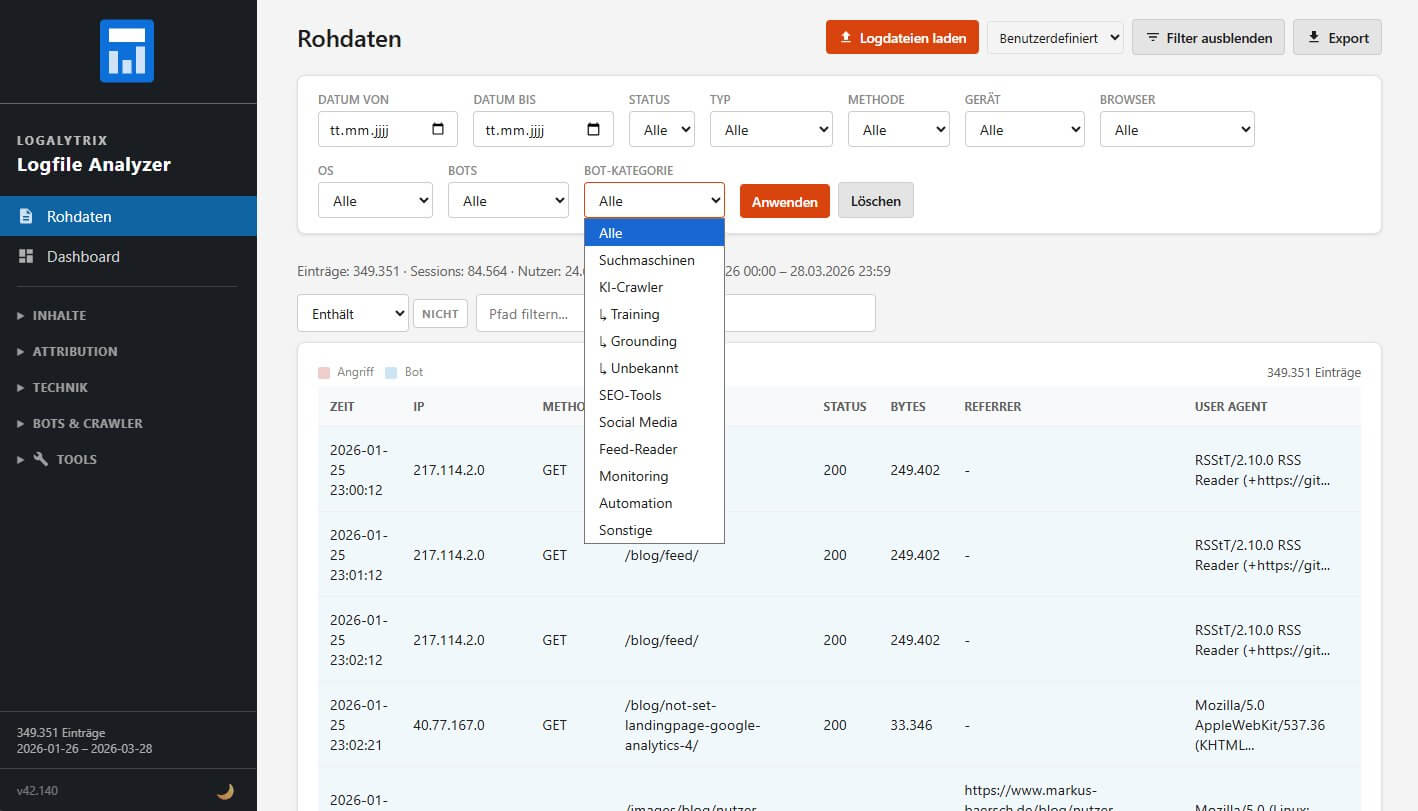
Was diese von einer einfachen Tabelle unterscheidet: Farbcodierung. Angriffs-Requests und Bot-Requests werden farblich hervorgehoben - sofort erkennbar, ohne erst filtern zu müssen. Jeder Request wird dazu beim Import als Browser, Bot oder Angriff klassifiziert. Hier sieht man einen solchen potenziellen Angriff: Es ist der Aufruf einer nicht existierenden Login-URL für WordPress. Da hilft auch kein realistischer Referrer und / oder User Agent: Die URL und der Statuscode reichen, um diesen Request das Label "Angriff" - oder übersetzt: "ziemlich sicher kein Mensch" aufzukleben. Ein bekennender Bot ist es auch nicht, bleibt nur die dritte Option.
Warum das etwas ändert, wird klar, wenn man sich die Zahlen anschaut. Je nach Website besteht der Traffic zu 30 bis 70 Prozent aus Bots. Suchmaschinen-Crawler, SEO-Tools, Social-Media-Previews, Feed-Reader, Monitoring-Dienste - und seit einiger Zeit eine wachsende Zahl von KI-Crawlern. Dazu kommen die oben genannten Angriffe. Wer all das in einen Topf wirft und dann "Top-Seiten" abliest, bekommt eine Liste die üblicherweise mehr über Bot-Verhalten aussagt als über menschliche Besucher.
Mittels der Filter sind auch nachträglich die Daten auf "nur Angriffe", einen bestimmten Zeitraum, nur 4xx-Statuscodes etc. zu begrenzen. Die Rohdaten-Ansicht wird so bereits zur gezielten Recherche-Ansicht statt nur reines Reporting zu liefern. Logalytrix erkennt zur Klassifizierung rund 70 Bots namentlich - von den verschiedenen Googlebot-Varianten über Tools bis GPTBot, ClaudeBot & Co. Unbekannte Bots werden über generische Muster im User-Agent identifiziert. Die erkannten Bots werden in acht Bot-Kategorien sortiert wie z. B. Suchmaschinen, KI-Crawler, SEO-Tools, Social Media etc.
Der ehrliche Disclaimer: Mustererkennung anhand von User-Agent-Strings und Pfaden ist nicht perfekt. Ein Bot kann sich als Browser ausgeben, ein Angriff kann über einen unauffälligen Pfad laufen. Es geht aber wie gesagt hier nicht um Perfektion, sondern darum, Rauschen möglichst schnell und ansatzweise sauber von den Signalen zu trennen, die man gerade untersuchen will. Das funktioniert in der Praxis (für mich zumindest) auch erstaunlich zuverlässig.
Dashboard und Zeitverlauf
Nach dem Import ist neben den Rohdaten üblicherweise ein Dashboard der erste Anlaufpunkt in Logfile-Tools. Das ist hier nicht anders.
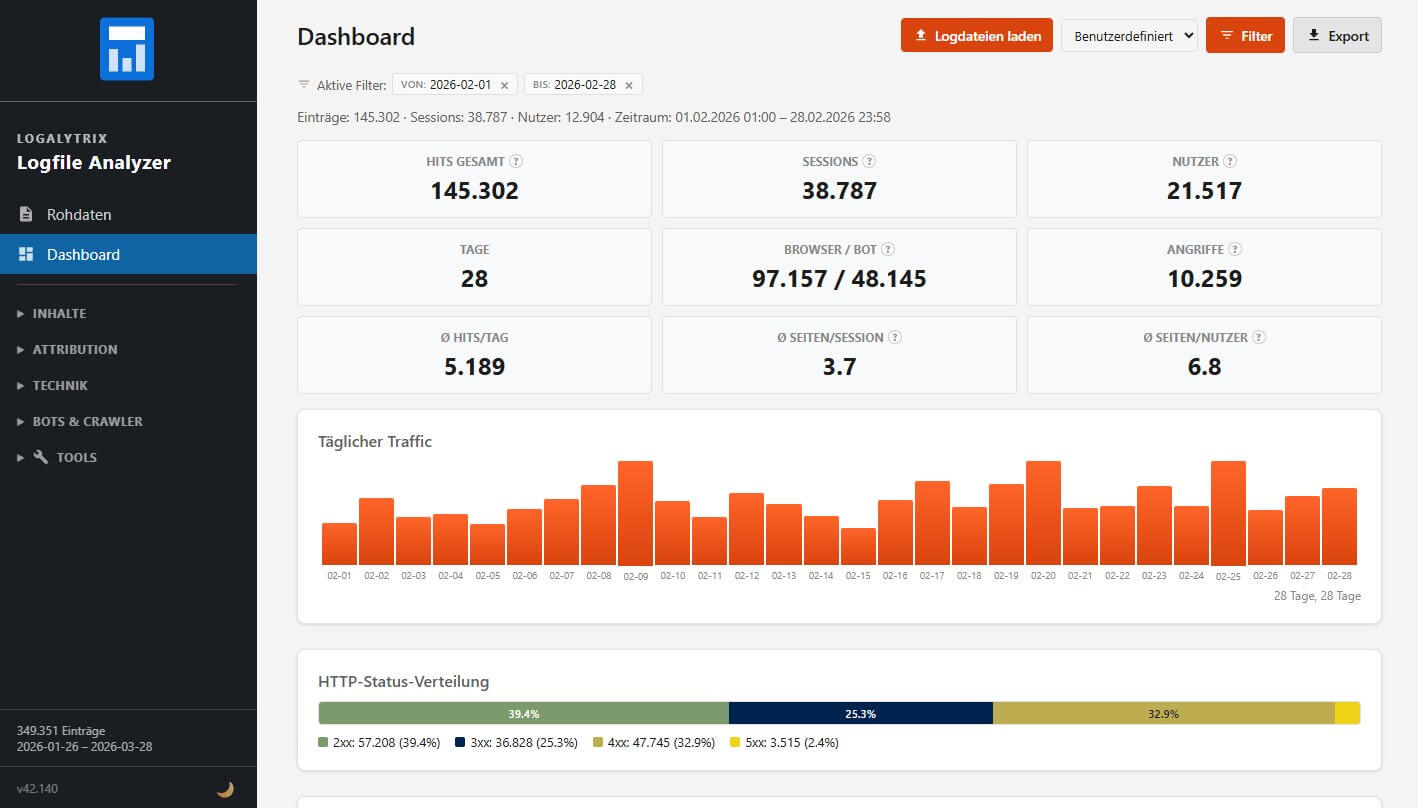
Als Besonderheit filtert hier ein Klick auf einen Balken den Zeitraum. Bei drei Tagen oder weniger wechselt die Ansicht automatisch auf stündliche Auflösung. "Rauszoomen" geht genauso schnell: Filter wieder entfernen, Gesamtbild ist zurück. Längere Zeiträume wiederum werden hier nach Wochen gruppiert. Wem das nicht reicht an "Grafik", kann sich in einem der integrierten Tools einen eigenen Zeitverlauf für verschiedene Metriken und in unterschiedlichen Diagrammformen zusammenstellen, wie auch immer es der Analyseaufgabe hilft. Ein Beispiel:
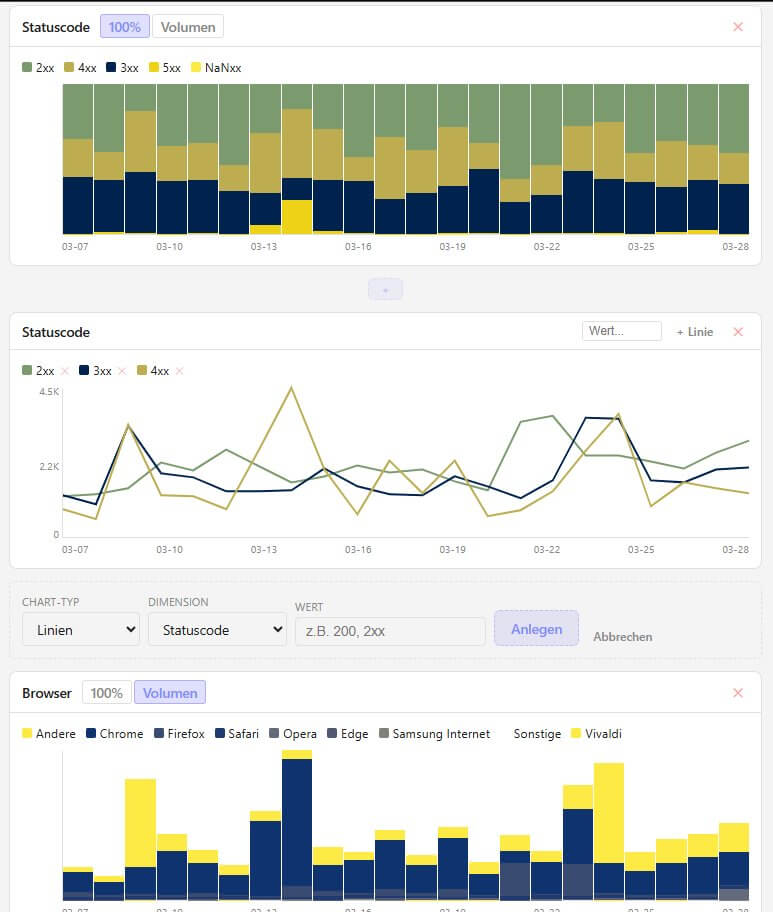
Speziell hier machen sich die Filter bezahlt. Bot-Kategorie auf "KI-Crawler" setzen und das Dashboard zeigt ausschließlich deren Perspektive. KPIs, Zeitverlauf, Top-Seiten - alles aus Sicht der KI-Crawler. Zurück auf "Alle", nächster Filter. Gleiche Idee wie Grafana-Dashboards mit Variablen, aber ohne Setup, ohne Query-Sprache, ohne Datenbank. Zusätzlich haben die meisten Views noch eigene Filter, um die Ansicht gezielt einzuschränken. Denn wie in der Webanalyse gilt: "alles" zu betrachten ist selten hilfreich. Segmentierung ist der Schlüssel zu vielen Antworten.
Im Dashboard selbst zeigen so auch schon einfache Segmentbalken bereits Hinweise auf ungewöhnlichen Traffic (wenn z. B. plötzlich viel POST auftaucht). Kleinigkeiten machen hier den Unterschied (klar ist das nur meine Meinung): Response-Time-Charts z. B. mit Median und Durchschnitt als Doppelbalken.
Hinweis: Elemente wie diese sind nur sichtbar wenn auch Response Time im Log vorhanden ist. Da dies für viele Fragestellungen nicht unwichtig ist, sollte man sich ggf. beim Hoster um eine Anpassung des Logformats bemühen. Entweder kann man dies selbst einstellen oder ggf. den Support bemühen.
Sessions und Journeys
Aus den einzelnen Requests eine Einheit zu machen, ist nicht für alle Aufgaben erforderlich. Aber aus isolierten Punkten ohne Zusammenhang "Verhalten" von Bots oder Menschen abzulesen, ist kein Spaß. Viel einfacher ist es, wenn man zwei Konstrukte einsetzt: Nutzer und Sessions.
Ein "Nutzer" in Logalytrix ist eine Kombination aus IP-Adresse und User-Agent, weil hier Kein Cookie oder andere Signale verfügbar sind: Nicht perfekt, aber eine gute Annäherung. Eine neue Session beginnt nach 30 Minuten Inaktivität des gleichen "Nutzers". Das ist das gleiche Modell, das die meisten Web-Analyse-Tools verwenden - nur dass es hier auf Server-Daten basiert statt auf clientseitigem Tracking. Mit allen Stärken (100% der Requests, kein Consent-Problem, kein Sampling) und allen Schwächen (VPN-Nutzer werden zusammengelegt, ein Mensch mit zwei Browsern ist zwei Nutzer, Gerätewechsel erzeugt neue Identitäten).
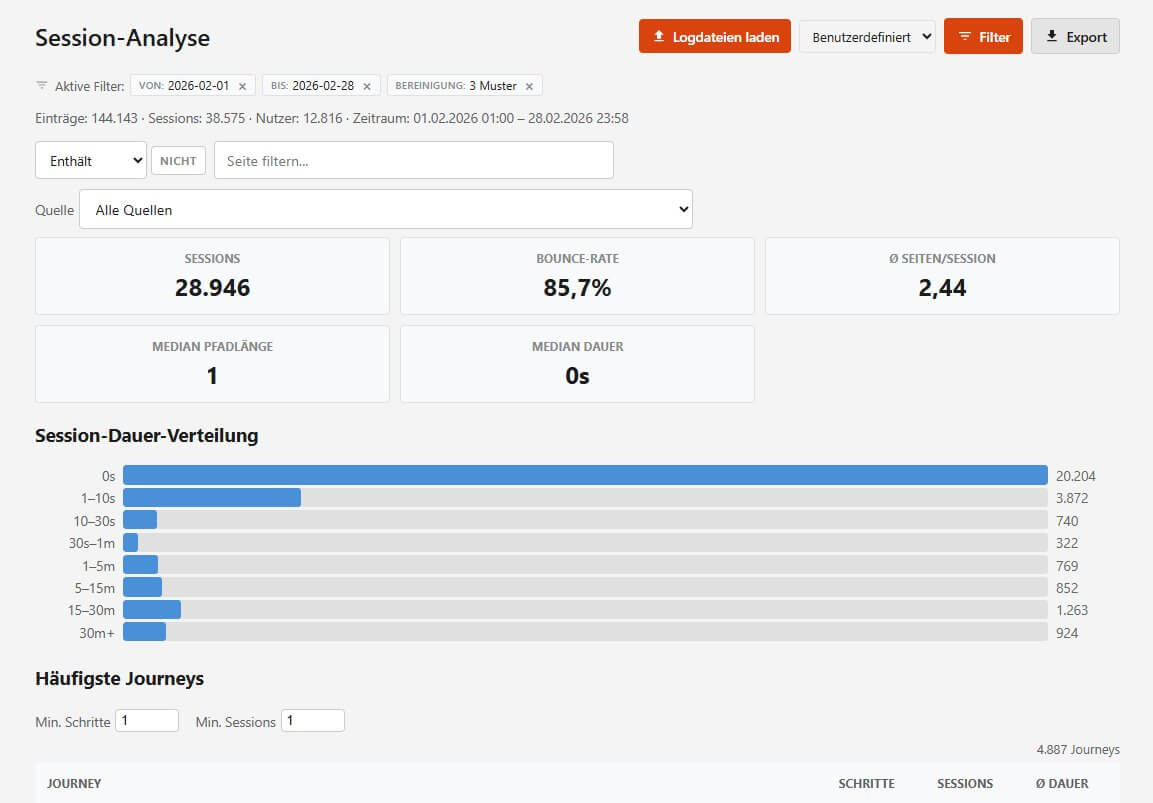
Auf dieser Grundlage baut die Session-Analyse Kennzahlen wie Bounce-Rate, durchschnittliche Seiten pro Session, Median der Pfadlänge und Session-Dauer. Ein Histogramm zeigt die Verteilung der Session-Dauern - und bestätigt das, was man ahnt: Die meisten Sessions sind kurz. Die spannenden aber sind es nicht 😉
Die Journey-Tabelle zeigt daher die häufigsten vollständigen Pfade. /home → /produkte → /produkt-detail → /warenkorb als eine Zeile mit Häufigkeit, Schritten und Dauer. Filter für Mindest-Schritte und Mindest-Sessions reduzieren das Rauschen. Die Suche filtert auf Journeys, die einen bestimmten Schritt enthalten - "zeig mir alle Wege durch /warenkorb".
Navigationsübersicht
Verwandt damit ist ein Feature, das Nutzer von Google Universal Analytics wiedererkennen werden: die Navigationsübersicht. Für jede Seite - oder per Muster-Matching für ganze Seitenbereiche wie /blog* - zeigt ein Drei-Spalten-Layout die vorherigen Seiten, die aktuelle Seite mit Ein- und Ausstiegsraten, und die nachfolgenden Seiten.
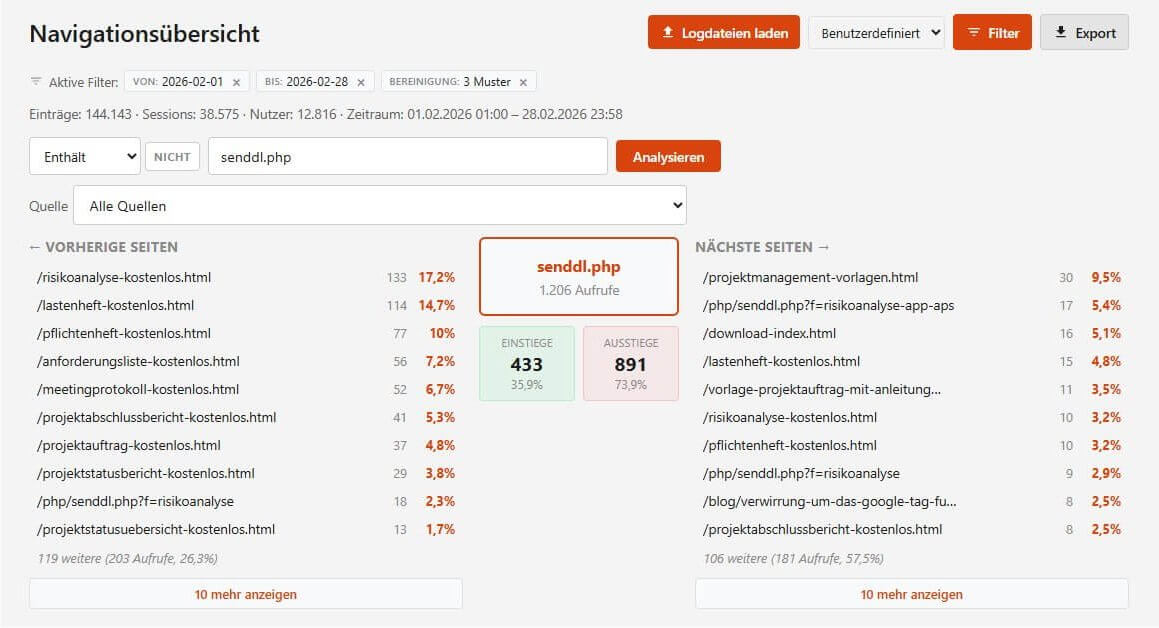
Dazu ein Quell-Dropdown, das die Analyse auf Sessions einer bestimmten Herkunft einschränkt. "Wie navigieren Google-Besucher durch meinen Blog?" ist damit eine Frage, die sich tatsächlich auch allein auf Basis von Logfiles und ohne Webanalse - Tool beantworten lässt. Und weil das Muster-Matching auch Wildcards versteht, lassen sich ganze Seitenbereiche analysieren - quasi "Content Groups light" 😉
Pfadübergänge
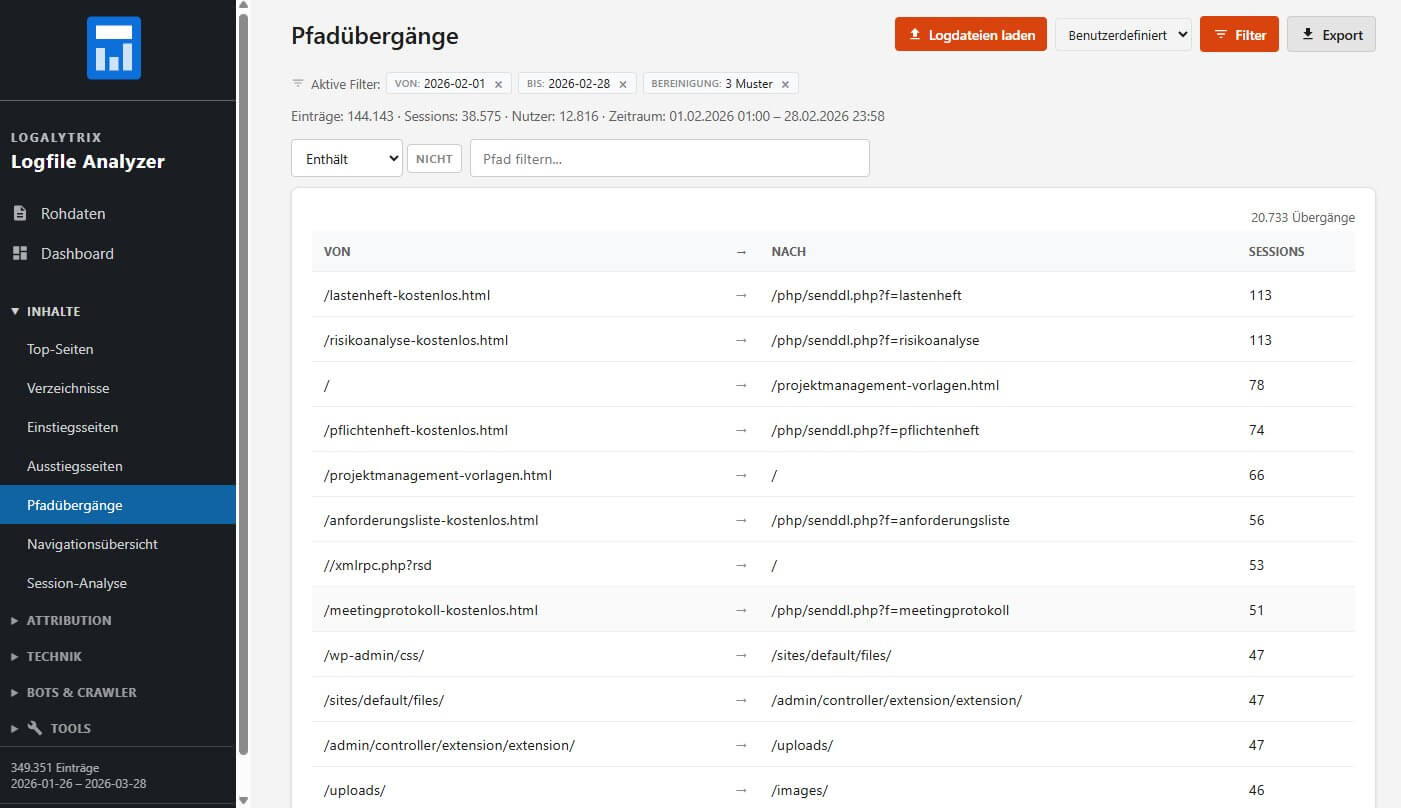
Die Pfadübergänge zeigen die häufigsten Seitenwechsel als "Von-Nach-Tabelle". Weniger visuell als die Navigationsübersicht, aber nützlich wenn man schnell sehen will, welche Seitenwechsel am häufigsten vorkommen - über die gesamte Website hinweg, nicht nur für eine einzelne Seite.
Jetzt wird´s wild: Quellen und Attribution
Wer weiß, woher Besucher kommen und welche Sessions zu einem Ziel führen, kann Attribution betreiben - die Zuordnung von Conversions zu Marketing-Kanälen. In Logalytrix geht das nach Vorbild von A.T.Z.E. und L.A.T.Z.E. ebenfalls.
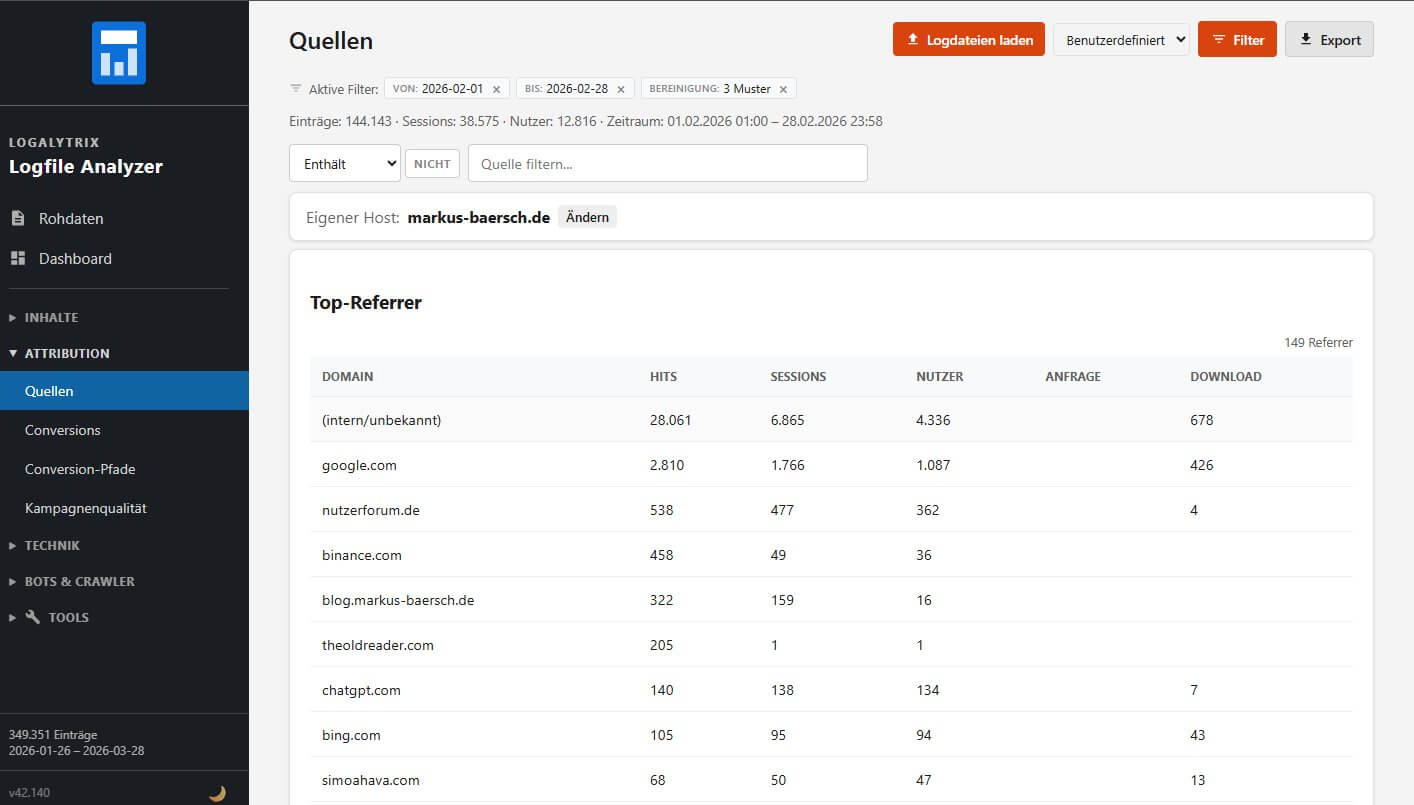
Die Quellen-View zeigt drei Bereiche: Top-Referrer für organischen Traffic, UTM-Kampagnen (ja mit mtm_xxx und pk_xxx auch Matomo- und Piwik-Varianten) und Eintritte, deren Quelle auf Basis von Click-IDs erkannt werden kann. Im Code stecken Parameter für Facebook Klicks und vor allem bezahlten Traffic (Plattformen wie Google Ads, Microsoft, TikTok etc.).
Conversions
Um den Quellen nach dem Eintritt (das "A" in A.T.Z.E.) auch ein "Z" zuzuordnen, können bis zu drei Conversion-Goals definiert werden.
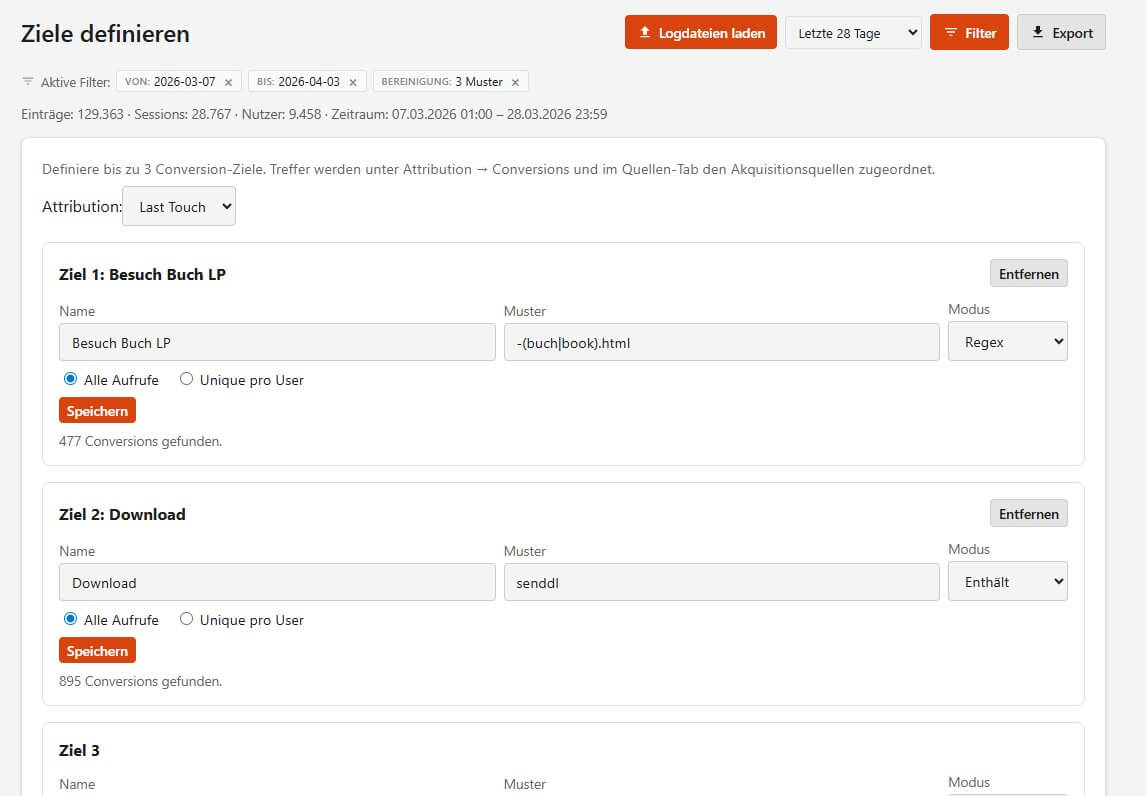
Neben dem Pfad-Muster gibt es sogar einen Zählmodus (alle Aufrufe oder einmalig pro Nutzer) und ein wählbares Attribution-Modell. Einfach weil es geht 😉 Nach Definition der Goals erscheinen automatisch Conversion-Spalten in den Referrer- und Kampagnen-Tabellen und es gibt Auswertungen, die sich explizit auf Conversions konzentrieren:
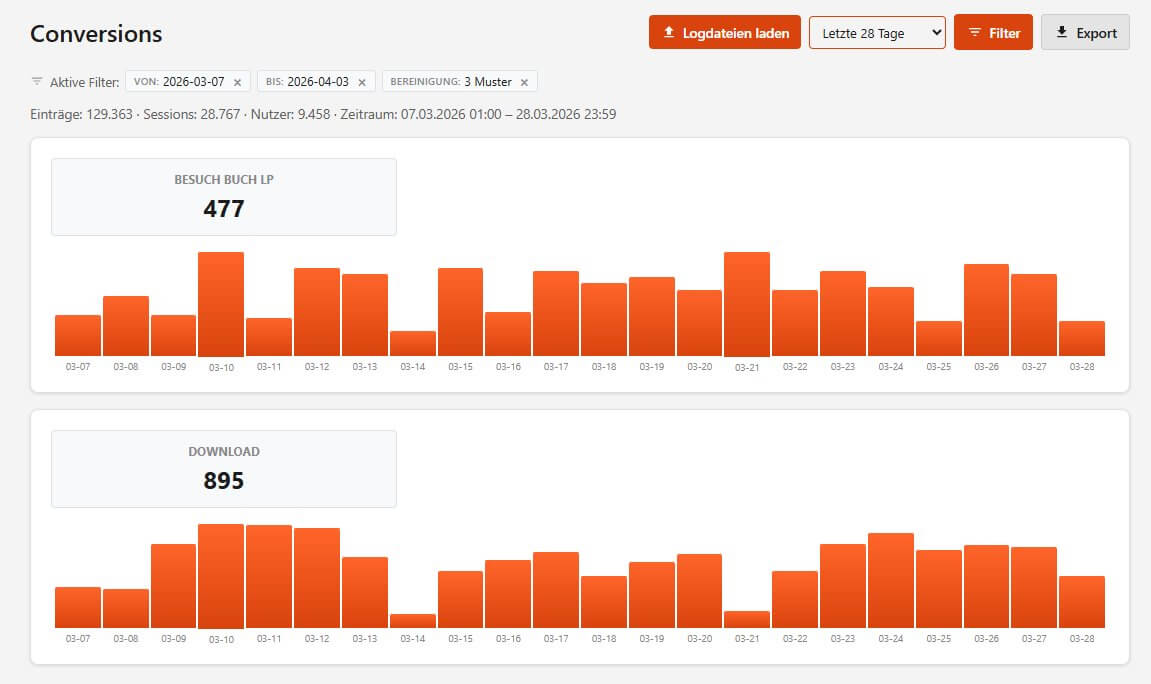
Ein eigener Report zeigt dazu Zeitreihen-Diagramme pro Goal. Die Conversion-Pfade-View filtert die Journey-Tabelle auf Pfade, die zu einer Conversion geführt haben - mit farbig hervorgehobenen Conversion-Schritten.
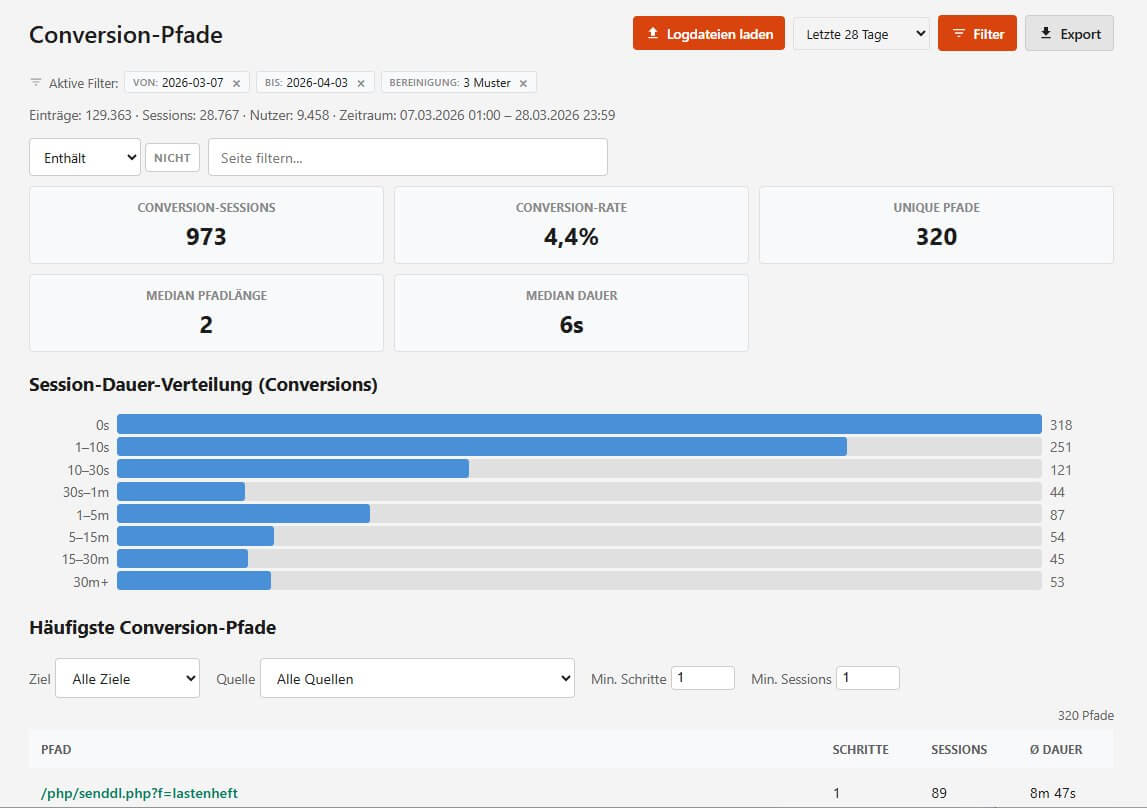
Über die Grenzen muss man ehrlich sprechen dürfen: Das Session-Modell auf IP-Basis ist rudimentär und auch hier gibt es keinen Ansatz für Cross-Device-Tracking oder andere Scherze. Ehrlicherweise ist das aber auch in den meisten echten Webanalyse Tools kaum gelöst, was schlichtweg an der Hartnäckigkeit der Realität liegt, sich den Wünschen von Marketern unterzuordnen. Die Attribution ist daher auch hier nur so gut wie die Daten im Log - wenn ein Referrer fehlt oder ein UTM-Parameter nicht gesetzt ist, gibt es keine Zuordnung. Dafür gibt es kein Sampling, keine Consent-Lücke, keine Modellierung. Jeder Request ist da, solange er im Umfang des Imports zu finden ist. Für viele Websites - gerade solche, die kein ausgefeiltes Tag-Management haben - ist eine solche grobe Attribution auf Log-Basis jederzeit besser als gar keine.
Bots und KI-Crawler
Von allen Themen, die Logalytrix adressiert, ist dieses vermutlich das aktuellste. KI-Crawler - GPTBot (OpenAI), ClaudeBot (Anthropic), Google-Extended, PerplexityBot, ByteSpider (ByteDance) und eine wachsende Liste weiterer - sind eine Bot-Gattung mit eigenem Verhalten, eigenen Zielen und eigenen Auswirkungen auf Websites. Sie tauchen aber leider kaum in der klassischen Web-Analyse auf, weil Web-Analyse-Tools Bot-Traffic in der Regel komplett ignorieren - selbst wenn diese tatsächlich die Seite besuchen, den Inhalt rendern, Cookies fressen, JavaScript ausführen und es am Consent Banner vorbei schaffen sollten. Und deshalb sind Logfiles ein prima Ansatzpunkt, diese Lücke zu schließen. Selbst wenn man keine Grounding Queries oder sonstwas sehen kann, sondern "nur" das, was der Bot auf dem Server angestellt hat.
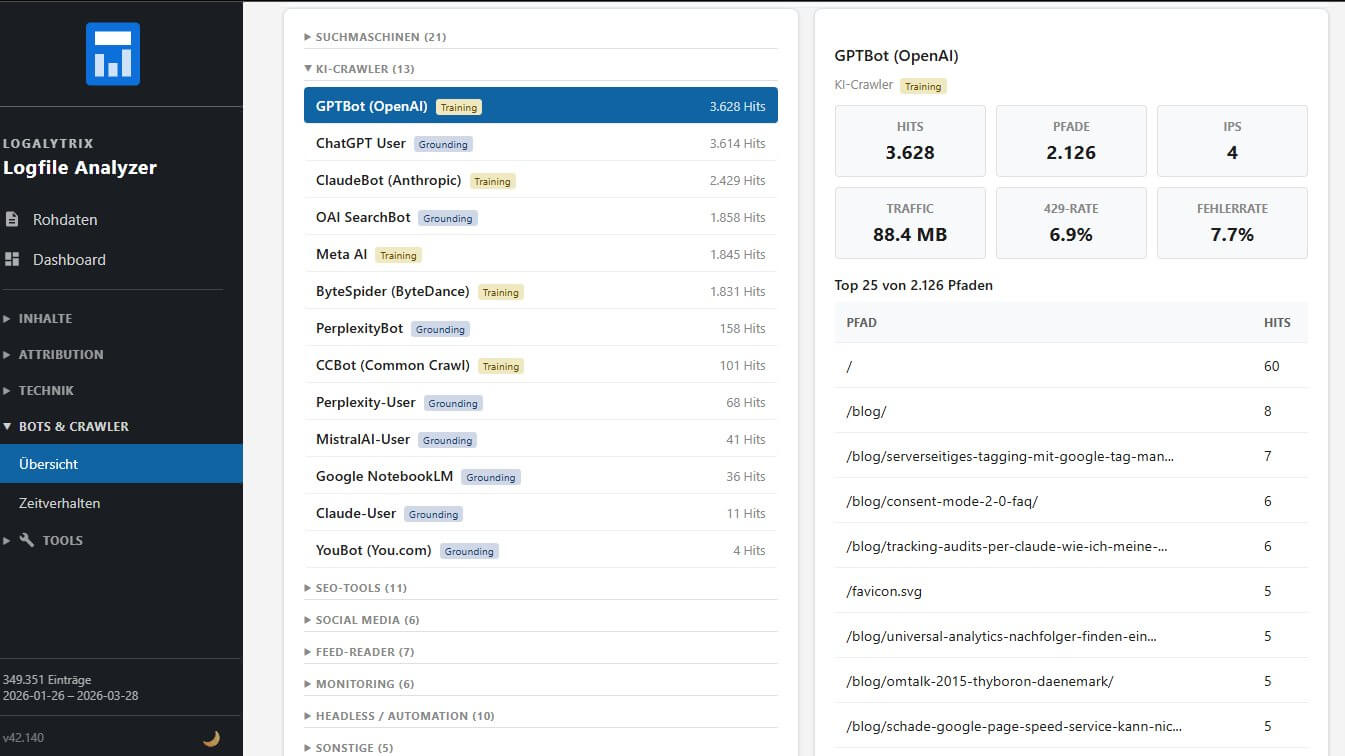
Logalytrix führt KI-Crawler daher als eigene Bot-Kategorie. Das ermöglicht gezielte Analysen: Wie viel Traffic erzeugen sie? Welche Seiten crawlen sie? Wie viel Bandwidth verbrauchen sie? Und - besonders interessant - wie reagiert der eigene Server?
Die Kategorie-Vergleichstabelle zeigt Kennzahlen pro Bot-Kategorie:
- 429-Rate. Meint: Limiting! Bei KI Bots sind ein echter Verhinderer da, wo sich ein LLM ausnahmsweise mal wirklich für Deinen Laden interessiert
- 408-Rate: Timeouts. Auch nicht schön, wenn der KI-Crawler nicht so viel Geduld hat wie der Google Bot 🙁
- Fehlerrate Allgemein
- Median und P95 der Response Time
Die Kernfrage dahinter lautet: Werden KI-Crawler durch den eigenen Server benachteiligt? Wenn GPTBot überwiegend 429-Antworten oder ungewöhnlich langsame Response Times bekommt, crawlt er die Seite nicht effektiv - und die eigenen Inhalte landen möglicherweise nicht in den Antworten von ChatGPT oder ähnlichen Assistenten. Das ist schon lange kein Nischenthema mehr. Die Frage, ob und wie die eigene Website in KI-Assistenten sichtbar ist, wird nur noch weiter an Relevanz gewinnen. Und die Antwort steckt - wer hätte das gedacht - zu einem guten Teil im Log.
Das betrifft natürlich nicht nur KI-Crawler. Auch alle anderen Kategorien von Bots lassen sich durch allgemeine Filter und View-Filter gezielt unter die Lupe nehmen. Wie hier z. B. das Zeitverhalten:
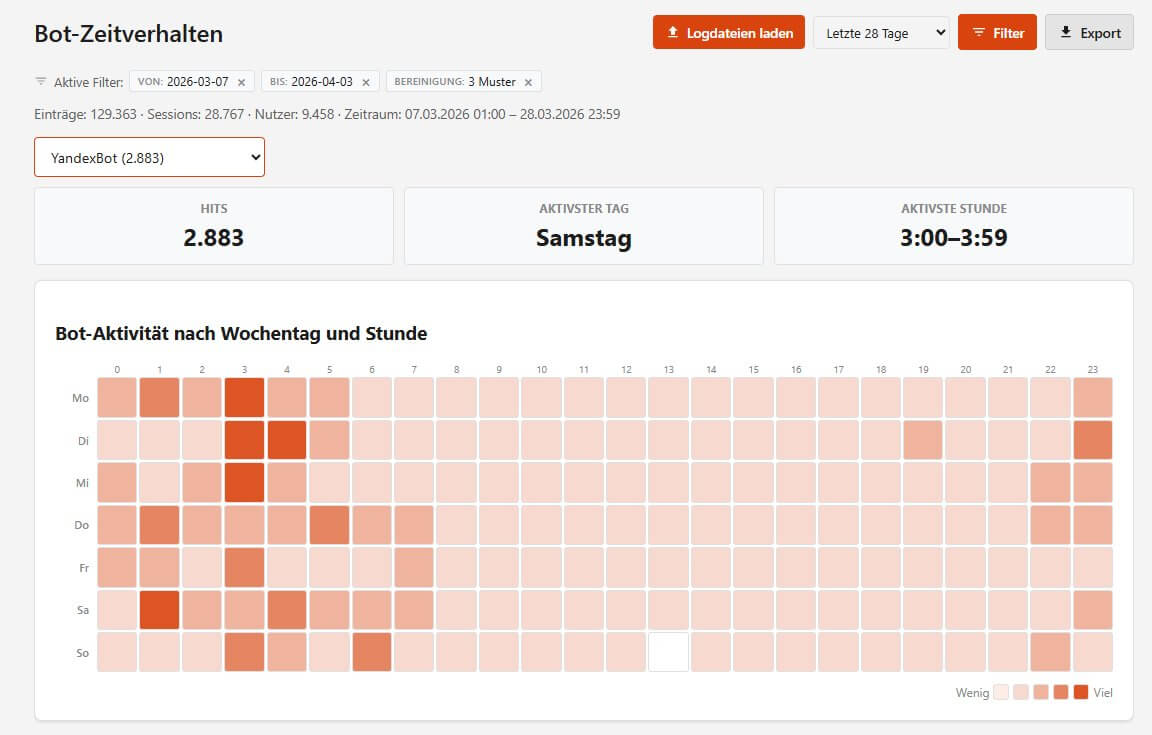
Diese "Bot-Heatmap" nach Wochentag und Stunde zeigt das Zeitverhalten einzelner - oder aller - Bots. Manche crawlen konstant, manche nur nachts, manche in Bursts. Ein Googlebot-Vergleich mit einem KI-Crawler kann aufschlussreich sein - und ist mit einem einfachen Dropdown-Wechsel erledigt, ohne die allgemeinen Filter bemühen zu müssen. Die Trennung von KI-Bots nach "Training vs. Grounding" erlaubt auch die klassenweise Betrachtung dieser und anderer Views.
Verdächtige IP Muster, nicht nur für Ads Kampagnen
Neben der grundsätzlichen Trennung von Browser, Bot und Angriff bietet Logalytrix zwei Werkzeuge, die tiefer in verdächtige Muster einsteigen.
IP-Auffälligkeiten
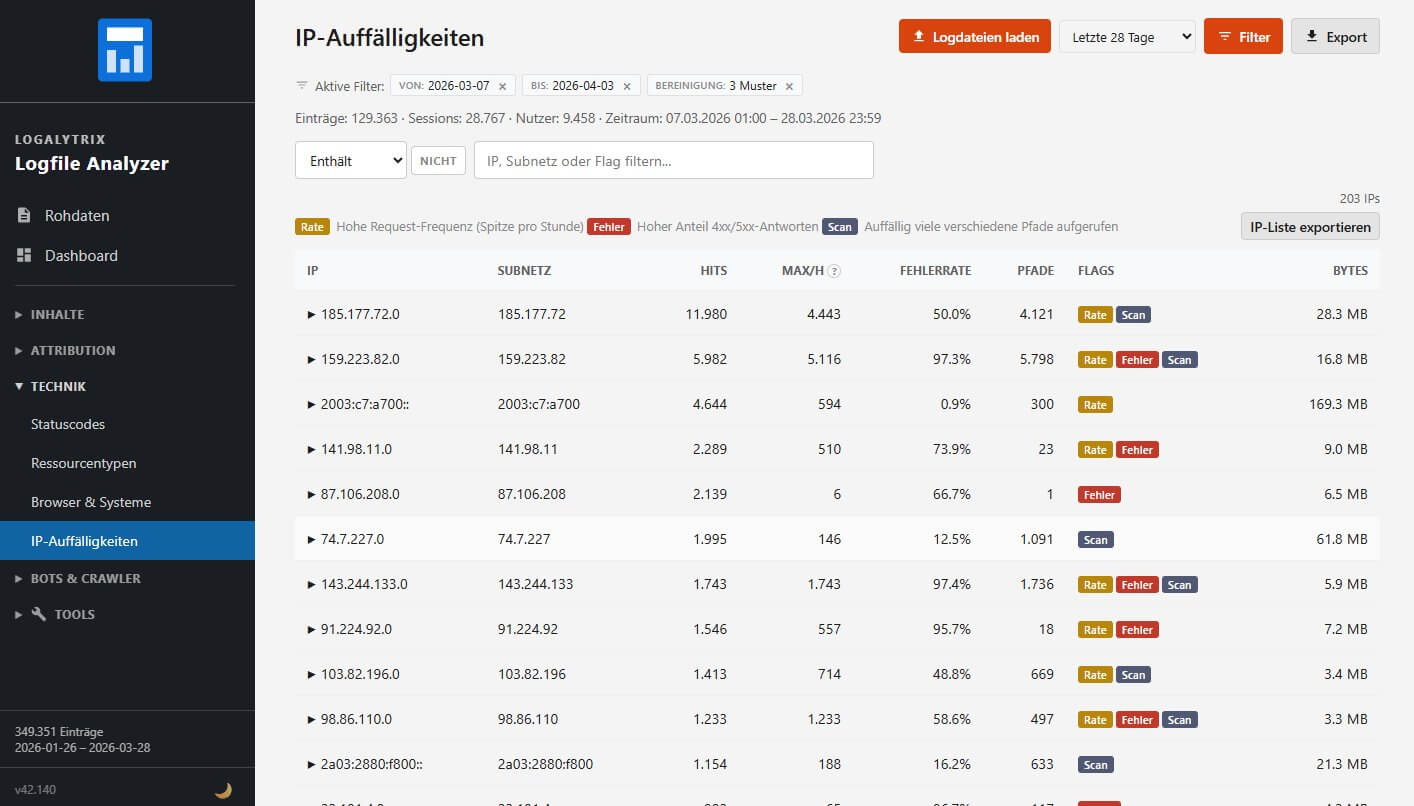
Die IP-Auffälligkeiten identifizieren IPs mit ungewöhnlichem Verhalten anhand statistischer Schwellenwerte (Median plus zwei Standardabweichungen) in drei Dimensionen:
- Request-Rate (ungewöhnlich viele Anfragen pro Stunde),
- Fehler-Anteil (überproportional viele 4xx/5xx-Antworten) und
- Scan-Verhalten (auffällig viele verschiedene Pfade).
Das Ergebnis ist keine klar definierte Blacklist, die man einfach bei Google zur Gutschrift von Ads Klicks einreicht, aber man sieht IPs, die eine genauere Betrachtung verdienen. Ein Klick zeigt Details, ein Export erzeugt eine Plain-Text-Datei mit einer IP pro Zeile - direkt einsetzbar für Firewall-Regeln oder fail2ban.
Kampagnenqualität
Die Kampagnenqualität adressiert die oben gestellte Frage nach der Qualität eingekaufter Besucher auf andere Weise. Es geht um eine Einschätzung, die mit Standard-Analyse-Tools kaum zu beantworten ist: Kommen die bezahlten Klicks von echten Menschen? Logalytrix clustert IPs nach /24-Subnetzen und sucht nach verschiedenen Signalen:
- Mehrere IPs aus demselben Subnetz mit Click-ID-Hits (Cluster),
- IPs deren Traffic zu über 80 Prozent aus Ad-Klicks besteht (Ad-dominiert), und
- IPs mit Click-ID-Hits an drei oder mehr verschiedenen Tagen (Wiederkehrend).
Das alles sind Indikatoren, keine harten Beweise. Denn Büro-Netzwerke, VPNs und Mobilfunk-NAT erzeugen ähnliche Muster. Aber ein Nachweis-Export als JSON-Datei liefert eine gute Grundlage, bei Google Ads oder Meta mit einer Gutschrift für verdächtige Klicks anzufragen.
SEO-Werkzeugkasten
Für SEO sind Logfiles seit jeher eine wichtige Datenquelle - aber eine, die "im kleinen Laden" kaum erschlossen wird. Daher versucht Logalytrix, auch hier die wichtigsten SEO-relevanten Auswertungen zu bündeln oder zumindest teilweise abzudecken. Ein paar Beispiele:
Crawl-Budget
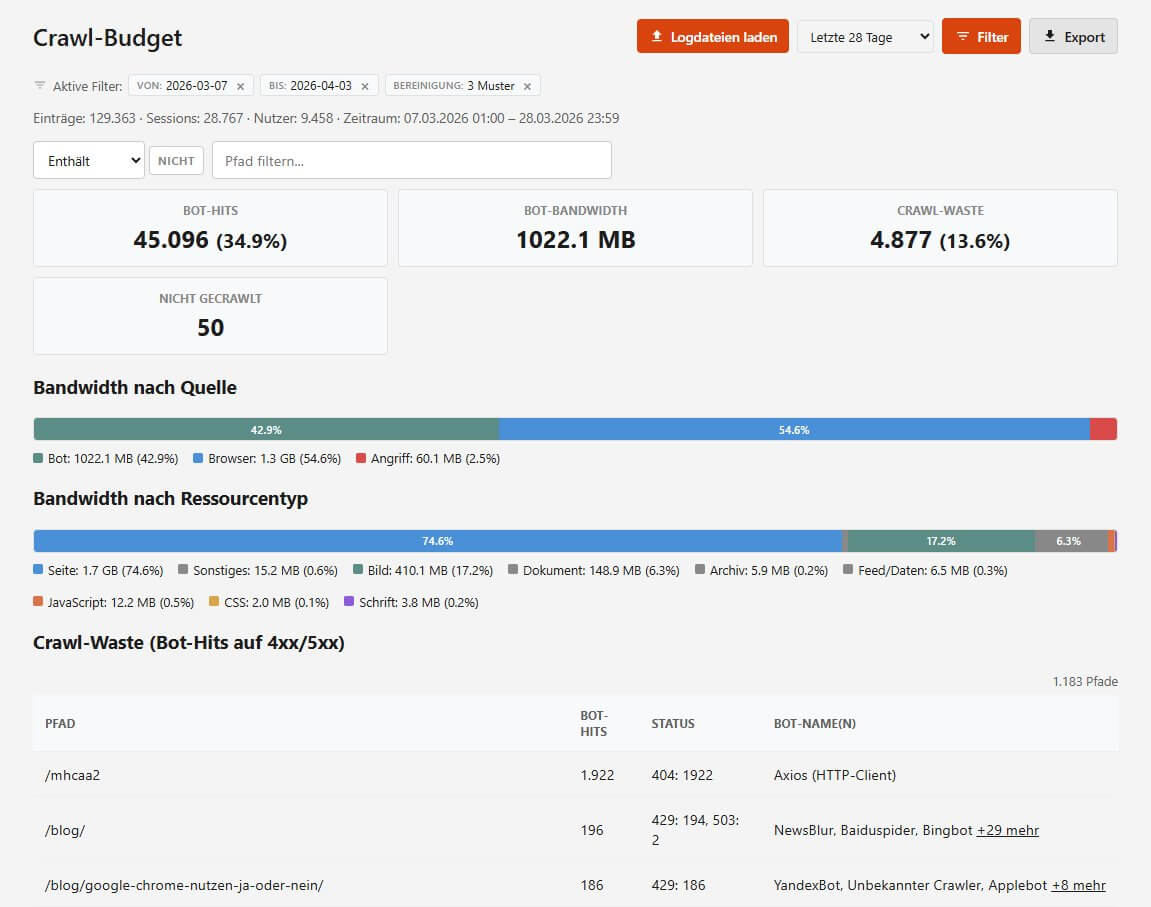
Die Crawl-Budget-Analyse zeigt Bot-Hits, Bot-Bandwidth, Crawl-Waste (Bot-Hits auf 4xx/5xx-Seiten, also verschwendete Crawler-Ressourcen) und Nicht-gecrawlt (Seiten mit echtem User-Traffic, die kein einziger Bot besucht hat). Letzteres ist besonders aufschlussreich, denn wenn eine Seite regelmäßig von Menschen aufgerufen wird, aber nie im Bot-Traffic auftaucht, gibt es möglicherweise ein Indexierungsproblem.
Bandwidth-Segmentbalken zeigen die Aufteilung nach Quelle (Bot, Browser, Angriff) und nach Ressourcentyp. Per Bot-Kategorie-Filter lässt sich zwischen Suchmaschinen und KI-Crawlern umschalten. So lassen sich Crawl-Budgets nicht nur für Googlebot, sondern eben auch für GPTBot etc. beobachten. Es ist davon auszugehen, dass die Bereitschaft zum Crawl nicht bei allen gleich hoch ist. Umso wichtiger, sich einen Eindruck vom Volumen zu machen... gerade da, wo es eben keine Webmaster-Tools gibt, die solche Zahlen von der anderen Seite aus anbieten.
Parameter
Ob für die Kanolikalisierung von Inhalten per Meta Tag oder den Ausschluss von Parametern in Google Analytics & Co. zur Konsolidierung / Defragmentierung von URLs: Transparenz über Anzahl und Volumen von Parametern ist oft wünschenswert. Nicht umspnst hat Analytrix einen eigenen Parametercheck für genau diesen Zweck. Folgerichtig ist diese Funktion in etwas anderer Form auch in Logalytrix gelandet.
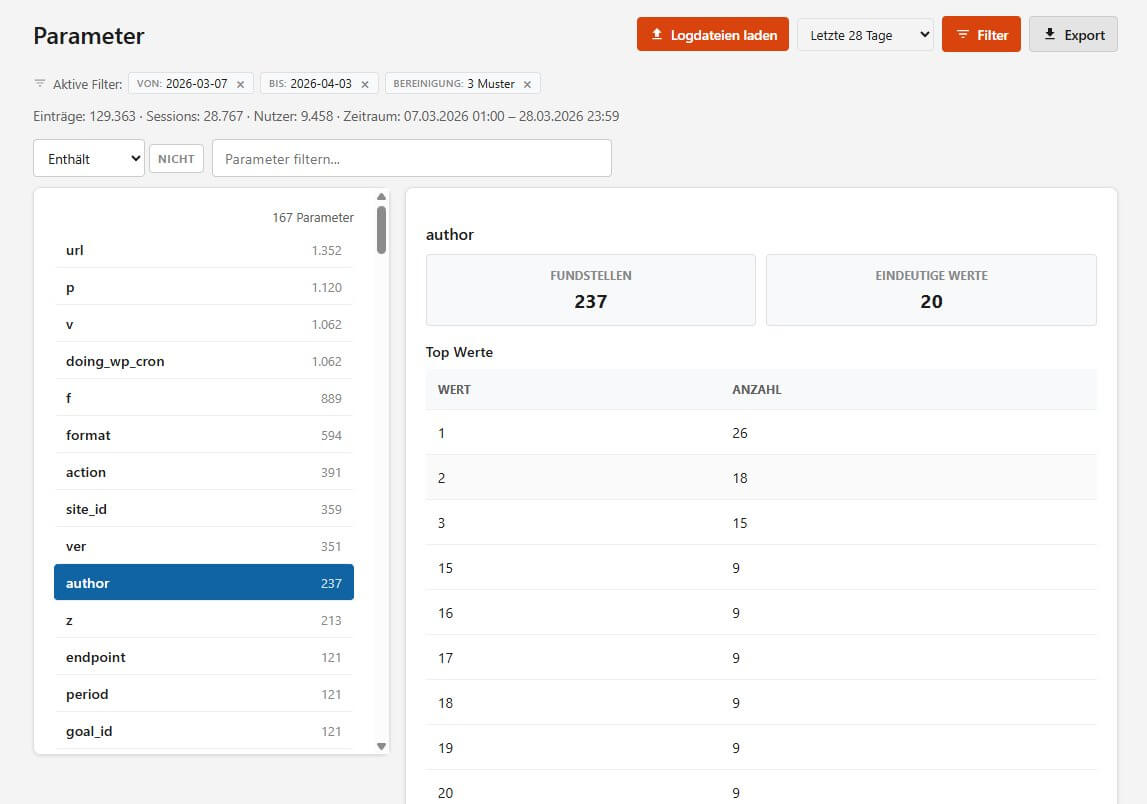
Überraschungen sind hier fast garantiert - von vergessenen Tracking-Parametern über Test-Parameter die nie entfernt wurden bis zu Parametern, die man schlicht nicht auf dem Schirm hatte. Aber im Log 😉
Hotlinking
Eher ein "Vollständigkeits-Feature" ist die Hotlinking-Erkennung. Sie zeigt externe Domains, die Bilder, Schriften oder andere statische Ressourcen direkt einbinden - inklusive Hits, Bytes und aufklappbarer Pfad-Details pro Domain. Nicht immer ein Problem, aber gut zu wissen. Und auch nicht immer perfekt (Position 2) oder "actionable" wie in diesem Beispiel Domains, die nur eine Weiterleitung auf die eigene Website ausliefern (Position 5).
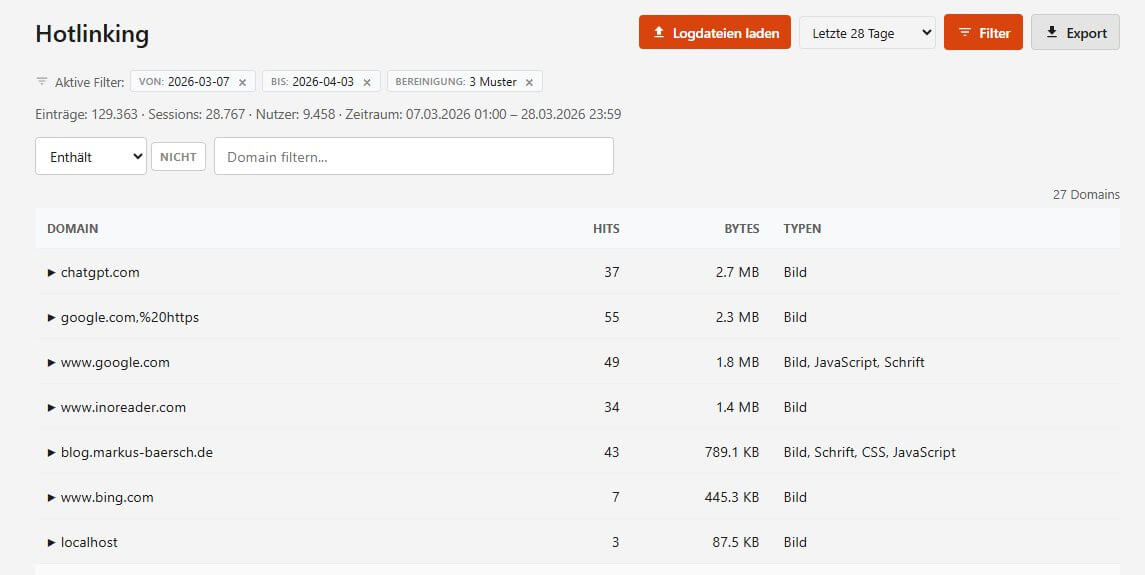
Organischer Traffic und 3xx ausgeblendet sieht das aber schon anders aus. Genau deshalb ist auch in Logalytrix so eine Funktion zu finden, auch wenn man sie nicht jeden Tag brauchen wird.
Für wen ist das?
Nach all diesen Features aus verschiedenen Bereichen stellt sich die Frage nach der Zielgruppe. Ganz ehrlich: Ich kann es auch nicht ganz beantworten. Denn ich war ursprünglich selbst die Zielgruppe. Logalytrix kann daher eine ganze Menge, ist aber natürlich kein Ersatz für GA4, kein Ersatz für den ELK Stack und auch kein Ersatz für eine Web Application Firewall. Aber dennoch nützlich; z. B. für Website-Betreiber, die wissen wollen, was auf ihrem Server passiert, ohne erst eine Pipeline aufzubauen. Für SEOs, die Crawl-Budget und Bot-Verhalten verstehen wollen, ohne ein Enterprise-Tool zu lizenzieren. Für Marketing-Analysten, die ihre Attribution mit einer zweiten Datenquelle validieren wollen - einer, die nicht vom Consent-Banner abhängt. Für Sicherheitsbewusste, die Angriffsmuster und verdächtige IPs früh erkennen wollen. Und für alle, die das Gefühl haben, dass in ihren Logfiles mehr steckt als die Balkendiagramme beim Hoster vermuten lassen. Also los jetzt!
Eine einfache HTML-Datei + keine Abhängigkeiten = keine Ausreden!
Logalytrix herunterladen, Logdatei rein, den Rest entscheiden Deine eigenen Fragen. Und wenn was fehlt: Schmeiß den Code in das LLM Deines Vertrauens und lass Dir die Funktion selbst bauen. Nur eine Bitte: Lass mich wissen, was Dir gefehlt hat. Vielleicht kann ich es auch gebrauchen 😉