Wie sieht ein "ideales Tracking Setup" heute aus?
In Beratungsprojekten, in denen so etwas wie ein “Neustart” ansteht, stoße ich in jüngerer Vergangenheit immer häufiger auf die Frage nach dem besten Setup für das Tracking. Aus technischer Sicht betrachtet und jenseits von Pixel- und Messplänen. Noch vor zwei Jahren habe ich i. d. R. geantwortet: “Google Tag Manager, Analytics und alle Marketing-Tags, die Du so brauchst darüber ausspielen. Passt schon.”
Unter Berücksichtigung aller Aspekte wie DSGVO, ePrivacy & “Cookie-Consent”, ITP und andere Trackingschutzmaßnahmen, Performance und Flexibilität ist das heute deutlich zu einfach. Was also kann und sollte man tun, um den geänderten Rahmenbedingungen zu begegnen? Um es gleich zu benennen: Wir brauchen eine Customer Data Platform (CDP) in der einen oder anderen Weise. Vielleicht sehr eindimensional und einfach, aus ein paar Zeilen Code bestehend... aber wir kommen nicht mehr daran vorbei, eine Schicht zwischen Datensammlung und Trackingdienst einzuziehen. Viele Themen wie Cookies, serverseitiges Tracking, Marketing-Automation etc. laufen an diesem Punkt zusammen.
Während in den meisten Szenarien durch Pflichten, Policies oder Rahmenbedingungen Einschränkungen in der Wahl der Mittel ganz von selbst entstehen, möchte ich mit diesem Beitrag einige Aspekte zusammentragen, die m. E. auch in “einfacheren” Setups heute in gewissem Umfang Berücksichtigung finden müssen. Es sei mir verziehen, dass ich hierbei die zusätzliche Komplexität umgehe, die App Tracking oder weitere Datenquellen in die Gleichung einbringen. Wir beschränken uns lieber “nur” auf das Web.
Schlachtfeld Data Collection
Das Thema der Datenerfassung auf einer Website (AKA “Trackingcode einbauen”) beschränkt sich heute nicht mehr auf das Hinzufügen weiterer Tags zur Website. Ob direkt oder mittels eines Tag Managers: Zu viele Dinge können dabei schief laufen und der Website Ladegeschwindigkeit tut es auch nicht gut. Daher steckt hier großes Potential für Optimierung der Stabilität und Performance eines Tracking Setups.
Um dem Problem “maximal effizient” zu begegnen, würde man für alle Anwendungsfälle und alle Trackingaufgaben auf eine einzige, (evtl. proprietäre) Lösung setzen. Diese wäre:
- beschränkt auf die Daten, die
- wirklich benötigt werden
- im Rahmen der Zustimmung zu diesem Zeitpunkt gesammelt werden dürfen
- 100% First Party
- “hard to block”
- 100% browserstabil
Für viele Trackingaufgaben braucht man dazu aus dem Client gar nicht viel, das aktiv gesammelt werden muss. Die aufgerufene Seite oder die Daten des aufgetretenen Events wie Kategorie etc., evtl. die verweisende URL und ein paar Metadaten wie das aktuelle Produkt o. Ä. Und möglicherweise irgendeine Form von Id (dazu unten mehr). “Luxus” ist dann schon fast die aktuelle Auflösung des Browsers - viel mehr sammeln viele Tracker gar nicht. Selbst umfangreichere Systeme wie z. B. Segment erfassen nichts anderes, wenn es um die Datensammlung von einer Website geht. Die Besonderheit steckt in solchen CDP eher in der Verbindung zu anderen Datenquellen, den Werkzeugen zur Datenverarbeitung - und möglichst vielen gängigen Empfängern von Daten.
Leichtgewichtig? Ist machbar!
Schaut man sich das Tracking Script von derzeit viel Zulauf erhaltenden Lösungen wie Plausibe Analytics an, sind das meist nur ein paar Byte. Keine Kilobyte - nicht mal eins. Da ist der Code selbst mit Zoom locker im Browser einsehbar.
![]()
Natürlich kann das Ding nicht viel mehr als Seitenaufrufe, Events und History Changes (damit auch SPAs einfach vermessbar bleiben) und Transaktionen oder sonstige Scherze würden etwas mehr Code erfordern. Aber man kann sich damit gut vor Augen führen, dass eine eigene Data Collection kein Hexenwerk ist. Oder dem exemplarischen einfachen “Logger Format”, das ich auch in anderen Beispielen schon verwendet habe. In etwas aufgebohrter Form kann auf dieser Basis schnell alles abgedeckt werden, was ein typisches Tracking-Setup braucht. Im Video demonstriere ich diesen Weg:
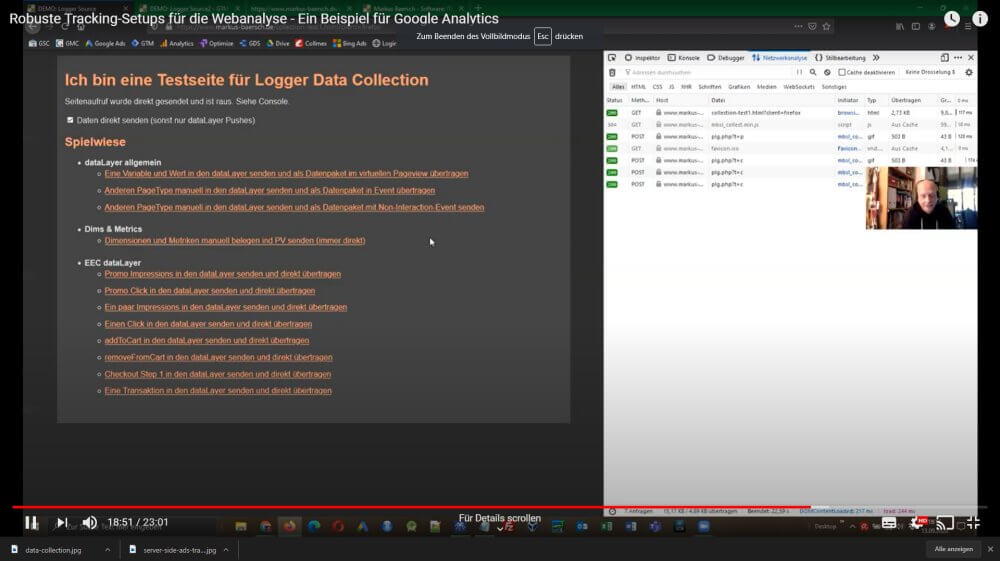
Einen großen Unterschied macht es aber schon heute, ob ein solches Script aus einer externen Quelle geladen werden muss oder dem eigenen Server stammt. Nur weil Dienst A, B oder C derzeit nicht im Fokus der Schutzmaßnahmen steht, muss das nicht immer so bleiben. Daher ist ein Script aus dem eigenen Kontext ein wesentlicher Aspekt.
Wem eine eigene Datensammlung für mehr als nur Seitenaufrufe und Events zu aufwändig erscheint, kann auch auf... naja... "unsensiblere" fertige Lösungen zurückgreifen. So ist es z. B. bei Matomo denkbar einfach, die Hits nicht direkt an den lokalen Endpunkt zu senden, sondern durch einfache Anpassung des Trackingcodes an eine eigene Verarbeitungsstelle. Von dort aus geht es dann ggf. weiter an Matomo. Die URL liegt sowohl direkt im selbst einzufügenden Trackingcode oder im Matomo Tag Manager als Einstellung offen.
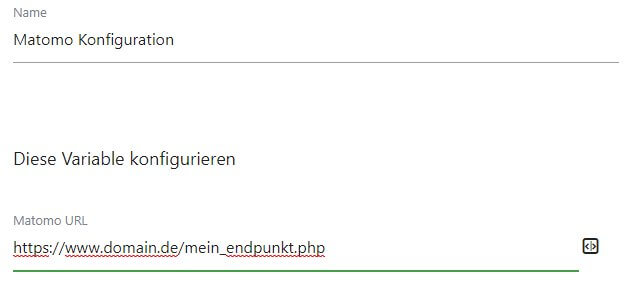
Wie man dem Ansatz seiner Wahl dann nutzt, um neben der Webanalyse auch andere Systeme wie Ads, Conversion Tracking, Facebook, LinkedIn & Co. zu füttern oder nicht, bestimmt wesentlich mit, wie komplex und pflegeintensiv die nächste Stufe wird: Das Verarbeiten und Verteilen der Daten.
Erkennung der Besucher
Cookies sind ein Problem. In jedem Szenario. Nicht umsonst hat Google Analytics viele Optionen, um eine “fremdverwaltete” Identität zu nutzen. Daher ist selbst bei einer Datensammlung über das normale Trackingscript von Google Analytics vorgesehen, eine selbstverwaltete ClientId zu verwenden und diese entweder aus einem serverseitig gesetzten Cookie im Consentfall oder ggf. auch kurzlebigen Identitäten wie Session Ids o. A. zu nutzen.
Wie man also in einem Tracking-Setup eine Wiedererkennung der Besucher regelt, liegt ganz an den Anforderungen und der vielzitierten “Consent-Lage”. Und ob man nun bei fehlender Zustimmung überhaupt noch auf Google Analytics setzen will oder lieber einen anderen Trackingdienst mit den gesammelten Daten versieht - oder in welchem Umfang dann weitergegeben werden, ist keine technische Frage und daher kann diese hier auch nicht beantwortet werden. Klar ist aber: Auch ohne Zustimmung muss nach wie vor “irgendwas” gesammelt werden (können). Sendet man dann reduzierte Daten an GA? Oder das nach eigener Aussage auch bei cookiefreiem Betrieb trotz Fingerprinting “alleskonforme”Matomo? Technisch gesehen ist diese Frage zweitrangig. Aus Sicht der Nutzbarkeit der Daten freilich aber nicht.
Mit Kurzzeitidentitäten ist Attribution i. d. R. über den jeweiligen Besuch hinaus Schluss. Selbst Systeme, die cookiefrei arbeiten und daher aus IP und / oder anderen Merkmalen einen Hash bilden, dessen Würze sich täglich ändert, erlauben (das ist ja der Witz dabei) keine langfristigen Betrachtungen, Customer Lifetime Values, Attributionsmodelle, Aktivierung der Daten im Bezug auf den Besucher und künftige Besuche oder andere Dinge in dieser Richtung. Deshalb aber auf alles andere auch zu verzichten, ist nicht die richtige Lösung.
APIs für eigene Sammlung und Verarbeitung
Nur wenn ein Trackingdienst eine API anbietet oder die bei der eigenen Sammlung ausbleibenden Aufrufe aus dem Browser des Besuchers sonstwie auch von einem Server entgegennehmen können, ist dieser Weg nutzbar. Das geht zum Glück mit vielen Anbietern; nicht nur Google, Bing, Facebook oder Matomo gehören dazu. Gerade im Bereich der Webanalyse sind serverseitige Versorgung mit Daten nicht ungewöhnlich. Dennoch mag es sein, dass nicht alle Dienste, die man anbinden möchte, über die eigene Datensammlung bedient werden können. Das ist aber kein Drama:
Hybrid-Ansatz
Es ist in vielen Fällen ohnehin sinnvoll, sich bei der eigenen Data Collection auf die Daten für die Webanalyse zu beschränken und Facebook & Co den entsprechenden clientseitgen Standard-Tags zu überlassen und diese nur dann auszuspielen, wenn die entsprechenden Zustimmungen erteilt wurden. Dabei muss aber berücksichtigt werden, dass diese dann wieder auf die Performance drücken und den Trackingschutzmaßnahmen unterworfen sind.
Will man also auch andere Trackingdienste - wenigstens z. B. im Bereich von Conversiontracking - möglichst vom Browser “entkoppeln”, wird das Thema der Erkennbarkeit eines Besuchers für den jeweiligen Trackingdienst zum Dreh- und Angelpunkt. Click-Ids von Facebook und Google Ads z. B. erlauben auch eine Verarbeitung von Events (nicht nur, aber auch z. B. Transaktionen) zur Erfolgsmeldung via API, ohne dass dazu unbedingt die entsprechenden Trackingcodes im Client geladen werden müssen.
Fallbacks einplanen
Eine robuste Lösung könnte also z. B. die entsprechenden Basiscodes der besagten Dienste im Client ausspielen (freilich nur wenn Consent besteht), um z. B. das Cookie-Management der Trackingdienste zu nutzen und die Identifizierung / Zuordnung der gesendeten Events darüber zu ermöglichen. Besteht Consent, aber ist keine Id verfügbar - weil der Browser diese Daten z. B. gefressen oder das Script ungeachtet der Zustimmung nicht geladen hat -, kann dann auf Ersatzmittel wie die Click-Ids zurückgegriffen werden, wenn diese zu dieser Zeit noch irgendwo “leben” und so beim API Aufruf des Trackingdienstes weiterverarbeitet werden können.
Kontrollierte Weitergabe an Tracker
Wer selbst Daten auf der Website sammelt und diese ggf. auch mit serverseitig aktiv oder passiv erhobenen Informationen kombinieren möchte, muss wie schon angesprochen die unter den gegebenen Bedingungen nutzbaren Informationen selbst an die Trackingdienste weitergeben. Das passiert in der Regel über APIs.
Die “Logik”, die auf dem eigenen Server erforderlich ist, kann dabei sehr einfach oder unglaublich komplex ausfallen. Was wiederum nicht unbedingt erforderlich macht, mit dem serverseitigen Google Tag Manager zu arbeiten. Ein paar Parameter und Daten aus der eigenen Sammlung zu übersetzen und dann per Measurement Protocol an Google Analytics zu senden, ist auch so kein Problem. Meint: Mit welchen technischen Mitteln man an dieser Stelle arbeitet, ist eher zweitrangig. CDP, GTM, PHP, Java, Node.js… vollkommen egal. Wichtig ist vielmehr das, was man dann mit den Daten anstellt:
- Validierung von Daten
- Anreicherung durch serverseitg erhebbare Informationen in eigenen oder bestehenden Dimensionen, statt diese den Umweg über den dataLayer in den Client und zurück machen zu lassen
- Reduktion von Daten oder Auslassen von Tracking bei fehlendem Consent
- gezielte Weitergabe an die angebundenen Dienste per API
Beispiele für typische Aufgaben
Dabei sind einige Dinge auf diese Weise sehr einfach zu erledigen, welche sonst mit mehr Aufwand im Browser und / oder durch Filter in Google Analytics angegangen werden müssen. Darunter:
- Ausschluss interner IP Adressen - am Server mit Vergleich von Listen interner fester und vollständiger IPs vor dem Versand eines Hits mit entsprechendem Marker - oder zur Not einfach gar nicht - ist deutlich einfacher an dieser Stelle
- Identifikation: Härten des _ga-Cookies oder nutzen einer nur serverseitig lesbaren ID sind hier schnell implementiert, statt Umwege und Extra-Aufrufe dafür zu opfern
- Erkennung von Bots: Wenngleich viele Merkmale von rendernden Bots erst im Browser sichtbar werden, können zumindest anhand von User Agents "bekennende" Bots und rendernde Tools hier direkt ausschließen oder "sonderbehandeln" (das sind mehr als man denkt)
- Ergänzung von Dimensionen: konstante oder am Server bekannte bzw. zu ergänzte Dimensionen wie Spamschutz-Kennwort, Session-IDs, ClientID, Zeitstempel des Hits, User Agent oder was immer man in seinem Setup derzeit im GTM hinzufügt, ist hier potentiell auch zu erledigen. Meist sogar mit weniger Aufwand
- Rückgewinnung von Daten: Seit die ISP-Domain in Analytics "not set" ist, gibt es viele Beispiele, mit denen die Information über APIs abgerufen wird. Das passiert schon jetzt am Server und geht noch den Umweg über die Datenschicht oder belastet den Client, wenn der API Aufruf dort geschieht
- IP-Anonymisierung, PII-Filter: Selbst anonymisierte IP als Parameter gegen Schutz falscher Konfiguration und / oder festes Setzen des aip-Parameterwerts vor dem Versand der Hits sowie ersetzte Daten wie Mailadressen in den Parametern sind hier viel einfacher zu regeln
- Bereinigung: Weg mit den ganzen "ü"s und anderem Müll aus den Seitentiteln, Labels etc. Oder überflüssige Parameter. Groß- Kleinschreibung bei Quellmedien... Alles Kontrollaufgaben ohne großen Aufwand, statt Filter in Google Analytics.
- "Server-Side Custom Tasks": Viele der o. a. Dinge werden schon jetzt gern mit customTasks in Google Analytics geregelt. Viel JavaScript bei jedem Hit, das im Browser ausgeführt wird. Von den derzeit 12 Aufgaben, die in Simo Ahavas Custom Task Builder konfiguriert werden können, bleibt nur die iFrame-Dekoration übrig. Alles andere geht auch - z. T. einfacher - serverseitig. Korrektur der Zuordnung organischen Traffics? Geht auch hier statt im Browser.
Weitere Ideen, was man mit Informationen anstellen kann, bevor diese an Analytics gesendet werden, zeigen z. B. Simos Client-Beispiele für den serverseitigen Google Tag Manager. Nicht alles, aber vieles davon ist auch ohne den GTM Tag Server umsetzbar.
Zugegeben: Es wird Last aus dem Browser genommen, dafür aber auf den Server verlagert. Je nach Auslastung und Kapazität kann dieser Mehraufwand zur Belastung werden, der man lieber auf einen separaten Server begegnet. Solange das im First Party Kontext passiert und man keine externe eigene Trackingdomain dafür aufsetzt, ist das aus Sicht der Datensammlung und deren Zuverlässigkeit nicht wesentlich.
Wenn das nicht ausreicht
Modernes Marketing benötigt oft etwas mehr als Webanalyse und Conversiontracking. Füttern von Marketing-Automations-Tools, Remarketing, Testing... es gibt viele Bereiche, die heute noch bevorzugt im Browser des Besuchers stattfinden (müssen). Die Bildung von Zielgruppen, Aktivierung von Daten, Anreicherung mit Informationen aus Backendsystemen etc. ist nichts, was man ab einem gewissen Umfang mit selbst gebastelter Logik auf dem Server abdecken möchte. Spätestens an dieser Stelle kommen etablierte Customer Data Platform - Lösungen (mehr zum Thema CDP von Marcus Stade im Metrika Podcast) ins Spiel, wenn man die Orchestrierung der Daten effizient, nachvollziehbar und für mehrere Nutzer verfügbar machen möchte. Wobei man auch dort genau darauf achten sollte, wie die Datensammlung genau stattfindet. Ein Drittanbieter-Script einer Drittanbieter-CDP kann über die gleichen Steine stolpern wie die Datensammlung eines direkt eingebundenen Trackers. Wenn man nur Daten auf der Website erheben, "moderat umformen", validieren und dann weitergeben möchte, ist der Einsatz einer großen Plattform aber zum Glück gar nicht nötig.
Was bringt das Ganze?
Wie komplex oder einfach eine individuelle Lösung auch aussehen mag: Wir kommen nicht umhin, einen Schritt zwischen Datensammlung und Trackingdienst(en) einzufügen. Der zusätzliche Aufwand erlaubt es uns, vor allem die folgenden kritischen Punkte behandeln:
- Verringern von Abhängigkeit von Third Party Code bei der Datensammlung (Stabilität, Zuverlässigkeit)
- Vermeiden von redundanter Sammlung von gleichen Informationen im Client durch mehrere Trackingscripts (Performance, Zuverlässigkeit)
- Orchestrierung und gezielte Weitergabe der Daten (Kontrolle)
Primäres Ziel ist also, aus einem eingehenden Datenstrom von Trackingdaten der Website (inkl. ggf. Cookie Werten und allem, was ein Aufruf so im Header etc. mit sich bringt) einen kontrollierbaren Datenfluss zu verschiedenen Trackingdiensten zu gewährleisten. Für alle, die Bilder mögen: So visualisiert Segment ein Setup, bei dem aus einem Datenstrom mehrere Dienste versorgt werden:
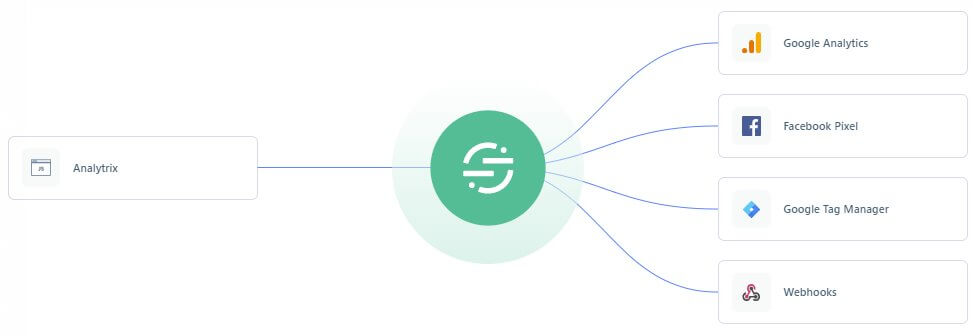
Selbst wenn man dieses Ziel “nur” für die Webanalyse anstrebt, ist die Antwort “GTM, GA und fertig” nicht gültig. War sie nie. Auch der GTM ist für die “Minimaldatensammlung” ggf. schon zu unzuverlässig. Wenn man dieses Gespann nicht mit direkt implementiertem Code zur Data Collection kombinieren möchte: spätestens bei der Identität ist in Form eines möglichst stabilen und langlebigen Cookies in Zeiten von ITP & Co. ein Minimum an “Serverarbeit” erforderlich. Es sei denn, man möchte sich mit dem zunehmenden Schwund an Daten abfinden, der vermehrt nicht nur durch fehlende Zustimmung, sondern auch erschwerten Rahmenbedingungen im Browser verursacht wird. Nachdenken über Alternativen zum Tag Manager und / oder Verzicht auf das Standard Trackingscript von Google Analytics ist deshalb durchaus erlaubt. Technische Lösungen, die im Rahmen der eigenen Trackinganforderungen die Hits im Client bauen und dann direkt an Analytics oder eine “lokale First Party-Brücke” auf dem eigenen Server sendet, müssen nicht aufwändig sein. Eine Teillösung ist besser als gar keine Behandlung dieser Punkte. Sogar unter der Einschränkung, dass sie nicht für die Ewigkeit halten mag… der alte “Standard” langt heute einfach oft nicht mehr. Sorry 😉