Serverseitiges Tagging mit Google Tag Manager: Erste Eindrücke
Hinweis: Dieser Beitrag stammt aus dem August 2020. Die Beispiele und Screenshots zeigen noch Universal Analytics und das damals noch als "App + Web" bezeichnete GA4, wie in den Abbildungen zu erkennen ist. Serverseitiges Tagging mit dem Google Tag Manager funktioniert mit GA4 auf die gleiche Weise.
Das Warten hat ein Ende: Die im Januar angekündigten serverseitigen Container für Google Tag Manager sind als Beta verfügbar. natürlich hat sich Simo Ahava umgehend "öffentlich drauf gestürzt" und deutlich mehr als nur eine kleine Anleitung und Einordnung des Nutzens erstellt. Community Templates für Tags und Clients (dazu gleich mehr) sind an mehreren Stellen in Arbeit, die sowohl im Kontext von Google Analytics angepasstes Tracking erlauben, als auch Facebook und andere Dienste abdecken werden.
Können wir also bald alles, was derzeit im Client per JavaScript passiert, einfach auf magische Weise aus dem Browser ziehen und am Server stattfinden lassen? Jein. So magisch ist der ganze Zauber dann doch nicht. Wozu dient also der serverseitige Container und welche Vorteile (und Nachteile?) bringt er mit sich?
Serverseitige GTM-Container: (m)eine Schicht mehr
Grundsätzlich bedeutet der Einsatz des neuen Containertypen im Kern nicht mehr, als dass Tracking-Hits nicht mehr direkt aus dem Browser des Besuchers an den jeweiligen Trackingserver gesendet werden, sondern zunächst an den serverseitigen GTM Container. Dieser steht unter der Kontrolle des Websitebetreibers und erst von dort aus erreichen Daten alle externen Trackingdienste. Nur ein Umweg also. Das ist zwar nicht alles, aber ein wesentlicher Aspekt des Konzepts.
![]()
Zum Vergleich hier normales Tracking via GTM ohne serverseitige Komponente ebenso als animiertes Gif (öffnet neuen Reiter, sonst wimmelt es hier zu viel). Es wird eine weitere Schicht in die Kommunikation zwischen Website und Tracker etabliert, die zwei wesentliche Vorteile bietet:
- "First Party Tracking": Alle so verarbeiteten Tracking Hits aus dem Client werden an den Server gesendet, der die Website bereitstellt. In der idealen Welt werden solche Hits nicht durch Browser-Trackingschutzmaßnahmen unterbunden.
- Entkopplung und Kontrolle: Bevor diese Hits vom GTM-Servercontainer an den Trackingdienst wie z. B. Google Analytics weitergeleitet werden, können die übertragenen Daten angepasst, angereichert oder auch reduziert werden. Es findet keine direkte Kommunikation zwischen Browser und Trackingdienst statt. OK, das stimmt nicht ganz bzw. nicht unter allen Umständen, denn im Browser wird ggf. schon immer noch das Trackingscript des Anbieters wie gtag.js, analytics.js etc. benötigt. Das ist aber a) nicht zwingend und b) auch über den GTM-Servercontainer technisch lösbar, also ignorieren wir diesen Punkt vereinfachend. Mit einem serverseitigen GTM-Container gewinnt der Betreiber der Website die Kontrolle über die übertragenen Daten (zurück). Mit allen moralischen Stolpersteinen sowie Vor- und Nachteilen, die auch schon im Beitrag zum serverseitigen Tracking mit Google Analytics beschrieben sind.
Setup eines serverseitigen Containers im Schnelldurchlauf
Die Einrichtung ist (zumindest für einen ersten Test) überschaubar. Sie verlangt nur geringes technisches "Mehrwissen" im Vergleich zu einem üblichen Client-Container. Aus der Verwaltung wird ein Server-Container genau wie jeder andere Containertyp erzeugt, indem "Server" als Zielplattform ausgewählt wird.
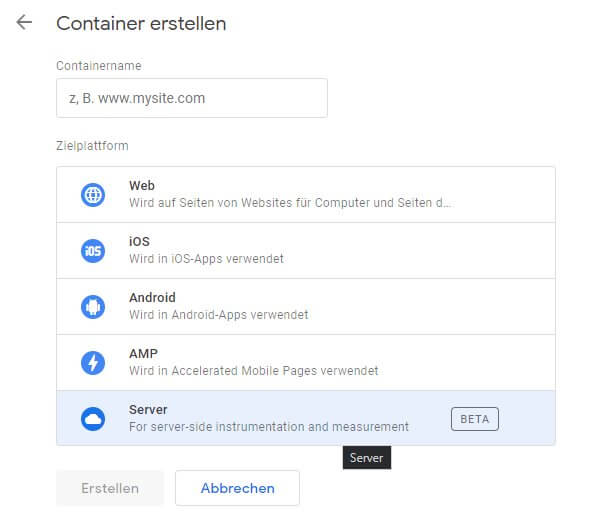
Nach dem Erstellen landet man ein einer ansatzweise vertraut wirkenden Umgebung zur Verwaltung eines GTM Containers. Bevor man sich damit allerdings befassen kann, benötigt dieser ein Zuhause. Meint: Es muss ein Server her, auf dem die entsprechende Funktionalität zum Betrieb des Containers bereitgestellt werden kann.
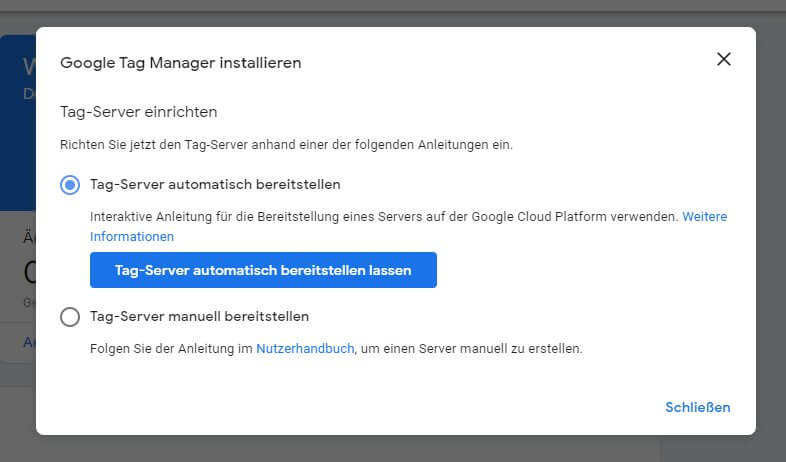
Hier kommt eine nicht unwesentliche, wenngleich zumindest für den ersten Test erfreulich wenig technische Hürde: Derzeit sind die Container nur auf der Google Cloud Platform ("GCP") lauffähig. Und während man über die erste Option der automatischen Bereitstellung recht einfach eine App Engine Standard Instanz für Tests erzeugen kann, braucht man für den Ernstfall auf jeden Fall einen (manuell konfigurierten und bereitgestellten) App Engine Flexible Server. Damit einher gehen in der Regel auch Kosten, die je nach Trafficvolumen nicht unwesentlich ausfallen können, wenn im Livebetrieb die volle Last an Hits einläuft.
Am GCP-Konto kommt man nicht vorbei
So oder so: Man muss auch für die automatische Bereitstellung ein Abrechnungskonto anlegen, wenn noch keines vorhanden ist. Wobei man sich - vor allem bei einem neuen Account - i. d. R. keine großen Gedanken machen muss, wenn man vorsichtige erste Schritte machen möchte, denn der Einstieg ist mit 300$ für 12 Monate Guthaben bei neuen Accounts verbunden. Auch bei bestehenden Konten, deren Guthaben verbraucht ist, muss ein Test im Rahmen der Standard Instanz keine Kosten verursachen, solange man unterhalb der Limits des "Immer Kostenlos" Programms bleibt - was auf einem Staging Server oder mit einen nur gelegentlich im Vorschaumodus clientseitig getriggerten Server-Container stets der Fall sein sollte.
Optional: Eigene Tracking Subomain einrichten
Technisch anspruchsvoller wird der Betrieb jenseits des Tests mit der automatischen Option "auf der eigenen Domain". Das zum Beispiel dadurch, dass man dazu eine Tracking-Subdomain wie trk.meinedomain.de anlegen muss (bzw. sollte), um diese in der GCP dann als Custom Domain verwenden zu können, so dass der Tag-Server auch wirklich im First Party Kontext agieren kann.
Das bedeutet: Auf dem eigenen Server oder im Hostingbackend eine Subdomain anlegen, verifizieren via TXT Record, mit angepassten DNS Records versehen... also eben deutlich mehr Aufwand, als das Einbinden eines GTM-Codes in eine Website. Was dadurch übrigens nicht unnötig wird, wie wir nachher noch sehen werden. Dass hier nicht der Weg über CNAME genommen wurde, ist übrigens den Trackingschutzmaßnahmen zu verdanken, mit denen Browser und AddOns inzwischen bereits gegen "Pseudo-First-Party-Tracking" vorgehen. Aber egal, zurück zum GTM.
Beschränkt auf die automatische Option landet man nach Auswahl bzw. Anlage eines GCP Accounts ohne weitere Schritte nach etwas Wartezeit mit Glück in der Arbeitsbereichsansicht des Containers. Ich habe das übrigens nicht immer beim ersten Versuch geschafft und es gab Fehlermeldungen. Eine Wiederholung des Vorgangs war aber stets erfolgreich. Es ist eine Beta und man merkt es auch... also nicht den Mut verlieren, wenn es beim ersten Mal nicht funktionieren sollte.
Hinweis: Wer keine Lust hat, diesen Schritt zu gehen, kann das Fenster auch direkt schließen und landet dann ebenfalls im Arbeitsbereich. Vor der Nutzung muss die Einrichtung aber abgeschlossen werden. Das geht - genau wie das Einsehen der Daten einer abgeschlossenen Einrichtung -, indem man auf die GTM-Container-Id oben neben dem Vorschau-Button klickt.
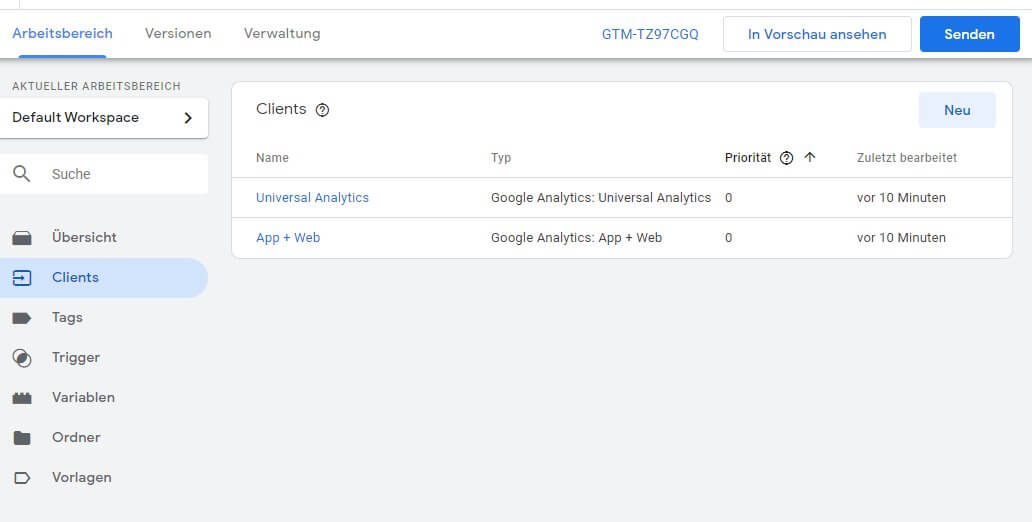
Der Arbeitsbereich wirkt auf den ersten Blick sehr vertraut: Es gibt Tags, Trigger, Variablen, Templates und Ordner... und selbst einen Button zur Aktivierung der Vorschau an der gewohnten Stelle. Neu hingegen sind die "Clients", die das Herz der serverseitigen Container darstellen.
Wer ist denn dieser "Clients"?
Zwei Einträge finden sich bereits in der Liste: vorgefertigte Clients für Universal Analytics und App + Web. Dass es unterschiedliche Typen gibt und auch eine Priorität existiert, kann man schon der Tabelle entnehmen. Aktuell ist aber nur Analytics (nebst einem Client-Typ für das Measurement Protocol) abgedeckt. Es werden sicher vermutlich durch Google selbst neue Client-Typen hinzukommen; ganz sicher aber durch die Community bzw. Anbieter von Trackingsystemen selbst.
Was machen die Dinger nun genau? Einfach betrachtet bilden sie die Schaltzentrale des serverseitigen Taggings: Alles, was an Daten bei Tracking-Aufrufen beim Tag-Server ankommt, kann von einem oder mehreren Clients entgegengenommen, bei Bedarf angepasst, erweitert, beschnitten und umgewandelt werden, bevor diese Daten dann zur Verarbeitung im Container bereitgestellt werden. Dabei dient ein "Event Model" als Mittler zwischen Clients und Tags. Nur die Daten, die ein Client in diese Event Daten schreibt, können von Tags gelesen und verarbeitet werden. Genau an dieser Stelle können und werden serverseitige GTM-Setups also ihre Stärken ausspielen.
Die vorhandenen Clients bieten dazu bereits ein paar Optionen. So kann der Universal Analytics Client beispielsweise dabei helfen, optional die clientseitig verwalteten _ga-Cookies auf serverseitig erzeugte Cookies umzustellen, die im Browser gar nicht mehr gelesen werden können. Auch hierzu hat freilich Simo schon etwas geschrieben 😉
Die Verarbeitung der durch die Clients aufbereiteten und bereitgestellten Daten wird - durch Trigger gesteuert - von einem oder mehreren Tags übernommen. Was erst einmal nicht so anders klingt, als es in einem "normalen" GTM-Web-Container der Fall wäre. Ist es im Prinzip auch nicht. Bevor wir aber über alles nachdenken, was man dabei Gutes oder Schlechtes mit den Daten anfangen und wo man sie überall hin senden kann, soll die Einrichtung eines Google-Analytics Beispieltrackings abgeschlossen werden.
Tag bauen und Trigger anlegen
Bei der Neuanlage eines Tags sind - passend zu den Clients, die sich auf Analytics beschränken - ebenfalls aktuell nur analyticsbezogene Tags sowie ein "allgemeines" Tag zum Senden einer HTTP Anfrage an einen beliebigen Endpunkt verfügbar. So spannend diese dritte Option auch ist: noch interessanter sind sicher eigene Tags, die die Analytics-Daten für ganz andere Dienste wie z. B. Facebook, Google Ads Conversiontracking oder jede Menge andere Zwecke aufbereitet von dafür speziell angefertigten Clients erhalten. Das alles wird vermutlich schnell kommen.
Mehrfachnutzung von Daten bietet sich faktisch an
Rein clientseitiges Tagging erfordert das Senden eines Seitenaufrufs oder eines E-Commerce-Events wie dem Hinzufügen eines Produktes zum Warenkorb bei Nutzung von Google Analytics, Facebook, Criteo & Co. an jeden dieser Empfänger einzeln. Aus dem Browser werden also eine Menge Requests angesetzt. Bei einer serverseitigen Implementierung wäre es ausreichend, nur den Analytics-Hit an den eigenen Tag-Server zu senden und von dort aus an die gewünschten Empfänger - in beliebigem Umfang - zu verteilen. Kombinationen von Clients und Tags eröffnen in diesem Zusammenhang uneingeschränkte Flexibilität. Wir wollen aber für den Start "nur" die vom Client empfangenen Analytics-Daten an Google Analytics weiterreichen.
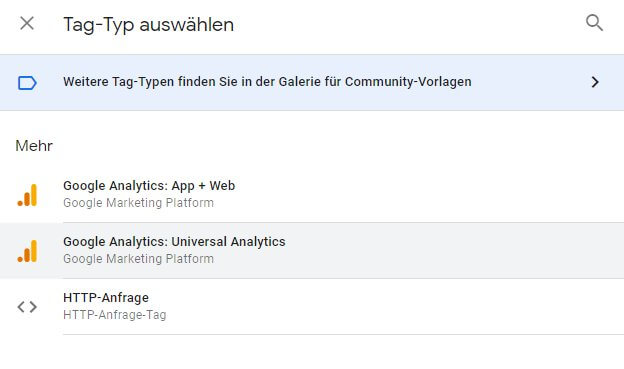
Im Fall von Universal Analytics ist die Einrichtung des Tags schnell erledigt. Hinzufügen, Namen vergeben und dann fehlt nur noch ein Trigger. Ja: man kann einige Dinge auch hier anpassen, um zum Beispiel die Property-Id des Hits zu überschreiben (genau: ein einfacher Weg, alle oder ausgewählte Hits mit einem weiteren Tag an eine zweite Property zu senden) oder durch die Anpassung von Feldern auch andere Daten mit bestimmten Werten zu versehen, bevor die Hits versendet werden. Brauchen wir aber für die Weitergabe an die i., d. R. schon im Hit angegebene Property nicht.
Tags als "Übersetzer" der Daten für Trackingdienste
Der Zweck eines solchen Tags ist also die Verarbeitung der Daten, die vom Client an die Tags weitergereicht werden, um diese dann an den jeweiligen Trackingdienst zu versenden. Vereinfacht werden die Parameter des durch den Client empfangenen Hits hier also schlichtweg via Measurement Protocol an den Google Analytics Server weitergereicht (über den Umweg der Event Daten).
Die Event Daten sind dabei so etwas wie "der dataLayer des serverseitigen Taggings". Zumindest in dem Sinne, als dass Daten, die in Tags verarbeitet werden können, i. d. R. auf diesem Weg aus den Requests empfangenen Clients an sie weitergegeben wurden. Das Format der Event Daten ist dabei bei den bestehenden Clients an die Anforderungen des Trackings mit Google Analytics ausgerichtet.
Daher gibt es auch keine unterschiedlichen Tag Varianten für Seitenaufrufe, Events oder gar klassische Transaktionen o. Ä, denn all diese unterschiedlichen Hit-Typen werden ja schlussendlich auf die gleiche Art und Weise an Analytics gesendet... und dieses Tag übernimmt genau diese Aufgabe.
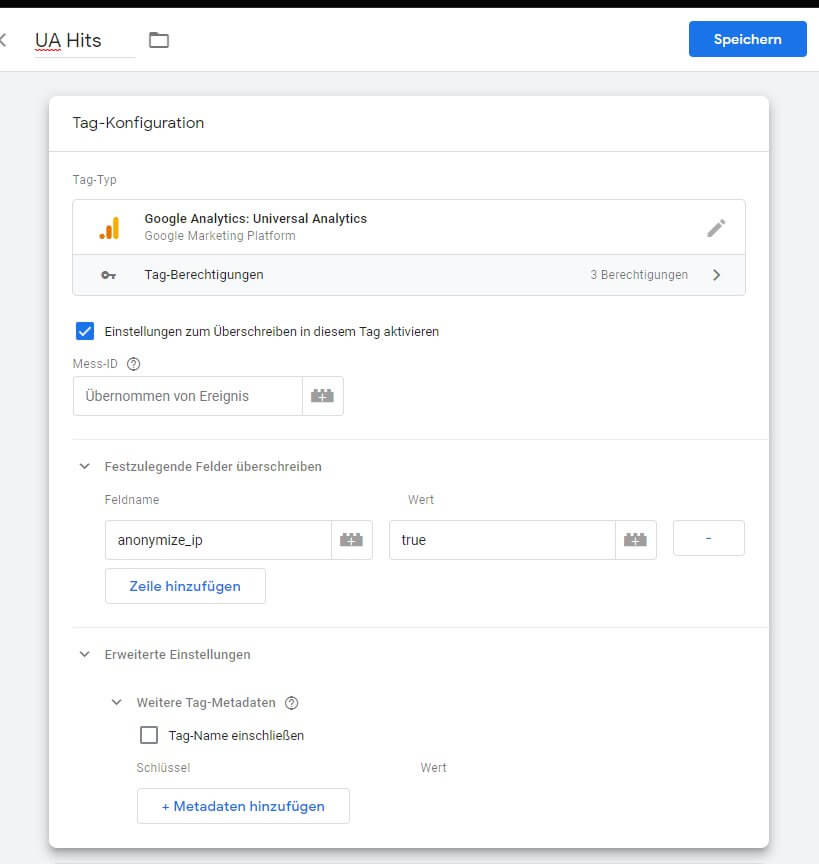
Damit ein Tag weiß, wann es etwas zu übertragen hat, ist ein Trigger erforderlich. Im einfachsten Fall (den wir hier durchspielen wollen) nimmt es alle Events entgegen, die vom passenden Client (dem vorgefertigten Client namens "Universal Analytics") bereitgestellt werden.
Erwartungsgemäß ist auch die Liste der Triggertypen sehr übersichtlich: Es gibt genau einen Eintrag. Nach Auswahl kann bestimmt werden, ob alle Events (also alles, was an Daten von allen Clients entgegengenommen und zur Verarbeitung weitergereicht wurde) oder nur bestimmte Events zu verarbeiten sind. Da wir hier im Beispiel sowohl einen Client für Universal Analytics Hits als auch App + Web haben, sollte die Verarbeitung zumindest auf Daten des passenden Clients beschränkt werden.
Bedingtes Auslösen via Trigger
Das passiert auf die aus dem GTM bekannte Weise, indem eine Bedingung definiert wird, die von einer oder mehreren Variablen abhängt. Von denen gibt es im GTM Servercontainer nur sehr wenige, die vorgefertigt sind. Wie im Web-Container hier müssen diese erst aktiviert werden. Danach kann als Bedingung für den Trigger der "Client Name" mit dem Namen des vorgefertigten Clients verglichen werden. Ebenso könnten auf diese Weise bestimmte Events wie z. B. nur Seitenaufrufe oder Ereignisse mit besonderen Merkmalen in eine bestimmte andere Property (oder einen ganz andere Dienst mit einer API) gesendet werden, was eine ähnliche Flexibilität wie beim clientseitigen GTM-Container eröffnet, wenn man sich einmal in das Konzept eingedacht hat, nach dem die serverseitige Variante funktioniert.
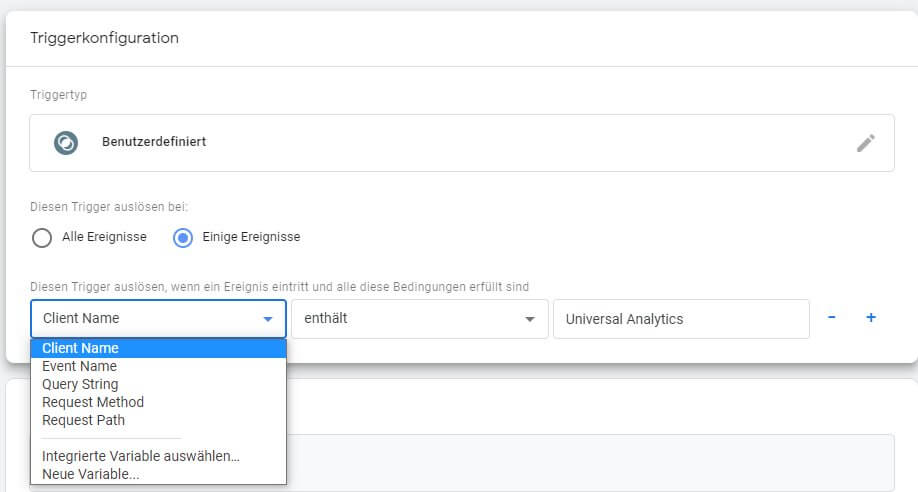
Damit ist die Aufgabe des "Durchreichens" von Universal-Analytics-Hits an den Analytics-Server abgeschlossen. Also: Vorschau aktivieren... und dann?
Verwendung der Vorschau
Sobald die Vorschau aktiviert wird, wird in einem separaten Tab ein mehr oder weniger vertrautes Vorschaufenster geöffnet... nur dass diesmal keine Website dahinter liegt. Es gibt Reiter für den "Request" und bekanntere Dinge wie Tags, Variablen und Fehler. Auch "Event Data" wird man sich dort ansehen können, wenn ein Request ankommt und von einem Client verarbeitet werden konnte. Jetzt aber ist die Summary und alles andere leer - ein Tracking-Aufruf muss her.
Bevor eine Website in die Lage versetzt wird, Hits an den Tag-Server zu senden, soll zunächst ein manueller Test ausreichen. Wir nutzen dazu das Google Analytics Measurement Protocol, um einen Seitenaufruf "zu bauen" und abzusenden.
Ohne den Tag-Server dazwischen würden wir unseren Hit direkt an https://www.google-analytics.com/collect senden - genau so, wie es der Google Analytics Trackingcode aus dem Browser machen würde.
Ein einfacher Seitenaufruf sieht dabei in etwa so aus:
https://www.google-analytics.com/collect?v=1&t=pageview&tid=UA-xxxxxxx-1&cid=42&dp=%2Fserverside-test1
Wer hier die Tracking-Id "UA-xxxxxxx-1" gegen die der eigenen Property austauscht und den Hit dann (mit der frei gewählten ClientId "42") durch Kopieren in die Adresszeile des Browsers und Aufrufen an Analytics sendet, sollte in der Echtzeit-Ansicht in Analytics - zumindest bei ungefilterten Rohdaten - einen Seitenaufruf für die Seite /serverside-test1 sehen.
Test-Hits an eigenen Tag-Server senden
Damit der eigene Tag-Server in´s Spiel kommt, müssen die gleichen Parameter (der "hit payload") statt direkt an Analytics an den passenden Endpunkt auf dem eingerichteten Tag-Server versendet werden. Dieser heißt auch /collect und findet sich auf der Domain des Tag-Servers. Das ist im Testbetrieb eine GCP Subdomain bei appspot.com nach dem Muster gtm-containerid-ein.paar.buchstaben.appspot.com oder die eigene Subdomain wie z. B. trk.meinedomain.de, wenn diese als Costom Domain wie oben beschrieben eingerichtet wurde.
Tauschen wir noch die 1 am Ende des Seitennamens gegen eine 2 aus, um auch diesen Hit in Analytics wiederzufinden. Die URL, die aufzurufen ist, um etwas in der Vorschau zu sehen, lautet dann also
https://gtm-containerid-ein.paar.buchstaben.appspot.com/collect?v=1&t=pageview&tid=UA-xxxxxxx-1&cid=42&dp=%2Fserverside-test2
Kleiner Tipp: Wer beim Absenden im Browser die Meldung "No client claimed the request." sieht, ist genau so schusselig wie ich und der Endpunkt ist falsch angegeben. Es gehört kein Slash hinter das "/collect" 😉 Auch andere Fehler wie "&" statt "&" bei den Parametern lösen diese Meldung aus.
Request und Ergebnisse im GTM-Debugger
Erreicht der Aufruf den Endpunkt auf dem eigenen Tag-Server, sieht man auch in der Vorschau, dass sich etwas getan hat:
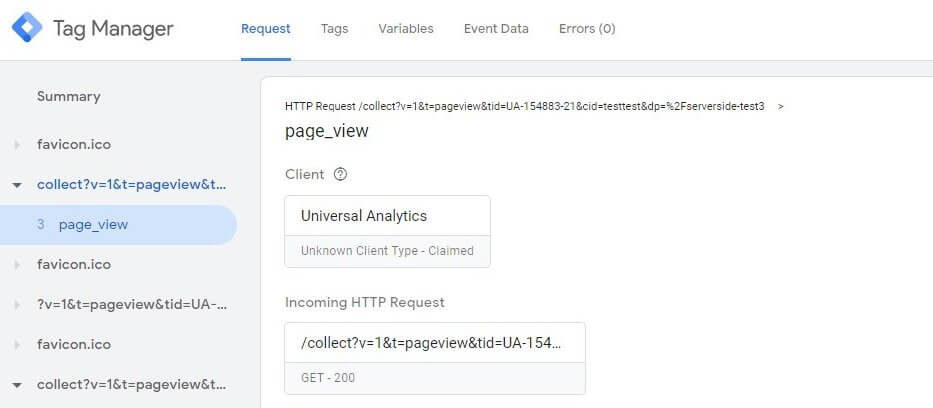
Man sieht (bei Aufrufen aus dem Browser gemeinsam mit der Anforderung des Favicon) in der Summary nun den Request und den daraus durch den Client generierten Seitenaufruf als Ereignis. Der eingehende Request wird im Detailbereich dargestellt und auch der Client, der diesen verarbeitet hat. Das fühlt sich nun schon mehr nach GTM Vorschau an. Der Request kann angeklickt werden, um die Details der Header etc. zu betrachten und auch der Client gibt auf Klick weitere Informationen preis. Das ist auf dem Reiter "Tags" mit dem ausgelösten Universal Analytics Tag viel spannender: Wie gewohnt sieht man hier Infos zum Tag, den feuernden Triggern oder bei nicht gefeuerten Tags die nicht erfüllten Auslöse-Bedingungen. Eben alles wie gewohnt, wenn es um das Debugging in komplexeren GTM-Setups geht.
Auf dem Reiter "Variables" zeigen sich die im GTM definierten bzw. aktivierten eingebauten Variablen und deren aktuelle Werte.
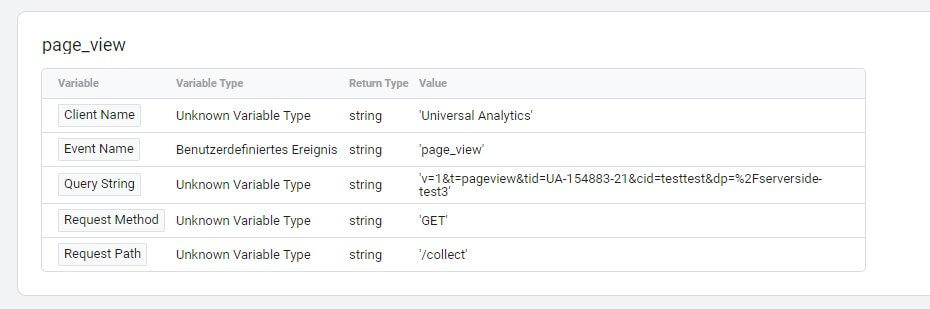
Und wenn alles richtig gelaufen ist, kann auf dem Reiter "Event Data" eingesehen werden, welcher Client den Request verarbeitet hat und was dabei an Daten im Event Model herausgekommen ist, über das die Daten vom Client an Tags weitergereicht werden.
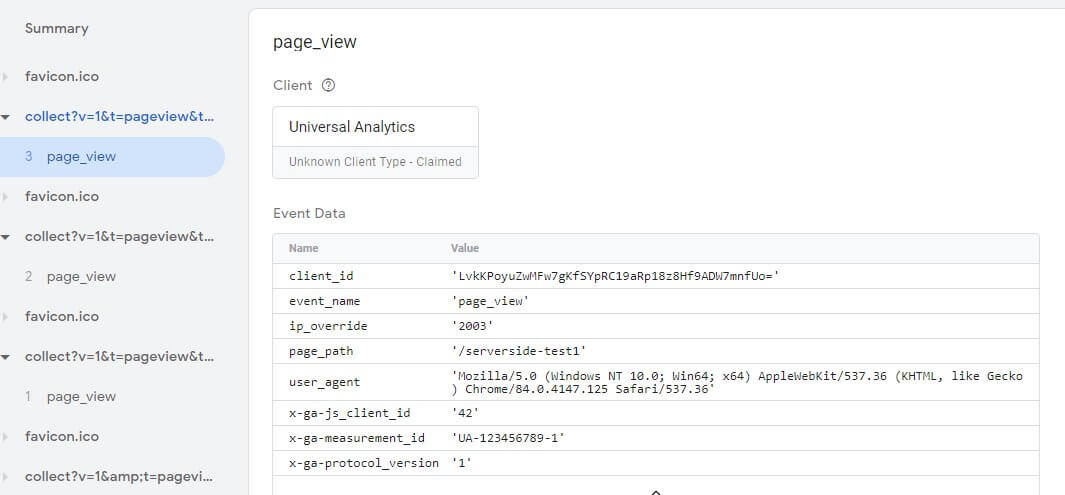
Der Seitenpfad und die einblendbaren Angaben zur Property-Id und der ClientId sind dabei ergänzt um Dinge, die wir nicht selbst gesendet haben. Diese stammen entweder (wie das ip_override") aus den Einstellungen des Tags oder wurden durch den Client erhoben und ergänzt, als der Hit über den Request empfangen wurde. Wie hier zum Beispiel der User Agent. Gut zu wissen: Die IP des Besuchers ist in diesem Setup zwar nicht dabei und der Hit kommt aus Sicht von Analytics später von der IP des Tag-Servers, aber der User Agent des Besuchers wird weitergegeben. Wenn er nicht im Client geändert oder entfernt wird (siehe unten).
Für einen Test soll dieser eine Hit reichen. Aber wie kommt der Tag-Server nun zwischen die Website und Analytics, um alle dort anfallenden Messpunkte zu verarbeiten und weiter zu geben?
Den Container füttern: Wo kommen die Aufrufe her?
Theoretisch kann man mit vertretbarem Aufwand - genau wie beim serverseitigen Tracking mit Analytics ohne GTM - seine Website in die Lage versetzen, einen selbst kontrollierten Satz an Informationen zu Ereignissen, Seitenaufrufen etc. an den Tag-Server zu senden. Mit einem selbst definierten Satz an Parametern und in beliebigen Formaten - selbst verschlüsselt. Diese Daten kann man am Tag-Server in einem eigenen Client auseinander nehmen, in das Event Model übersetzen und dann an Analytics Tags (oder andere) zur Verarbeitung weitergeben. Oder dabei die "Sprache" des Measurement Protocols beibehalten und den Standard-Client verwenden.
Clientseitige GTM-Container sind nicht tot!
Im echten Leben aber ist schon eine Website vorhanden und dort ist ein Google Tag Manager Container im Einsatz, der bereits jede Menge sorgfältig zusammengestellte Tags und Trigger enthält, um Daten an Analytics zu senden. Den ganzen Kram also neu bauen? Das ist zum Glück nicht erforderlich. Man kann alle oder einzelne Tags - separat oder via gemeinsamer Einstellungsvariable - dazu bewegen, Requests nicht mehr an den Analytics-Server, sondern einen eigenen Endpunkt zu richten. Faktisch also genau das zu tun, was oben im Test passiert ist: Die Domain austauschen und den Payload an einen anderen Endpunkt senden. Unser "/collect" auf dem eigenen Tag-Server.
Dazu dient bei Google Analytics das Feld "transportUrl" bzw. "transport_url" bei gtag.js. Will man im Testbetrieb des serverseitigen Trackings alle Seitenaufrufe der echten Website in eine Testproperty senden, fügt man einfach ein Universal-Analytics-Tag ein oder kopiert das vorhandene, tauscht die Property-Id aus und gibt den eigenen Tag-Server als "Transport-URL" an. In der erweiterten Konfiguration der Analytics-Tags findet sich ein passendes Feld dafür.
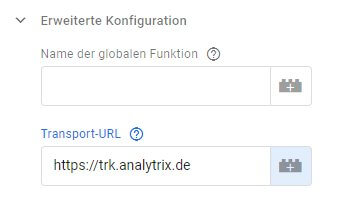
Achtung: Dabei den Endpunkt "/collect" nicht mit angeben; er wird automatisch hinzugefügt, wenn dieses Eingabe-Feld verwendet wird. Das ist anders, wenn man die oben genannten Felder zur Konfiguration bei der Initialisierung des Trackers verwendet.
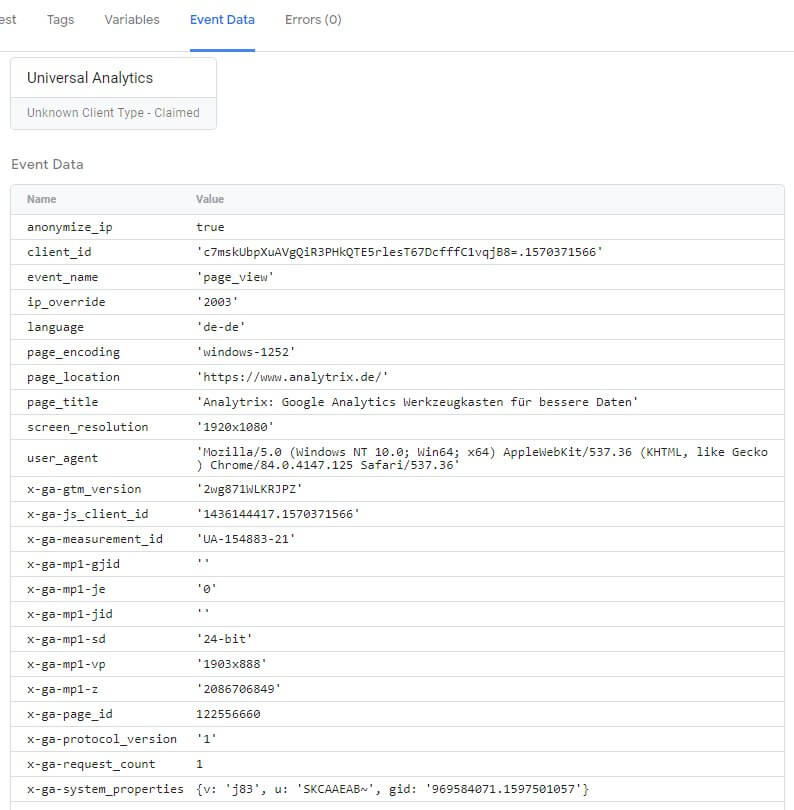
Speichert man das hinzugefügte Tag, welches Daten an den eigenen Server sendet, sobald man die betreffende Website mit aktiver Vorschau des clientseitigen Containers besucht, sieht man die eingehenden Requests in der Vorschau des serverseitigen Containers. Unter "Event Data" können die realen von der Website gesendeten Daten betrachtet werden, wie der Client sie hier bereitstellt.
Würde diese Umstellung nun für alle GA-Tags erfolgen und der Container veröffentlicht, würden keine Hits mehr direkt an GA gesendet, sondern alles über den eigenen Tag-Server laufen. Schön und gut. Aber: Ist Blockierung von Tracking durch die Browser damit schon kein Thema mehr? Was ist mit diesem Setup gewonnen?
Was können Clients für uns alles erledigen?
Beschränkt man sich auf das, was hier als Test durchgeführt wurde, sind viele der Tracking-Probleme, welche von Browsern verursacht werden, noch lange nicht aus der Welt. Vor allem deshalb nicht, weil immer noch ein Laden des Analytics-Scripts im Browser durch den clientseitigen Einsatz von Analytics erforderlich ist. Schließlich hat sich im Browser außer der Adresse, an die die Trackinghits gesendet werden, nichts geändert. Dem kann man zwar wie beschrieben dadurch begegnen, dass man seine eigenen Trackinghits "komponiert", aus dem Browser an den Tag-Server sendet und dort in einem eigenen Client verarbeitet... aber das ist im Zweifelsfall viel Arbeit.
Ein Ausweg aus der Tracking Blocker Falle kann es sein, das Trackingscript nicht mehr vom Google-Server zu laden, sondern dazu ebenso den Tag-Server zu verwenden. In seinem Video und Blogbeitrag zur Erstellung eines eigenen Analytics-Clients zeigt Simo genau dies am Beispiel von analytics.js. Die API, die zur Erstellung eines Clients verwendet wird, ist sogar speziell darauf vorbereitet. Das allein ist aber nicht der wesentliche Vorteil bzw. Gewinn an Flexibilität, die das Konzept der 1:n Clients beinhaltet, welche die ankommenden Requests verarbeiten und an Tags weiterreichen.
So wird bei Verwendung des vorgefertigten GA-Clients in Kombination mit nahezu unveränderten clientseitigen Containern nur wenig bis gar keine "JavaScript Last" vom Client genommen. Aber: Man kann eine ganze Menge an Verarbeitung, die bei komplexen Setups per JavaScript im Browser stattfinden, mit clientseitigen Containern übernehmen. Und wie angedeutet auch die Anzahl ausgehender Requests minimieren, wenn man einen Trackinghit verarbeitet und mehreren Endpunkten zur Verfügung stellt. Ob das mehrere Properties sind oder unterschiedliche Systeme; eine Datenbank für Rohdaten oder ein Data Warehouse... schon clientseitig sind schlauen Menschen jede Menge Dinge eingefallen und nun kann das ganze serverseitig eben auch stattfinden, ohne dass die Performance im Browser beeinträchtigt wird.
Eigene oder erweiterte Clients (und Tags) sind daher potentiell Ansatzpunkt für reichlich Innovationen, die in den nächsten Monaten das serverseitige Tag Management bereichern werden. Aufgaben werden sich damit aus dem Browser in den Client des Tag-Servers verlagern lassen. Daten, die sonst erst am Server ermittelt und dann via Datenschicht an den Client geliefert werden mussten (nur um dort dann beim Tracking dienlich zu sein), können u. U. nun direkt serverseitig ergänzt werden und sich den Ausflug in den Browser des Besuchers sparen.
Wie man an Simos Beispiel sieht, hat man dabei auch volle Kontrolle über das, was an Analytics gesendet wird. Cookies "härten", Daten reduzieren, PII Filter, Anreicherung von Dimensionen wie dem Spamschutzkennwort, ohne dieses auf der Website preisgeben zu müssen... Die Optionen sind fast unbegrenzt.
Davon abgesehen wird man ein komplexeres Tracking nicht allein auf Basis von GA-Hits aufbauen können oder wollen. Also werden neben neuen Clients, die Requests für andere Dienste von Websites entgegen nehmen können, auch Ergänzungen in den "normalen" GTM-Containern erforderlich werden, um passende Requests zur Erzeugung der Messpunkte via Tag-Server absetzen zu können. Vermutlich ebenso wiederum über clientseitige Tags. Da passiert also potentiell noch vieles - oder man macht sich jetzt schon an die Planung und Umsetzung von Clients und Tags, die exakt auf die eigenen Bedürfnisse zugeschnitten sind. Sei es als Nutzer oder auch als Dienstleister, Agentur oder Entwickler.
Jenseits von GTM / GA: Beliebige Requestformate, Clients und Tags
Das Absetzen von Requests an den Tag-Server ist nicht an einen clientseitigen GTM-Container gebunden - oder überhaupt an Google Analytics. Auch ist das Format der Event-Daten, die von Clients bereitgestellt und in Tags genutzt werden, vollkommen frei. Es können also sowohl Clients erstellt werden, die nur ganz bestimmte Daten weitergeben, als auch Tags generiert werden, die nur einen Ausschnitt der Daten eines Clients nutzen. Das bedeutet Unabhängigkeit, wenn es um Quelle von Informationen in Form eingehender Requests und deren anschließende Verarbeitung geht.
Jetzt starten?
Theoretisch kann man das - zumindest für das Google Analytics-Tracking - schon "produktiv" nutzen. Aber ohne echten Nutzen im Client zu stiften (entweder selbst entwickelt oder durch Verwendung eines durch Dritte bereits angepassten Clients) bringt der Einsatz bisher noch nicht viel. Außerdem: Die serverseitigen Container sind noch im Beta-Stadium, weisen eine noch unbekannte Stabilität auf und beschränken sich aktuell nur auf Google Analytics. Allein deshalb m. E. noch nicht reif für "echten Live-Betrieb".
Spielen, Erfahrungen sammeln und sich ggf. sogar auf der Live-Website in einer separaten Property mit Daten zu versorgen, erscheint (zumindest technisch) unkritisch. Jetzt vorhandene Setups aber komplett umzustellen ist aber i. d. R. unsinnig, selbst wenn man nur GA-Tracking im Tag Manager verbaut hat und nichts sonst an Tracking stattfindet. Zumal zu erwarten ist, dass es auch andere Optionen zum Hosting der serverseitigen Container geben wird. GCP ist toll, aber nicht für jeden die richtige (oder im Kontext der geltenden IT Policies mögliche) Wahl.
Update 04/2022: Natürlich ist diese Phase nun vorbei und die Landschaft der unterstützten Dienste ist wesentlich gewachsen. Ein eigener Tracking-Endpunkt über diesen oder einen anderen Weg gehört längst zu einem robusten und modernen Tracking-Setup. Im 121STUNDENtalk habe ich dazu weitere Details mit den Moderatoren besprochen.
Potential heben wird Aufwand bedeuten
Um die "volle Kontrolle" über übertragene Daten durch Senden der Tracking Hits vom eigenen Server zu übernehmen, kommt man an einem eigenen Client nicht vorbei. Das ist in Umsetzung und Testing deutlich komplexer, als die vergleichsweise einfache Implementierung rein clientseitigen Taggings via GTM. Simo zeigt in seinem Beitrag zur Client-Entwicklung eindrucksvoll, welche Flexibilität geboten wird... aber auch, wie hürdenreich z. B. die eigene Verwaltung einer ClientId oder die Anpassung von GA-Hits nach eigenen Vorstellungen ist, wenn man keine entsprechenden Ressourcen hat, um einen "Wunschclient" zu entwickeln. Dabei geht es nicht nur darum zu wissen, wie man solche Clients erstellt, codiert und testet. Ohne das Wissen, wie die zu übertragenen Daten gestaltet sind und welche Informationen der Trackingdienst in welcher Form wirklich braucht, kann man so bestenfalls "alles durchreichen". Spätestens jenseits von GA-Tracking werden also neue Clients und Tags über die Community erforderlich sein, um auch bei Facebook & Co. evtl. mehr Kontrolle über Umfang und Inhalt versendeter Daten zu erhalten. Das wird sicher alles passieren, aber noch Zeit brauchen. Ich habe daher zur Entwicklung eigener Templates für den serverside Tag Manager ein E-Book erstellt, in dem anhand von Beispielen erklärt wird, wie Templates im GTM funktionieren und was man damit anstellen kann.
Alternativen bei begrenztem Einsatz (noch) einfacher
Wem es "nur" darum geht, Trackinghits statt direkt an Analytics lieber zuerst an den eigenen Server zu senden und dann von dort unverändert oder ähnlich angereichert mit Dimensionen und / oder befreit von User Agent und IP des Websitebesuchers weiterzureichen, der ist mit einem selbst erstellten eigenen Endpunkt (auf dem eigenen Server), auf den per "transportUrl" verwiesen wird, vermutlich besser bedient. Selbst inkl. der "Härtung" des _ga-Cookies (oder Nutzung eines eigenen, serverseitigen Cookies für die Id) ist das mit wenigen Zeilen PHP zu erledigen, die man dann einfach selbst auf dem bestehenden Server bereitstellt, ohne auf GCP und / oder eine Tracking-Subdomain ausweichen zu müssen.
Der ganze "Overhead" des serverseitigen GTM-Containers macht sich erst dann bezahlt, wenn die hier eher in Nebensätzen beschriebenen Stärken wirklich ausgenutzt werden. Was einfacher wird, wenn vorgefertigte Lösungen für die typischen "Trackinganforderungen" einer Website auch jenseits von Google Analytics zur Verfügung stehen.
Erinnerung: Server Side <> Dark Side
Abschließend bitte nicht vergessen: Ob und wie das Thema "Consent" durch die Verwendung dieser weiteren Schicht der Daten auf dem Weg von Website zu Trackingdienst beeinflusst wird, liegt ganz daran, was nun im Verborgenen so alles auf dem Server stattfindet, nachdem dieser durch die Website mit einem Trackinghit aus dem Browser angesprochen wurde. Wenn dies denn überhaupt noch wirklich im Client stattfindet, denn auch das ist ja nicht zwingend für alle Messaufgaben erforderlich. Das ist nicht neu, aber durch die Verfügbarkeit einer Lösung zum serverseitigen Tracking via Google Tag Manager wird das Thema Fahrt aufnehmen, während es zuvor eher etwas für Nerds und / oder technisch versierte IT Abteilungen war. Ob dieser veränderte Fokus auch mehr Sicherheit bei der Einschätzung dessen bringen wird, was unter welchen Bedingungen "okay" ist und was nicht? Wir werden es sehen...