06.05.2024
"Cookieless Future" - Eine Wegbeschreibung

Allerorts liest man von einer Zukunft ohne Kekse, was diese für “Dein Marketing bedeutet” und wie man dem Thema entkommt. Und zwar idealerweise, ohne sich des Problems oder der Rahmenbedingungen bewusst zu sein. Selbst wenn das Angebot verlockend klingt, halte ich den Ansatz für falsch. Ob Webanalyse, Marketingkanal-Erfolgskontrolle, Conversiontracking oder Aussteuerung von Kampagnen: Alle sind potenziell “irgendwie” betroffen vom (mal wieder verschobenen) Wegfall von Third-Party-Cookies in Chrome, Zustimmung bzw. Verwirrung um das, was man ohne diese nun kann oder darf. Angeboten werden zahlreiche Auswege aus der Notlage. Dieser Beitrag versucht sich an einem Überblick, um die wesentlichen Herausforderungen zunächst zu verstehen und die angebotenen Lösungsansätze damit einschätzen zu können. Denn wie so oft gilt auch hier: it depends 😉
Moment mal - gibt es nicht schon genug Beiträge zu diesem Thema?
Doch, natürlich schon. Vor allem der Beitrag bei Piwik PRO zum Third-Party-Wegfall ist erfrischend ausführlich und komplett. Dennoch glaube ich, dass einige der Punkte nur dann wirklich verständlich sind, wenn die im Kern steckenden Details bekannt sind. Dazu muss man nicht sehr tief in die Technik eintauchen, doch so ganz ohne kann m. E. keine Einschätzung möglicher Lösungsansätze erfolgen.
Anders ausgedrückt: Es bringt nichts, über den Wegfall von Third-Party-Cookies nachzudenken, ohne die wesentlichen Unterschiede zu verstehen, die es bei Cookies gibt und wie genau die Feinheiten ineinander greifen - sowohl bei Problemen als auch bei Lösungen. Wer im eigenen Hintergrundwissen solche Lücken befürchtet und diese gern füllen will, findet in diesem Beitrag das notwendige Material dazu.
Cookies: Eine Zweieinhalb-Klassen-Gesellschaft
Es hilft grundsätzlich zu wissen, dass ein Cookie einen Namen hat, unter dem ein Wert gespeichert wird. Man kann über diesen Namen auf den dort gespeicherten Wert zugreifen. Damit sind Cookies also nichts anderes als ein Datenspeicher im Browser. Verwirrenderweise kann man im Browser mehrere Cookies mit dem gleichen Namen, aber unterschiedlichen Werten haben, die je nachdem, wer danach fragt, mal zugänglich sind und mal nicht. Warum ist das so?
Cookies werden “von einer Domain” gesetzt und sind üblicherweise genau für diese Domain sichtbar, sei es der Server oder ein Script im Browser, welches auf einer Seite implementiert ist, die von dieser Domain ausgeliefert und betrachtet wird. Dabei kann der Zugriff entweder für alle Hosts einer Domain (www.beispiel.de, shop.beispiel.de, blog.beispiel.de etc.) oder nur einen einzelnen Host ermöglicht werden - oder nur bestimmte Pfade, so dass ein Cookie nur für Inhalte sichtbar ist, deren URLs in diesem Pfad liegen. Vereinfachend ist im Folgenden von “Domains” die Rede (also z. B. einer “First-Party-Domain”); gemeint sind streng genommen nur die jeweiligen Hosts oder Inhalte in bestimmten Pfaden, wenn die o. A. Einschränkungen gelten.
Den Unterschied zwischen First- und Third-Party-Cookies bestimmt die Domain, die gerade im Browser betrachtet wird. Das bedeutet, dass First-Party-Cookies im Kontext der besuchten Domain entstehen und sichtbar sind, während Third-Party-Cookies von anderen Domains stammen, zu denen der Browser beim Besuch der aktuellen Seite ebenfalls eine Verbindung aufbaut. Beispiele für beide Fälle finden sich weiter unten. Was bedeutet das in der Praxis? Eine für Analyse- und Marketingzwecke taugliche Antwort braucht mehrere Perspektiven:
Perspektive 1: Wer kann ein Cookie erzeugen?
Cookies können grundsätzlich auf zwei Arten entstehen:
- Der Server sendet ein Cookie mit Angaben für die oben beschriebene Sichtbarkeit, gewünschter Lebensdauer und andere Parameter in einer Antwort an einen Browser, welcher zuvor eine Anfrage an diesen Server gestellt hat. Das war in den Urzeiten des Internets die einzige Methode, ein Cookie zu erzeugen.Alle weiteren Anfragen an den gleichen Server beinhalten (als “Cookie-Header”) alle Cookie Werte, die für den aktuellen Host und Pfad sichtbar sind.Vereinfacht ausgedrückt kann ein Server also Cookies in der Antwort auf eine Anfrage (“zeige mir Seite xyz”) setzen und erhält deren Wert bei allen späteren Anfragen (“lade nun danach Seite abc”) erneut zugesendet. Damit dienen Cookies als ein einfaches Mittel zur Speicherung von Daten zwischen Anfragen / Seitenaufrufen. Die Informationen können je nach Laufzeit noch nach Stunden, Tagen oder Monaten noch verfügbar sein. Sinnvolle Beispiele sind der Anmelde-Status, die getroffene Auswahl für eine Inhaltssprache auf mehrsprachigen Sites oder Ähnliches. Schreibt ein Server ein Cookie als Antwort auf einen Request im Rahmen des HTTP-Verkehrs zwischen Server und Browser, nennt man es daher auch “HTTP-Cookie”.
- Cookies können alternativ per JavaScript direkt im Browser erzeugt werden. Dabei hat ein Script mehr oder weniger die gleichen Möglichkeiten wie der Server selbst, wenn es um die Gestaltung der Sichtbarkeit, Laufzeit etc. geht. Theoretisch ist ein solches Cookie also gleichwertig. Dennoch unterscheidet der moderne Browser zwischen HTTP-Cookies und solchen “Javascript-Cookies” und behandelt beide unterschiedlich. Warum wird klarer, wenn die zweite Perspektive dazu kommt:
Perspektive 2: Wer kann ein Cookie lesen?
First Party Cookies sind nur “sichtbar” für die Domain, die gerade im Browser besucht wird. Sie entstehen im Kontext der besuchten Seite, also der Antwort der “First Party”, an die der besuchende Browser (oder andere Geräte) eine Anfrage gesendet hat, um die gewünschten Inhalte zu laden und anzuzeigen. Entweder als HTTP Cookie in der Antwort des Servers oder direkt im Browser per JavaScript, welches ebenfalls im “First-Party-Kontext” agiert (unabhängig von seiner Herkunft), solange es “auf der aktuell besuchten Seite” ausgeführt wird.
Das bedeutet im Browser wie oben beschrieben, dass die in Cookies gespeicherten Informationen bei weiteren Anfragen an diesen Host übertragen werden. Der empfangende Server sieht diese Werte und kann sie lesen bzw. nutzen, um beispielsweise eine vorher in diesem Browser gewählte Sprache auf Folgeseiten beizubehalten.
Der “besuchte” Server ist aber nicht der einzige Nutzer von Cookie-Werten. Üblicherweise kann jedes Script (meint: beliebiger Javascript Code), welches Teil der besuchten Seite ist (als nachgeladenes Script oder Code innerhalb der Seite), diese Werte ebenfalls lesen, weil es “im First Party Kontext” agiert. Das stimmt zwar nicht für httpOnly-Cookies, aber dazu erst später mehr.
Beispiel für First-Party-Cookie Sichtbarkeit
Die URL meinedomain.de/shop/kategorie1/ wird im Browser aufgerufen. Ein First-Party-Cookie namens “cookie_x” mit dem Wert “ABC” aus einem vorherigen Besuch ist vorhanden, welches für meinedomain.de sichtbar ist. Dieses Cookie wird bei der Anfrage zum Abruf der gewünschten Seite an den Server übertragen. Er kann diesen Wert also lesen, darauf reagieren und bei Bedarf in der Antwort mit einem neuen Wert für spätere Anfragen versehen.
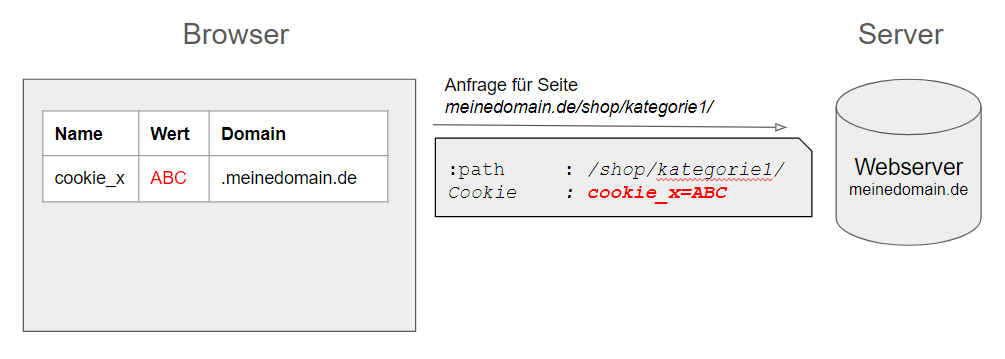
Abbildung 1: Cookies in Serveranfragen
Der Server antwortet mit dem Inhalt der Seite. Wenn nun ein auf dieser Seite eingebundenes Script extern,js von drittpartei.com vom Browser geladen wird, kann das Script im Browser den Wert “ABC” aus dem Cookie durchaus lesen, nutzen und ggf. ändern.
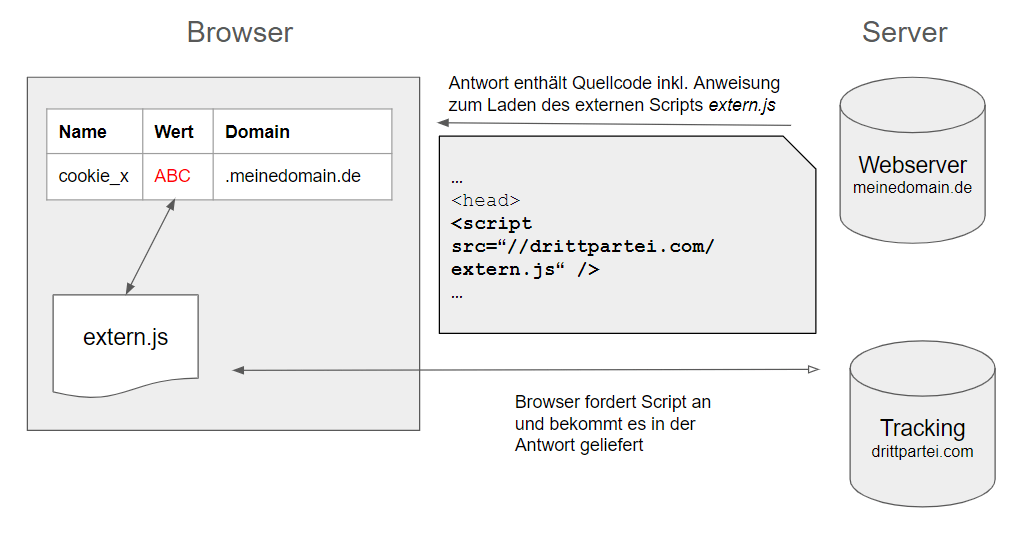
Abbildung 2: Externes Script wird geladen
Der einzige Unterschied aus Sicht des Servers von drittpartei.com ist, dass dieses Cookie nicht bei der Anfrage des Servers zum Abruf des externen Scripts extern.js mitgesendet wurde.
Der Code des Scripts kann aber jederzeit den Wert einsehen und in einer weiteren Anfrage an den Server (z. B. als Parameter oder Teil der Nutzlast) mitsenden. Ebenso kann ein solches Script ein eigenes First-Party-Cookie “cookie_y” im Browser erstellen. Da es im Kontext der besuchten Seite agiert, kann es die gleiche Sichtbarkeit haben, also für den gleichen Host oder die Domain angelegt werden.

Abbildung 3: Bildung und Weitergabe von First-Party-IDs an Drittpartei
Das passiert z. B. typischerweise bei Tracking-Codes für Google Analytics oder andere Webanalyse Systeme. Die meisten Systeme arbeiten seit vielen Jahren ausschließlich oder wenigstens ergänzend mit First-Party-Cookies, welche vom Tracking-Script erstellt werden und deren Wert (da der Tracking-Server diese nicht direkt in Anfragen enthält) in späteren Tracking-Anfragen aktiv mitgesendet werden. Das kann z. B. ein Identifier sein, mit dem der Browser zwischen einzelnen Anfragen oder sitzungsübergreifend wiedererkannt werden kann.
Ein Cookie kann zusammengefasst dann vom Server gelesen und geschrieben werden, wenn Kommunikation zwischen Browser und Server der zugehörigen stattfindet. Ebenso kann im Browser ein Cookie per Script erstellt oder be- / verarbeitet werden, wenn dort gerade eine Seite der jeweiligen Domain zu sehen ist.
Eine Ausnahme bilden HTTP-Cookies, die mit einem speziellen Merkmal (“httpOnly”) versehen sind. Darüber wird gesteuert, dass der Wert nur für den setzenden Server sichtbar ist (als Teil des HTTP Verkehrs), aber mit JavaScript nicht gelesen oder geändert werden kann. Wäre cookie_x im obigen Beispiel mit diesem Merkmal versehen, würde nur der Server meinedomain.de Zugang dazu haben, aber extern.js das Cookie und dessen Wert nicht sehen oder an den Trackingserver drittpartei.com übergeben können. Das macht solche Cookies “sicherer”, was einige Browser zum Anlass nehmen, weniger restriktiv damit umzugehen als mit anderen Cookies (siehe Perspektive 3).
Die Rolle von Third-Party-Cookies
Was genau Third-Party-Cookies sind, erklären sich damit fast von selbst. Es sind Cookies, die durch die Serverantwort eines Drittservers per “Set-Cookie” Header erzeugt werden sollen. Sie wären damit nur für diese Domain “sichtbar”. Das kann passieren, wenn man beliebige Ressourcen von einer anderen Domain (wie drittpartei.com) lädt bzw. Anfragen dorthin sendet (wie im Fall eines Tracking-Scripts). Die Antwort sendet ein Cookie, das der anderen Domain “gehört” (also aus deren Sicht in gewisser Weise ein First-Party-Cookie darstellt.
Wenn ein Browser aktuell eine Seite einer anderen Domain (meinedomain.de) als derjenigen anzeigt, die das Cookie setzen will, weigert er sich üblicherweise, diese zu akzeptieren. Nur Chrome macht hier bisher noch eine Ausnahme, alle anderen Browser sind längst durch mit Third-Party-Cookies. Dennoch spielen diese durch den großen Marktanteil von Chrome immer noch eine Rolle.
Ein JavaScript, das auf einer Seite von meinedomain.de ausgeführt wird, könnte dieses Cookie hingegen nicht sehen. Ein Script, das im Kontext des Drittservers läuft (z. B. in einem iFrame) aber schon. Und der Drittserver bekommt es ebenso im Header jeder Anfrage gesendet - solange es solche Cookies noch gibt.
Im obigen Beispiel kann - solange es Third-Party-Cookies gibt - bei einer Verbindung zu drittpartei.com ein Cookie “cookie_z” gesetzt werden, dessen Wert stets übertragen wird, wenn eine weitere Verbindung zu drittpartei.com aufgebaut wird. Dieses Cookie ist allerdings wie beschrieben für den First-Party-Kontext im Browser und den Server von meinedomain.de nicht zugänglich.
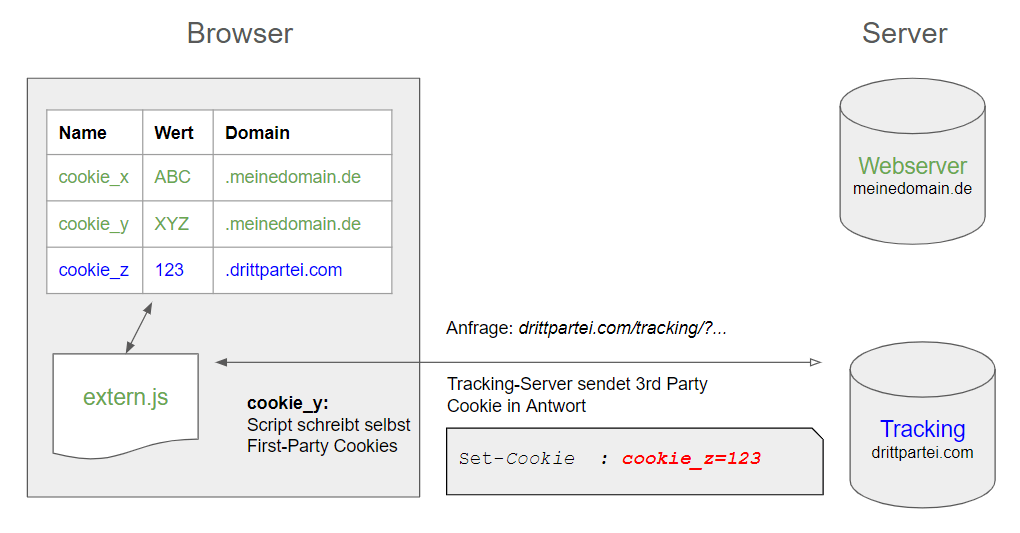
Abbildung 4: Entstehung von Third-Party Cookies
- Grün: First-Party Cookies können vom besuchten Webserver und dem externen Script “in” der angezeigten Seite gesehen werden
- Blau: das Third-Party-Cookie stammt aus der Serverantwort und ist nur für den Tracking-Server sichtbar. Es ist hier durch einen Tracking-Aufruf entstanden, hätte aber bereits vorher beim Abruf des externen Scripts in der Antwort des Tracking-Servers stecken können.
Jeder weitere Aufruf, der an den Tracking-Server gesendet wird, würde dieses Cookie als Referenz mitbringen. In der Realität sieht der Vorgang oft etwas anders aus, doch das Prinzip bleibt das Gleiche. Ob vorher mit einem testCookie und einer Kette an Weiterleitungen die Bereitschaft des Browsers überprüft wird, ob ein Wert darin überlebt oder nicht oder welche Requests dabei im Spiel sind, macht keinen wirklichen Unterschied. Das IDE Cookie von doubleclick.net nimmt z. B. den hier beschriebenen Werdegang.
Wie Third-Party-Cookies Tracking ermöglichen
Das Ganze wird zum Problem, wenn ein Browser, nachdem darin meinedomain.de aufgerufen wurde und dort das Third-Party-Cookie “cookie_z” entstanden ist, eine weitere Domain einblog.net aufruft und dort ebenso eine Verbindung zu drittpartei.com entsteht, weil dort z. B. das gleiche Script “extern.js” eingebunden ist (und damit abgerufen wird) oder ein iFrame von drittpartei.com geladen wird.
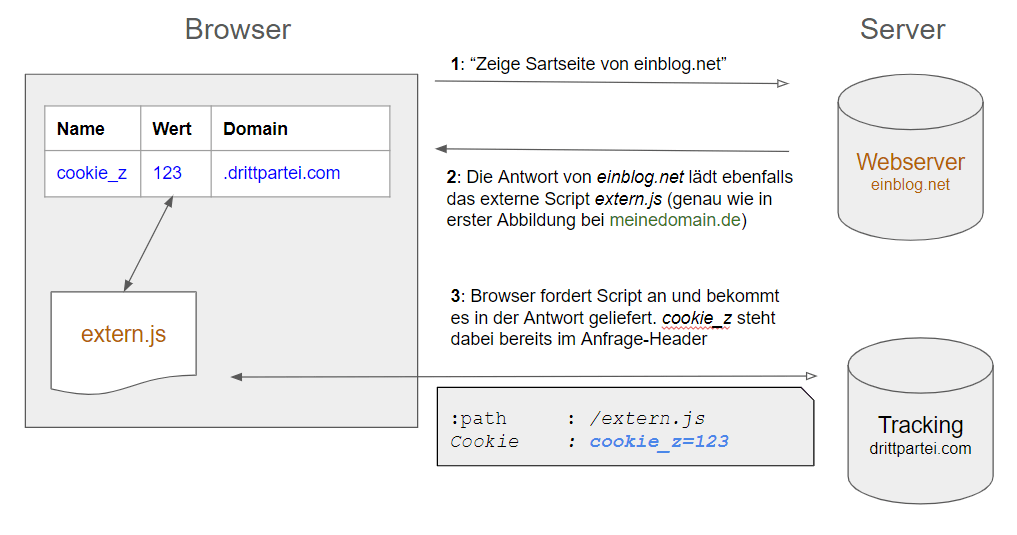
Abbildung 5: Nutzung von Third-Party-ID zur Wiedererkennung durch Dritte
Der Server von drittpartei.com kann so den Besuch auf der einen Domain mit dem vorherigen Besuch auf der anderen verbinden und entsprechend agieren. Das kann das Zusammenführen von Daten aus beiden Besuchen sein (“Cross-Domain-Tracking”) oder Daten aus dem vorherigen Besuch auf einer einen Domain beeinflussen das Verhalten der anschließend besuchten anderen Website.
Dies ist zum Beispiel dann der Fall, wenn auf Domain 1 ein Produkt betrachtet wird und diese Information an Dienst A gesendet wurde, der per Script bei einem späteren Besuch auf Domain 2 erfolgreich für einen Anzeigenplatz geboten hat und dort mit der Information von Domain 1 eine passende Retargeting-Anzeige ausspielt, die das Produkt von Domain 1 nun auf Domain 2 bewirbt.
Third-Party-Cookies “folgen uns” also mehr oder weniger durch das Web, wenn diese von Werbe- und Trackingdiensten gesetzt werden und ermöglichen all die Dinge, die aus Sicht des Datenschutzes kritisch sind: Zielgruppen- und Profilbildung, personalisierte Werbung, besucherbezogenes Zählen der Ausspielungen von Werbeanzeigen… und alle anderen Vorgänge, die etwas mit dem Zusammenführen von Informationen über mehrere Domains hinweg zu tun haben. Genau deshalb stehen diese Cookies im Fokus des Datenschutzes. Für die Vermessung von Besucherverhalten auf einer einzelnen Website und viele andere Zwecke sind sie hingegen nicht erforderlich.
Perspektive 3: Was sagt der Browser?
Mit zunehmender Härte gehen Browser aktiv gegen Cookies und deren potenzieller Nutzung für “Tracking” im weitesten Sinne vor (siehe Beitrag zum Trackingschutz). “Tracking” steht hier in Anführungszeichen, weil es einen feinen Unterschied zu reinem “Measurement” gibt: Solange ein Cookie wirklich von der “First-Party” stammt und möglichst kein anderer Server in die digitalen Finger bekommt, sind viele Schutzmaßnahmen deutlich großzügiger, als bei anderen Cookies.
Kurz gesagt: Der Wegfall von Third-Party-Cookies ist eine Herausforderung für das Marketing (Fokus: “Tracking”), nicht für die Webanalyse (Fokus: “Measurement”).
Das hat im Lauf der Zeit dafür gesorgt, dass nicht jedes First-Party-Cookie wirklich als solches betrachtet wird. So ist inzwischen faktisch als Zwischending ein First-Party-Cookie “zweiter Klasse” entstanden.
Um diese Zwischenklasse zu bevölkern, wurde anfangs zwischen JavaScript-Cookies (zur Erinnerung: Jedes beliebige Script aus jeder Quelle kann es im First Party Kontext setzen, wenn es im Browser aktiv ist) und First-Party-HTTP-Cookies des besuchten Servers unterschieden. Inzwischen stehen selbst solche HTTP Cookies unter Verdacht, die auf den zweiten Blick unter Kontrolle einer Drittpartei stehen könnten. Ein Merkmal dafür kann z. B. sein, dass die IP-Adressen eines beteiligten Servers (wie einem server-side Google Tag Manager oder Proxy eines Tracking-Dienstes) und der Quelle der besuchten Seite deutlich voneinander abweichen.
Der Grund dafür sind die seither gängigen Ausweichmöglichkeiten, mit denen man sich als Drittpartei aus der Problemlage zu befreien versucht hat.
- Ein Trackingdienst will z. B. per CNAME Weiterleitung über einen First-Party-Hostnamen wie “tracking.meinedomain.de” erreichbar werden. Moderne Browser betrachten allerdings alle in diesem Szenario entstehenden Cookies aus dieser Quelle als von einer Drittpartei stammend und beschränken daher deren Lebensdauer, verweigern das Speichern im Browser komplett oder erschweren die Wiedererkennung beim Abruf über eine andere Domain durch Partitionierung. Dieser Begriff bedeutet, dass je Nutzungskontext mehrere Versionen des gleichen Cookies entstehen, die jeweils andere Werte enthalten, so dass keine Wiedererkennung über mehrere Sites hinweg möglich ist.
- Eine DNS Weiterleitung, wie es im Fall eines server-side Google Tag Manager lange Zeit üblich war, um den Trackingserver aus der Cloud in den eigenen First-Party-Kontext zu holen, reicht heute nicht mehr in jedem Fall aus, um “harte” Cookies zu schreiben.
Dabei wird nicht Halt gemacht vor alternativen Speicherformen wie localStorage etc. Selbst Klick-IDs als Parameter wie bspw. gclid, welcher beim Klick auf eine Anzeige bei Google entsteht, werden ggf. komplett aus der Adresse der Seite entfernt, bevor ein Script diese lesen und in einem Cookie speichern kann.
Auf diese Weise ist vor Jahren ein Katz-und-Maus-Spiel zwischen Tracking- und Browser-Anbietern entstanden, das auch First-Party-Cookies ein schweres Leben beschert. Mehrere Jahre lange Laufzeiten sind daher generell für alle Cookies längst passé. Die Regelwerke der unterschiedlichen Browser sind durchaus heterogen, haben aber alle das gleiche Ziel: Tracking verhindern.
Perspektive 4: Wozu dient ein Cookie?
Bei allem notwendigem Technik-Hintergrund spielt ein ganz anderes Duo die Hauptrolle im Gewirr um Cookies: Regulierung und Datenschutz. Datenschutzrichtlinien wie ePrivacy und lokale rechtliche Umsetzungen wie das deutsche TTDSG erfordern Zustimmung für die meisten Vorgänge, die etwas mit dem Speichern oder Lesen von Informationen auf Geräten zu tun haben. Verordnungen wie die DSGVO und ihre internationalen Geschwister haben die Spielregeln ebenfalls deutlich verändert.
Mit einigen Ausnahmen, die als “funktional” eingestuft werden, Cookies für Consent-Tools und Dienste, die ausschließlich dem Schutz vor Betrug, Bot-Erkennung usw. dienen, braucht man im Ergebnis i. d. R. Zustimmung, bevor Cookies gesetzt werden dürfen. Betroffen sind auch alle anderen Speicherformen wie localStorage, sessionStorage und IndexedDB. Sämtliche weiteren “Tricks”, mit denen man diese Regelungen ggf. umgehen will, bieten keinen belastbaren Ausweg.
Ein Unterschied zwischen sessionStorage und einem Session-Cookie besteht aus dieser Perspektive also nicht. Was nicht bedeutet, dass alternative Speicherformen nicht datenschutzfreundlicher sind im Vergleich mit Cookies. Während Cookie-Werte wie oben beschrieben Teil des normalen HTTP-Verkehrs zwischen Browser und Server sind, kann ein Wert im localStorage nur aktiv per Script ausgelesen und dann an einen Server gesendet werden. Er steht zudem anderen Hosts als der aktuellen “First-Party” nicht zur Verfügung.
Da das Datenschutzrecht keinen Unterschied zwischen diesen Mitteln macht, mag das eine weniger kritisch sein als das andere - im Endeffekt müssen dennoch stets die gleichen Regeln beachtet werden. Eine der wichtigsten, die im Zusammenhang mit Ausweichtaktiken zu beachten ist, ist die Zweckbindung der gespeicherten Information.
Bindung an Zwecke
Ein praktisches Beispiel sind eigentlich “unkritische” gespeicherte Daten, die technisch erforderlich sein mögen. Eine PHP Session ID in einem Cookie - oder ein Identifier in einem localStorage Eintrag einer Consent Management Platform haben aber einen dedizierten Zweck. Selbst wenn solche IDs vorhanden sind und im Rahmen des HTTP Verkehrs den Server erreichen, können sie also nicht in einem anderen Nutzungskontext wie der Vermessung der Websitenutzung zur Webanalyse verwendet werden.
Ist ein Cookie als funktional erforderlich einzustufen und wird Zustimmung zur Statistik als Kategorie bzw. Nutzung eines bestimmten Tools verweigert oder wurde noch nicht erzielt, sind solche IDs also kein Ausweg aus der Misere.
Cookieless? Nope!
Wie man sieht, sind (viele) First-Party-Cookies dennoch nach wie vor ein wesentlicher Bestandteil des Internets und werden eine ganze Zeit noch bestehen (müssen), damit es weiterhin funktioniert. Die Lebensdauer und Sichtbarkeit mag aber eingeschränkt sein.
Daher fragt eine Website nach längerer Abwesenheit auch heute schon ggf. erneut nach Zustimmung oder erfordert gelegentlich eine neue Anmeldung. Doch wenn es um Webanalyse und zeitlich befristete Wiedererkennung von Browsern zwischen zwei Seitenaufrufen geht, ist man selbst nach dem Wegfall von Third-Party-Cookies im Browser nicht verloren.
Viel wesentlicher ist die Notwendigkeit, vor der Nutzung (sei es Speichern neuer oder Lesen vorhandener Informationen) nach Zustimmung zu fragen. Dazu kommt die Tatsache, dass alles, was nach Zustimmung in einem Cookie gespeichert wird, durch Trackingschutzmaßnahmen nicht zwingend zuverlässig gespeichert wird und so noch da ist, wenn man darauf zugreifen will. Diese Rahmenbedingungen sind alles andere als neu, nur haben sich die Grenzen in den letzten Jahren bewegt und verfügbaren Spielraum immer weiter eingegrenzt.
Durch die Erforderlichkeit von Zustimmung ist vor allem für das Marketing bereits seit einiger Zeit “cookieless” ganz normale Realität - je nach Zustimmungsrate für einen Großteil aller Besuche auf der Website.
Genau hier fängt nun (endlich) das eigentliche Thema der “Cookieless Future” an - und die damit einhergehenden Probleme und Lösungen.
Probleme durch Wegfall der Third-Party-Cookies
Mit den Informationen aus der umfangreichen Einleitung fällt die Abschätzung der Probleme hoffentlich leichter, wenn es um Third-Party-Cookies geht. Sie beschränken sich im Wesentlichen auf die Wiedererkennung von Nutzern bzw. Browsern und den auf einer Domain gesammelten Daten durch einen Trackingdienst auf anderen Domains.
Im First-Party Kontext auf einer Website und einem exemplarischen Werbesystem “Beispiel Social Ads” ist nicht alles verloren.
Conversiontracking mit First-Party-Cookies
Betrachtet wird der Besuch auf einer Website nach einem Klick auf einen Link in einer Anzeige oder einem organischen Beitrag auf der hypothetischen Social- und Werbe-Plattform “Horst” (grob vereinfacht und rein theoretisch):
- Es wird geklickt und “Horst” hängt an die Ziel-URL eine eindeutige Klick ID (z. B. “horstclid=123456”) an. Damit ruft der Browser nun den gewünschten Inhalt auf der Ziel-Domain ab
- Wurde diese ID nicht durch Trackingschutz vernichtet, bevor auf der Zielseite nach Zustimmung ein “Horst Ads Pixel” geladen wird, schreibt das Script die ID in ein First-Party-Cookie
- Zusätzlich kann “Horst” den Besucher möglicherweise (durch Anmeldung, eigene Cookies oder anhand IP und User Agent) anhand des Requests beim Abruf des Tracking-Scripts identifizieren und teilt dem “Horst Ads Pixel” in der Serverantwort eine eigene ID zur Verfügung, die den Browser mit dem Konto des angemeldeten Besuchers verknüpfbar macht. Das Script kann diese ID in ein (weiteres) First-Party-Cookie schreiben
- Auf der besuchten Domain werden verschiedene Seiten aufgerufen und schließlich eine Conversion ausgelöst. Alle Ereignisse, die bis dahin aufgezeichnet wurden, können ebenso wie die Conversion selbst die Referenzen aus den beiden Cookies aktiv an “Horst” mitsenden
- “Horst” kann die Ereignisse und Conversion dem Konto der Plattform und ggf. der letzten Klick-ID zuordnen und das Profil so mit neuen Informationen anreichern. Alles ohne Third-Party-Cookies
So oder ähnlich funktionieren bereits viele Methoden zum Austausch und Speicherung von Identifiern. Nicht zuletzt deshalb, weil Third-Party-Cookies schon seit über zehn Jahren aussterben und außer in Chrome längst in keinem Browser mehr eine Rolle spielen (dürfen).
Session-ID vs. Adressierbarkeit
Während das Tracking von Conversions und selbst die Bildung von Profilen inzwischen also hauptsächlich auf First Party Cookies, Click-IDs und Trackingdienst-eigene Referenzen basiert, ist das Bilden von Zielgruppen zur Bewerbung jenseits der eigenen Domain ohne Third-Party-Cookies eine echte Herausforderung (mehr Infos hierzu). Betroffen sind daher vor allem Display-Werbeformen wie Programmatic, RTB, Retargeting & Co.
Durch die oben beschriebenen “Brücken”, die First-Party-Cookies im Zusammenspiel mit externen Identifiern bauen, ist für einen Teil des Werbe-Ökosystems und dessen Anforderungen eine Lösung herzustellen, solange das entsprechende Netzwerk selbst über einen großen Datenbestand verfügt. Selbst bei Google, Meta & Co. ist die so mögliche Referenzierung für erkannte Besucher quantitativ kein Ersatz für eine Erkennung aller Browser, wenn diese sich ein Third-Party-Cookie einfangen können. Denn dann es egal, ob Klick IDs beim Sender oder ein bestehendes Profil beim Empfänger existieren. Die auf diesem Weg (noch) herzustellenden Zielgruppen sind daher ungleich größer.
Das Zauberwort lautet also “Adressierbarkeit”. Diese ist deutlich schwieriger herzustellen, als eine einfache, zur Not kurzlebige “Klammer” um die Seitenaufrufe einer Browser-Session zum Zweck reiner Reichweitenmessung.
Dazu kommen Einschränkungen, die selbst vor First-Party-Cookies nicht Halt machen.
Auch First-Party-Cookies sind nicht frei von Problemen!
Sind Third-Party-Cookies aus dem Spiel, kann man wie oben beschrieben eine Brücke bauen oder benötigt ggf. gar keine Adressierbarkeit, sondern nur eine ID für die Dauer der Session. Selbst dann sind die bereits angesprochenen Hürden zu überwinden, bevor Cookies genutzt werden können:
- Fehlende Zustimmung macht eine Nutzung ggf. unmöglich - oder das eigene Setup soll ohne einen Zustimmungsdialog auskommen und muss daher generell auf Cookies verzichten
- Die u. U. recht kurze Lebensdauer der Cookies kann dafür sorgen, dass zum Zeitpunkt einer Conversion bereits keine Referenz mehr zu einem Klick existiert, weil das Cookie bereits verstorben ist. Das kann sogar nach einem Tag der Fall sein, ohne dass man aktiv im Browser für eine Löschung sorgen muss (Stichwort: Trackingschutz). Wiedererkennung in der Webanalyse leidet unter diesem Problem
- Klick-IDs oder andere Referenzen, die im Referrer oder sonstwo versteckt sein mögen, sind durch Trackingschutzmaßnahmen gefährdet und schaffen es daher ggf. nicht mehr wie gewohnt in ein Cookie
In Summe ist das First-Party-Cookie also nicht tot, aber als Allheilmittel vollkommen ungeeignet. Fehlen bei 50% der potenziellen Signale für Analytics oder Werbung die Zustimmung, fehlen auch deren Signale und der Nutzen zur Auswertung von Besucherverhalten oder gar Steuerung von Kampagnen ist begrenzt.
Lösungsansatz “Server-Side”
Die meisten Ansätze laufen auf die eine oder andere Weise auf einen Rückzug aus dem problembehafteten Browser hinaus. Immer mehr Plattformen bieten entsprechende APIs an, um Daten direkt vom Server anzuliefern. Das kann via Server-Side-Tagging oder Server-Side-Tracking geschehen (mehr Infos zur Unterscheidung).
Im Hinblick auf Browser-Trackingschutz ist das eine valide Taktik. Denn: Wir müssen ohnehin für die meisten Dinge nach Zustimmung fragen. Daher muss der Browser uns nicht noch weiter einschränken. Richtig? Wer diese Einstellung nachvollziehen kann, muss es auch am anderen Ende komplett durchdenken: Nur weil wir “unsichtbar” auf dem Server agieren, ändert das nichts an der Tatsache, dass für viele Cookies und Trackingdienste eine Zustimmung erforderlich ist und wir sollten danach handeln.
Die Verwendung eines eigenen Endpunkts in Form eines server-side Tag Managers, der den Browser vom Trackingdienst entkoppelt und Kontrolle über den Datenfluss ermöglicht, ist daher zwar eine gute Sache und eröffnet viele Möglichkeiten. An rechtlichen Rahmenbedingungen ändert der Rückzug aus dem Browser aber nichts! Ob man so die Meta Conversion API (CAPI) bzw. deren Pendants von TikTok, Pinterest & Co. anbindet, Google Ads oder “nur” Google Analytics: Die Verantwortung dafür, dass nur die gewünschten Daten an berechtigte Empfänger versendet werden, liegt immer noch beim Betreiber der Tracking-Lösung.
Es gilt daher, alle Lösungsansätze zu vermeiden, welche mit serverseitigen Fingerprints - evtl. gar in Verbindung mit in Hash-Tabellen gespeicherten Klick-IDs - an Zustimmung vorbei agieren, ohne dabei die Anforderungen des Datenschutzes zu beachten. Der Server ist nicht der Wilde Westen!
Ungeachtet dessen sind “Fingerprints” oder besser ein möglichst kurzlebig gestalteter “Session-Hashs”, die am Server auf Basis der empfangenen Daten entstehen unter Umständen ein valider Ausweg. Nicht für Adressierbarkeit, sondern für die (meist kurzzeitige) Identifizierung eines Browsers für die Dauer einer Sitzung oder ggf. sogar darüber hinaus. Einige Beispiele dafür sind im Abschnitt zum Lösungsansatz “Zustimmungsfreie Webanalyse” beschrieben.
Nicht zu vernachlässigen sind - bei fast allen rein serverseitigen Lösungen - Aufrufe durch Crawler und Bots. Je nach Art der serverseitigen Erhebung kann die Bot-Problematik selbst bei einfachen Crawlern so groß werden, dass die entstehenden Daten kaum noch nutzbar (oder sehr irreführend) sind.
Deshalb beteiligen viele Lösungen immer noch auf die eine oder andere Weise den Browser, um weitere Signale zur Erkennung von Bots zu sammeln oder den Consent Dialog als zusätzlichen Filter für irrelevante Aufrufe zu nutzen. Ein weiterer Grund ist die Tatsache, dass ein Server nicht zwingend alles “mitbekommt”, was vermessen werden soll. Wenn Klicks, Ausstiege auf externe Seiten, Interaktionen im Browser etc. Teil des Eventplans sind, muss der Server auf irgendeinem Weg darüber informiert werden, was im Browser passiert.
Außerdem werden vor allem zur Stärkung der Adressierbarkeit von einigen Tracking-Scripts Strategien im Browser etabliert, aktiv E-Mailadressen und andere prsönliche Informationen einzusammeln und dem Dienst zur Verfügung zu stellen. Das dient sowohl verbessertem Cross-Browser- bzw. Domain-Tracking als auch für den Fall, dass Cookies nicht überlebt haben sollten.
Lösungsansatz “E-Mail-Adressen und Hashwerte”
Generell ist es nicht ausgeschlossen, bei Zustimmung und ausreichender Information der Besucher auf solche Mittel zurückzugreifen. Google Ads hat dazu Enhanced Conversions und die im Browser automatisch gesammelten “von Nutzern bereitgestellten Daten” dienen auch für Google Analytics zur Identifizierung von Besuchern, die mehrere Geräte nutzen und deren Sessions in der Analyse zusammengeführt werden sollen.
Dabei kommen persönliche Informationen wie Namen, Anschriften, Telefonnummern und vor allem E-Mail-Adressen entweder im Klartext oder als Hashwert zum Einsatz. Auf der anderen Seite wird dann versucht, die Information oder deren Hashwert mit entsprechenden Daten bzw. Hashwerten des eigenen Bestands zu vergleichen, um eine Identifizierung zu ermöglichen. In Data Clean Rooms kann man als Betreiber eines Werbekontos sogar aktiv an dieser Zusammenführung mitarbeiten, um gesammelte Informationen von der Website in aktivierbare Daten für Werbesysteme zu verwandeln. Wie gesagt: Mit Zustimmung mag das in Ordnung sein und - ausreichendes Volumen vorausgesetzt - auch effektiv. “Zusammenführung” muss zudem nicht zwingend bedeuten, dass Aktivierung bzw. Teilen mit Dritten das Ziel ist, sondern sie findet ggf. nur im eigenen Datenbestand für analytische Zwecke statt
Leider ist diese Methode beim Tagging und Tracking allzu oft ein schlechter Deal, der zudem noch problematisch umgesetzt wird. Außerdem hat nicht jeder solche Informationen. Ohne Logins - oder auf Sites, auf denen eine Anmeldung bestenfalls vor dem Kauf stattfindet - kann man diese Daten nicht oder nur sehr bedingt nutzen. Sie im Browser für jedes Script lesbar vorzuhalten, ist zudem nicht frei von Risiken.
Die Hoffnung, dass beim Empfänger mit diesen Daten eine Brücke zu einem Profil geschlagen werden kann, um Zielgruppen zu bilden oder Conversions zu messen, wird logischerweise nicht immer erfüllt. Man sendet dennoch 100% der bekannten persönlichen Daten raus. Bemühungen um mehr “Zero-Party-Data” (was in diesem Fall persönliche Daten meint), die Verbindung zum CRM oder Anschaffung von CDPs sollen vielleicht nur diesem Zweck dienen? Hand aufs Herz: Wie effektiv erscheint der Aufwand aus dieser Perspektive?
Unklar bleibt häufig, was mit den versendeten Daten passiert, wenn diese nicht mit einem Profil übereinstimmen. Im Fall von TikTok werden solche Daten z. B. “auf Vorrat” gesammelt, so dass sie schon da sind, wenn sich später neue Nutzer registrieren sollten, deren Daten dazu passen. “Komm zu TikTok, Deine Daten sind vermutlich schon da” wird so schnell zum schal schmeckenden Witz.
Für eine gewisse Zeit hat das Criteo Pixel im Browser sogar (leider habe ich keine Quellen mehr dazu gefunden) den kompletten Inhalt des dataLayers nach Hause gesendet, wann immer ein Tracking-Request den Browser verlassen hat. In der Hoffnung, dort Mailadressen und andere Daten im Klartext oder als Hash zu finden, die ggf. zu Tracking-Zwecken hinterlegt wurden. Unschön, wenn man darüber nachdenkt… und eine gute Erinnerung daran, dass jedes eingebundene externe Script seiner Quelle solche Möglichkeiten eröffnet. Passiert es heute nicht, ist das keine Garantie dafür, dass sich dieser Zustand nicht morgen schon ändern kann.
Wer daher den “Empfänger-Datenschatz” nicht unerwünscht groß ausfallen lassen möchte, ist gut beraten, eine Anreicherung mit Mailadressen & Co. nicht über den Browser stattfinden zu lassen, sondern lieber durch serverseitige Anreicherung der Daten. Der Vorteil liegt auf der Hand: Der Browser muss diese Daten nicht kennen und kann sie nicht ungewollt preisgeben, während auf dem Server volle Kontrolle darüber besteht, wer diese Daten erhalten soll… und unter welchen Bedingungen.
Und um es noch einmal klar zu sagen: E-Mail-Adressen & Co. sind ein Mittel, um bei fehlenden Cookies eine gewisse Lücke zu schließen, aber sie nutzen nichts, wenn keine Zustimmung dazu eingeholt wurde! Als "Ersatz" für alles, was wegen fehlender Zustimmung nicht gemessen werden kann, ist dieses Mittel daher definitiv nicht geeignet!
Lösungsansatz “Externe / geteilte ID”
Will man vor allem die eigenen Datenbestände mit einem Identifier ausstatten, der eine Wiedererkennung und Verknüpfung mit anderen Daten erlaubt (nicht nur, aber auch im Kontext von Werbung und Aktivierung), kann dies mit Hilfe von verschiedenen externen Anbietern tun, die entsprechende IDs unter Namen wie “Open ID” in eigenen Datenbeständen verwalten. Diese basieren auf Login-Systemen, geteilten Datenbanken größerer Sites und Werbenetzwerken. Mit Zustimmung erhoben und genutzt, kann man so selbst am Spiel teilnehmen, welches im vorherigen Abschnitt beschrieben wurde. Es ist offensichtlich, dass nicht jede Website gleich gut davon profitieren kann, so dass es am Ende doch eher Werbeplattformen und Netzwerke sind, die damit gegen den Wegfall von Third-Party-Cookies etwas bewirken können. Das gilt (bisher) genauso für die vielen Versuche von Google, einen brauchbaren Ersatz für die sterbenden Kekse zu etablieren:
Lösungsansatz “Privacy Sandbox”
Um diesen Absatz kurz zu halten: Sämtliche Ersatztechnologien, die Googles “Privacy Sandbox” bisher für auf Kohorten statt einzelner Browser basierende Zielgruppen, Conversiontracking und Ausspielung von interessenbasierter Werbung hervorgebracht hat, sind auf dem Prüfstand gescheitert. Es scheint keine echte Alternative in Sicht, solange vorgeschlagene Lösungen regelmäßig Schwächen offenbaren. Sich als “Privacy” zu verkaufen, aber am Ende nichts anderes als einen alternativen Tracking-Vektor darzustellen, die einzelne Browser wieder identifizierbar macht, ist schlichtweg keine Option.
Das Hauptproblem für eine evtl. überlebende Lösung wird bleiben, dass sie eine Insellösung darstellen wird, die nur im Google Universum einen wirklichen Wert hat. Ebenso wie bei Apple, externen ID-Anbietern oder Plattformen entsteht ein weiterer “Walled Garden”, der das eigene Werbe-Ökosystem stärkt und den Wettbewerb damit umgekehrt benachteiligt.
So oder so wird man als Betreiber einer Website, die Measurement oder Tracking betreiben will, nur wenig mit diesen ganzen Lösungen zu tun haben, denn sie behandeln Probleme der Plattformen als Empfänger und nicht diejenigen, die man als Sender von Daten haben mag.
Lösungsansatz “Zustimmungsfreie Webanalyse”
Viel praxistauglicher für Betreiber erscheint da das Ausweichen auf Technologien, die keine Cookies benötigen - und im Idealfall ohne Zustimmung betrieben werden können. Um wieder “das Ganze” betrachten zu können, ist dieser Weg durchaus valide.
Selbst sammeln und daraus Reports zu generieren, die Aufschluss über das Verhalten auf der eigenen Website bieten, Conversions nachvollziehbar machen und eine Attribution von Erfolg auf verschiedene Kanälen zu erlauben, ist eine gute Sache. Interessierte finden dazu einen mehrstündigen Workshop auf meinem YouTube-Kanal als Playlist.
Verschiedene Webstatistik- und Analyticstools sind nach eigener (für die Nutzung im geplanten Kontext stets zu prüfende!) Aussage zu betreiben, ohne nach Zustimmung fragen zu müssen. Wer sich einen Überblick über verschiedene Alternativen verschaffen will, findet im Beitrag zu möglichen Google-Analytics Nachfolgern weiteres Material zum Thema.
Auf diese Weise kommt man wieder zu einem Gesamtüberblick und kann sich aus Rohdaten beliebig eigene Berichte und Attribution zusammenbauen - in der Theorie zumindest. In der Praxis sind die Auswertungsmöglichkeiten im Tool selbst oft zu begrenzt, um alle Fragen zu beantworten. Das liegt je nach Ansatz entweder “nur” an der Funktionalität des Tools… oder es ist dadurch bedingt, dass mit voller Absicht nur begrenzte Daten erhoben, aggregiert gespeichert und / oder nicht in beliebigen Kombinationen abrufbar sind.
Die Anforderungen des Datenschutzes werden also mit diesen Einschränkungen ggf. erfüllt und können daher nicht einfach umgangen werden. Deshalb sind je nach den eigenen Anforderungen solche Systeme sinnvoller, die einen Hybridbetrieb bieten und im Fall von Zustimmung die Erhebung von mehr Daten und granularere Auswertung erlauben.
Attribution? Jein.
Vor allem die Attribution ist häufig eingeschränkt. Denn: Wo kein Cookie gesetzt und keine Daten aus dem Browser ausgelesen werden, wird ein “Session Hash” aus Daten wie IP-Adressen, User Agents und anderen, sehr allgemeinen Daten gebildet. Wechselnde Komponenten bei der Bildung eines solchen Hashs (“Salt”) und die Tatsache, dass eine IP-Adresse oft nicht für die Ewigkeit ist, begrenzen den Zeitraum, in dem ein solches Merkmal unverändert bleibt. Die Folgen sind eine geringere Dauer der Wiedererkennung und schlechtere “Auflösung” im Vergleich zu individuellen Cookies je Browser, denn mehrere Besucher können gleichartige IP-Adressen und andere Attribute aufweisen.
Aktivierbarkeit? Nein!
Für eine Annäherung und kurzzeitige Attribution ist das gut genug, aber noch lange kein vollständiger Ersatz für das, was Cookies und Tagging mit Zustimmung erlauben. Zudem muss man sich wieder selbst an das Ruder in Werbesystemen begeben und manuell danach steuern, was solchen Tools an Insights zur Effektivität einzelner Maßnahmen zu entlocken ist.
Denn: ein aktives Zurückspielen in Google Ads & Co ist aus mehreren Gründen problematisch bzw. inzwischen eigentlich unmöglich. Spätestens mit vollständiger Durchsetzung der Consent Mode v2 Pflicht durch Google (Nein, ganz durch sind wir damit noch nicht) müssen alle Signale, die dort zur Zielgruppenbildung oder Messung von Conversions dienen sollen, die explizite Zustimmung dazu dokumentiert mitbringen.
Sammelt man seine Daten ohne Zustimmung, kann man diese zwar aus technischer Sicht relativ einfach über Uploads oder APIs mit Google Ads und anderen Systemen teilen, doch genau wie beim Server-Side Tracking ändert das nichts daran, dass man es vermutlich nicht darf. Die Zustimmung bei der Anlieferung hinzudichten? Das mag einfach sein und niemand kann es im Zweifelsfall sehen, aber das macht es nicht datenschutzkonform! Dass andere Systeme wie Microsoft Ads ggf. geringere Anforderungen an die zu liefernden Daten haben, ändert daran nur wenig.
Schnittstellen von Matomo, etracker und anderen Tools sind damit - zumindest wenn es um Google Ads geht - aus dem Rennen 🙁
Zustimmungsfrei zu betreibende Webanalyse kann eine gute Ergänzung darstellen, um das Gesamtbild zu erheben. Aus reiner “Analytics-Sicht” mag sie gar ein vollständiger Ersatz zu Google Analytics etc. sein. Für das Marketing kommt man an Marketing-Tags und Zustimmung nicht vorbei. Ob und wie diese ohne Cookies auskommen, ist ein anderes Thema.
Lösungsansatz “Modellierung”
Modellierung zum Schließen der Lücken, die durch verweigerte Zustimmung entstehen, ist vermutlich die Beste aller Lösungen. Sie braucht aber leider ein Mindestmaß an Signalen bzw. Informationen, um auf dieser Basis die fehlenden Daten zu modellieren.
Woher kommen diese Basisdaten? Im Idealfall handelt es sich um einen Pool aus ausreichend vielen mit Zustimmung aufgezeichneten Besuchen, dass damit die Lücke geschlossen werden kann. Bleibt das Problem, dass man ohne Kenntnis des Gesamtvolumens nicht wissen kann, wie groß die Lücke eigentlich ist. Zustimmungsraten eines Consent Tools sind dazu nicht die beste Quelle. Alternativ können Daten von allen Besuchen als Basis dienen, die allerdings ohne Zustimmung i. d. R. sehr reduziert ausfallen. Dazu gibt es Systeme und individuelle Lösungen, die ohne Datenschutzprobleme in der Lage sind, ein solches Gesamtbild zu skizzieren und dann ggf. die Lücken per Modellierung zu füllen.
Als “Massenprodukt” nutzt Google Analytics ebenfalls Modellierung. Gleiches gilt für Google Ads. Bevorzugter Signalgeber ist hierfür allerdings der Advanced Consent Mode. An mehr als einer Stelle (z. B. hier) habe ich mich kritisch mit dem Advanced Consent Mode auseinandergesetzt, den Google bei fehlender Zustimmung (mitunter sehr eindringlich) empfiehlt. Wenngleich dabei keine Cookies verwendet werden, halten (auch im Vergleich zu mir deutlich kompetentere) datenschutzkundige Personen diesen Ansatz für nicht tragbar. Um “cookieless” und ohne Zustimmung evtl. tatsächlich mit Google Analytics zu arbeiten, muss an einem eigenen Tracking-Endpunkt, Proxy oder über sonstige serverseitige Anbindung so viel an Informationen entfernt werden, dass sehr wenig zur Analyse und nichts zur Modellierung bleibt. Zudem kann man dieses Verfahren nicht für Google Ads nutzen.
Abhängig von der geplanten Nutzung der Daten sind unterschiedlich große Hürden zu überwinden. Wo das Auffüllen von Lücken in aggregierten Statistiken durch verschiedene Ansätze mit kalkulierbarer Fehlerspanne erzielt werden kann, ist die Umsetzung einer möglichst vollständigen Werbe-Erfolgskontrolle mittels Modellierung eine echte Herausforderung. Lösungen hierzu wie die “synthetischen User” von JENTIS sind relativ neu und müssen sich in der Praxis bei langfristigem Einsatz erst noch als wirksam erweisen.
Leider sind die meisten nicht-individuellen Lösungen vor allem eins: eine Blackbox mit unbekannter Präzision für den eigenen Anwendungsfall. Steckt wirklich etwas dahinter oder hat das Marketing nur ein “KI-Label” auf eine nicht belastbare Milchmädchenrechnung geklebt?
In einem sich noch entwickelnden Markt ist es eher schwierig, eine passende Lösung zu finden, die nachweislich belastbare Ergebnisse erzielt, welche den Aufwand wirklich rechtfertigen. Die gute Nachricht ist, dass Modelle in allen möglichen Anwendungsbereichen gefühlt im Stundentakt besser werden und mit immer weniger Ausgangsmaterial zurecht kommen. Es können nur Modelle bis in die vollständig “cookielose” Zukunft führen, welche mit Input klar kommen, der ohne Cookies erhoben wird.
Im Extremfall verzichtet man vielleicht sogar vollständig auf die Vermessung von Besucherverhalten und setzt voll auf Modellierung in Form von MMM (“Marketing Mix Modelling”). Basierend auf Ausgaben und erzielten Ergebnissen ohne gemessene Daten darüber, was zwischen diesen beiden Kennzahlen passiert ist. Das ist aber weder meine Welt, noch ein Thema für einen kleinen Absatz, also belassen wir es bei dieser Erwähnung 😉
Fazit: Welche Überlebensstrategie passt zu mir?
Als Betreiber einer Website auf der Suche nach möglichst brauchbaren Website-Statistiken ohne Cookies (und / oder ohne Zustimmung) kann man sich aus einem immer größer werdenden Angebot bedienen.
Selbst Daten für Marketing und Aktivierung sind zu retten. Wer dabei die obigen Punkte im Auge behält und sich keine halbseidenen Setups mit Server-Beteiligung verkaufen lässt, nur “weil es ja keiner sieht” - die am Ende für den eigenen Datenbestand nicht einmal eine nennenswerte Verbesserung bringen müssen -, kann der Zukunft relativ gelassen entgegenblicken.
Es ist allerdings höchste Zeit, sich mit dem nun erlangten Hintergrundwissen kritisch mit den derzeit genutzten Methoden und Tools auseinanderzusetzen und die Auswirkungen einzuschätzen, wenn dies nicht bereits passiert ist. Da wie gezeigt für die eigene Auswertung von Daten reichlich Optionen existieren und First-Party-Cookies noch kein Ablaufdatum haben, kann morgen noch das ausreichen, was heute funktioniert. Fehlen künftig - oder schon jetzt bereits - zu viele Daten, um den eigenen Anforderungen gerecht zu werden, muss man sich mit den existierenden Lösungen auseinandersetzen und die Ergebnisse bewerten.
Werbetreibende sind unter Druck von allen Seiten, APIs zu implementieren, serverseitige Anbindungen zu nutzen und persönliche Daten zu sammeln und zu teilen - aus den oben beschriebenen Gründen. Solange der Datenschutz nicht auf der Strecke bleibt und die Erwartungen an die Ergebnisse einer Umsetzung realistisch sind, bleibt die wichtigste Frage, ob der Aufwand jetzt wirtschaftlich sinnvoll ist. Es braucht ein differenziertes Durchrechnen des Effekts, der für Conversiontracking, Zielgruppenbildung oder Gebotsgestaltung realistisch zu erwarten ist. Was auch immer entschieden wird - es wird auf Risikomanagement hinauslaufen. Nichts zu ändern, birgt das Risiko von Verlust der Wettbewerbsfähigkeit. Handeln kann ein Minusgeschäft werden, das Datenschutzrisiko erhöhen oder bei Fehlern bzw. Fehleinschätzungen die Reputation schädigen.
Eine valide Option auf jeder Liste sollte der Verzicht sein.
- Was wird von dem, was wir unbedingt an Daten retten wollen, wirklich benötigt - auch morgen noch?
- Wie tragisch wäre es, auf Zielgruppenbildung zu verzichten, nur um eine mäßig funktionierende Display-Kampagne am Leben zu erhalten? Was heute individuell identifizierbare Browser als Trigger für Werbung benötigt, muss vielleicht morgen auf anderem Weg versucht werden.
- Wer genug historische Daten, Diversität in Kanälen und Ausgaben sowie Volumen besitzt, mag mit MMM erfolgreich sein und kann auf Tracking verzichten.
- Kann man auf die Verbindung zwischen Daten und Werbesystem verzichten und stattdessen mit manueller Steuerung vergleichbare Ergebnisse erzielen?
Verzichten wir auf die Frage nach Zustimmung und begnügen uns mit weniger Analysedaten in der Tiefe, blicken dafür aber wieder über die ganze “Breite” dessen, was auf der Website passiert?
Viele Dinge lassen sich erproben und anhand der Ergebnisse bewerten.
Bei allem Buzz rund um das Thema ist hoffentlich ein Punkt deutlich geworden: Die größte Herausforderung, die sich aus dem anstehenden Wegfall der Third-Party-Cookies ergibt, ist die domainübergreifende Wiedererkennung von Besuchern. Das ist ein Problem, das primär die Werbeplattformen lösen müssen, nicht die Werbetreibenden. Für Conversions, Statistik und Measurement haben wir noch eine ganze Weile First-Party-Cookies und die anderen hier vorgestellten Wege. Handlungsbedarf besteht zwar, aber nicht für jeden Anwendungsfall in gleicher Dringlichkeit. Ähnlich gilt für die angepriesenen Lösungen: Nicht alle lösen sämtliche Probleme, nur weil KI oder Server-Side drauf steht. Wie eingangs versprochen: it depends 😉 Und damit schließt sich der Kreis.