Woran erkennt man serverseitiges Tracking?
Mit der steigenden Verbreitung von serverseitigem Tracking und serverseitigem Tagging höre ich vermehrt die Frage, woran man erkennen kann, ob jemand serverseitig Daten erhebt oder nicht.
Die kurze und vereinfachte Antwort ist: “An nichts. Es geht nicht”. Jedenfalls für den Fall, dass wirklich ein hundertprozentiges serverseitiges Tracking stattfindet. Das ist aber eher selten der Fall und daher verdient diese Frage auch eine ausführlichere Antwort.
TL;DR
Serverseitiges Tracking kann so gestaltet werden, dass es für den Besucher im Browser nicht erkennbar ist. Das Tracking basiert dabei i. d. R. ausschließlich auf den Anfragen, die vom Browser des Besuchers an den Webserver der besuchten Site gestellt werden. Das ist aber nur eine mögliche Variante. Üblicher und verbreiteter ist serverseitiges Tagging. Hierbei wird i. d. R. wie bei normalem clientseitigen Tracking per JavaScript oder Pixel ein Trackingaufruf vom Browser erzeugt, der erkennbar ist. Er wird allerdings nicht vom Browser direkt an einen Trackingdienst, sondern einen First Party Tracking-Endpunkt des Website-Anbieters gesendet und dort serverseitig weiter verarbeitet. In welchem Umfang Verarbeitung stattfindet, bleibt auch in dieser Variante nicht erkennbar für den Besucher.
Serverside Tracking vs. Serverside Tagging
Beide Begriffe klingen nicht nur ähnlich, sondern sind je nach persönlicher Definition auch mit mehr oder weniger großen Schnittmengen versehen. Der Kernunterschied ist, dass bei serverseitigem Tracking i. d. R. nichts davon “zu sehen ist”, soweit es einen Browser und davon ausgehende Requests betrifft. Denn es findet nicht nur eine direkte Kommunikation des Servers der Website mit dem des Trackingdienstes statt (das ist kein Unterschied zum serverside Tagging), sondern es wird auch kein Impuls “von außen” benötigt, also z. B. aus dem Browser des Besuchers der Website.
Serverside Tracking
Ein einfaches Beispiel verdeutlicht dies: Wenn in einem Shop ein Bestellabschluss stattfindet, weiß das Shopsystem dies auch, ohne dass es durch einen Trackingcode vom Browser gemeldet wird. Es ist also problemlos möglich, die Transaktion direkt vom Shopsystem initiiert ohne Umwege an einen Trackingdienst wie Google Analytics oder andere Empfänger zu senden.
Genau das passiert auch in vielen Fällen. Sei es eine Meldung einer Transaktion an eine zusätzliche Datenbank oder tatsächlich an ein (Analyse-)System, dass durch eine API direkt angesprochen werden kann. Google Analytics hat dazu das Measurement Protocol, Facebook seine Conversions API und viele andere Dienste betreiben oder entwickeln gerade Schnittstellen, über die Daten auch serverseitig angeliefert werden können, die üblicherweise sonst direkt vom Browser des Besuchers stammen.
Das geht freilich auch mit allen Ereignissen wie Seitenaufrufen, die der Server / das CMS / das Shopsystem in Form von Anfragen mitbekommt. Während es hier deutlich komplizierter sein kann, einen echten Besucher von einem Bot zu unterscheiden, als es auf einer Bestellabschluss-Seite ist (die üblicherweise wirklich nur von echten Besuchern aufgerufen wird), ist der Mechanismus dennoch der Gleiche. Meint: Auch alle Seitenaufrufe sind problemlos zu 100% serverseitig zu tracken, ohne dass man davon im Browser etwas sehen kann.
Solange man sich damit zufrieden gibt, beim Tracking auf alle weiteren Dinge wie Events, Scroll-Verhalten und andere Aktionen, die nicht zu Anfragen an den Webserver der besuchten Site führen, zu verzichten, kann man also vollkommen unsichtbar tracken. Zumindest technisch. Was und wie viel man dabei sammeln kann, ohne nach einer Zustimmung des Besuchers zu fragen, sprengt hier den Rahmen. Aber da bei dieser Methode zwar viele Dimensionen wie Auflösung des Browsers und andere Dinge nicht ermittelt werden können, sind IP-Adresse und User Agent auch für rein serverseitiges Tracking ebenso sichtbar wie URL der Seite, Cookies, Referrer etc.
Serverside Tagging
Normalerweise besteht ein typisches Tracking - sei es zur Webanalyse oder auch Marketing - aus mehr als Seitenaufrufen und vielleicht auch Transaktionen. Nicht nur für “sonstiges” Event-Tracking, sondern auch Aufrufe von Seiten bringt ein “clientseitiges” initiieren des Trackings viele Vorteile. Hier kommt serverseitiges Tagging ins Spiel. Dabei gibt es immer noch ein Trackingscript, dessen Arbeit man im Browser beobachten kann. Soll etwas gemessen werden, wird ein Hit an einen Tracking-Endpunkt gesendet. Genau wie bei “normalem” Tracking. Allerdings liegt hier der Endpunkt nicht mehr bei einer Drittpartei wie dem Tracking-Anbieter (unter google-analytics.com im Fall von GA), sondern steht unter der Kontrolle des Anbieters der Website. Es ist also - mal mehr und mal weniger - der Server, der auch die Website ausliefert, die gerade besucht wird, welche den Hit entgegennimmt.
Verarbeitung wie bei reinem serverseitigen Tracking
Die dort geschehende Verarbeitung unterscheidet sich dann nicht mehr von derjenigen, die oben bei rein serverseitigem Tracking beschrieben wurde. Nur sind hierbei dann auch die im Browser gesammelten Informationen zu verarbeiten wie z. B. der Größe des Viewports, Bildschirmauflösung, ggf. installierte Plugins und alles andere, was per JavaScript ermittelt werden kann.
Der o. A. “Impuls” für das Versenden einer Nachricht an einen Trackingdienst kommt aber wie beschrieben beim serverside Tagging nicht mehr direkt aus dem System selbst bzw. “vom Server”, sondern wird vom Browser des Besuchers an den Tracking-Server gesendet und dann dort weiterverarbeitet. Das Verfahren nutzt wie "klassisches" clientseitiges Tracking Anfragen aus dem Browser, die man “sehen” kann, z. B. in der Netzwerkübersicht der Entwickerkonsole. Diese öffnet man im Chrome z. B. am Einfachsten über die Taste F12. Auf dem Reiter "Network" sind alle ausgehenden Anfragen des Browsers zu sehen, wenn man die aktive Seite neu lädt (z. B. via STRG+F5).
Daten im Browser erheben
Datensammlung im Browser für einen eigenen Tracking-Endpunkt / Tracking-Server kann auf verschiedenste Weise passieren. Die für Google Analytics Tracking zuständige Bibliothek gtag.js kann zum Beispiel so konfiguriert werden, dass sie Daten nicht mehr direkt an den Analytics-Server, sondern einen beliebigen anderen Endpunkt sendet. Die folgende Abbildung zeigt so ein Beispiel. Er ist zwar "alt" und nicht im Format für Google Analytics 4, aber das Prinzip bleibt gleich: Der Hit sieht wie ein typischer Google Analytics - Request aus, geht aber an einen First Party Endpunkt. Was danach damit passiert? Man kann es nicht sehen.
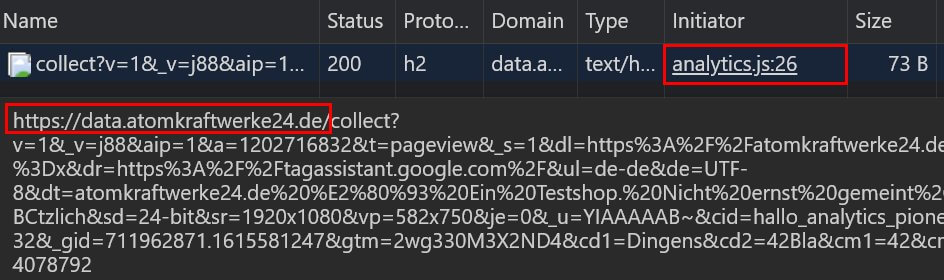
Anderen sieht man es vielleicht gar nicht an, dass hinter dem Tracking-Aufruf mehr steckt, als man vermuten kann. So im Fall von Matomo, wo der Endpunkt ohnehin immer auf dem Server des Betreibers liegt. Woher soll man also wissen, was vielleicht dort sonst noch mit den Daten passiert? Bauernregeln wie "Matomo = alles sauber / Google Analytics = Datenschutzkatastrophe" verlieren damit ihre Gültigkeit; zumindest aus technischer Sicht.
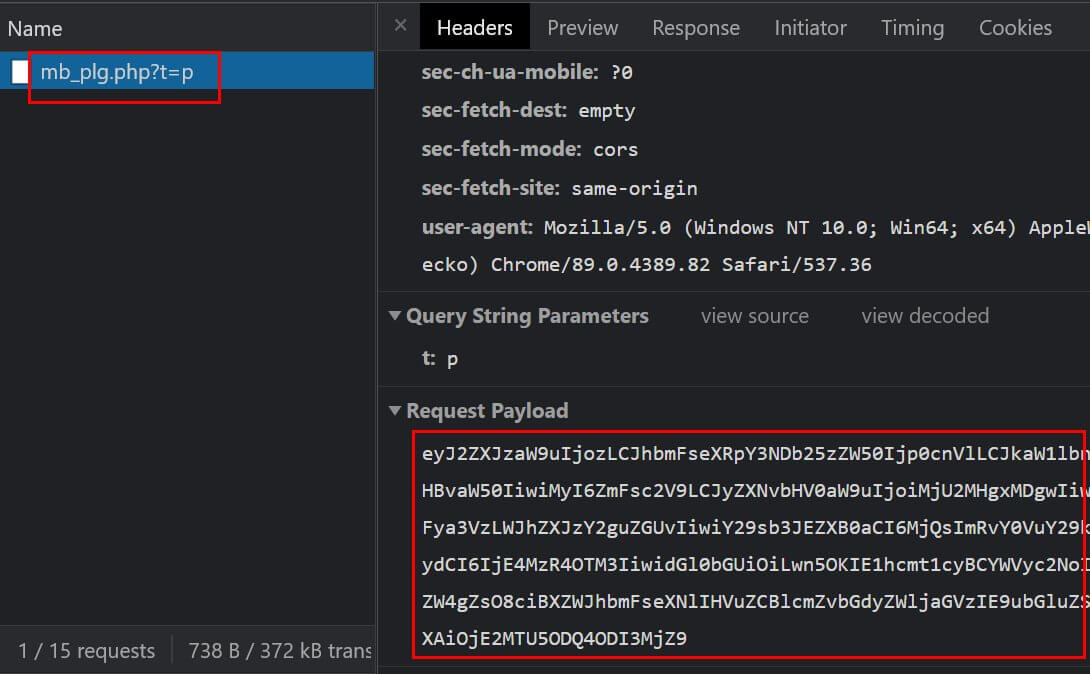
Auch kann Datenerhebung auf der Website nicht zwingend an einem bestimmten Satz von Parametern in den ausgehenden Anfragen des Browsers erkannt werden. Im folgenden Beispiel wird ein Trackingaufruf an (m)einen lokalen Endpunkt gesendet. Die dabei übergebenen Daten wie Auflösung des Browsers, Seitenpfad, Eigenschaften von Ereignissen jenseits von Seitenaufrufen und andere Dimensionen stecken in der "Nutzlast" des Aufrufs und sind zudem codiert, so dass man diese nicht als Klartext lesen kann.
Und es geht noch einfacher: Serverseitiges Tagging kann, wenn man mit einem reduzierten Umfang an Daten leben kann, bei der Datensammlung im Browser aus einem ganz normal aussehenden Aufruf einer Ressource wie einem Bild, einer CSS-Datei oder jeder anderen beliebigen Datei bestehen. Unabhängig davon, ob diese mit ".js", ".jpg", ".css" oder wie auch immer endet, ist jederzeit eine serverseitige Verarbeitung mit PHP und anderen Mitteln möglich, so dass hierüber serverseitig ausgeführtes Tracking stattfinden kann. Man sieht keine auffälligen Parameter, Nutzlasten oder sonstige Spuren. In der Praxis ist diese Methode nicht üblich, aber technisch umsetzbar. Wahrscheinlicher ist es, dass serverseitiges Tracking als Teil einer CDP (siehe z. B. Customer Data Platform" bei Wikipedia) wie Segment angebunden wurde oder ein serverseitiger Google Tag Manager im Einsatz ist. Damit…:
One Web Data Stream To Rule Them All
Bei beiden Spielarten des Trackings über den eigenen Server steht neben Vorteilen wie Stabilität des Erhebung, Kontrolle über Dimensionen, Datenqualität etc. ein besonderer Punkt im Fokus: Die Fähigkeit, mehr als einen Dienst mit Daten zu versorgen, ohne dazu für jeden einzelnen Anbieter ein eigenes Script im Browser des Besuchers platzieren zu müssen.
Selbst bei serverseitigem Tagging ist es also nicht zu sehen, welche Daten wirklich wohin übertragen werden. Im Zusammenhang mit Consent Management wird die ganze Nummer nicht transparenter, denn selbst wenn eine Datensammlung auch dann stattfinden sollte, obschon keine Zustimmung gegeben wurde, bedeutet dies nicht unbedingt, dass der Betreiber der Website etwas Unerlaubtes tut. Denn wenn der Endpunkt, an den die Daten aus dem Browser gesendet werden, unter der Kontrolle des Website-Betreibers steht, kann (und wird hoffentlich auch) dort entschieden, was mit den eingehenden Daten im Rahmen des Consents (der aus einem Cookie oder im Hit mit gesendete Information bekannt ist) geschehen soll.
So kann ohne Consent zur Webanalyse z. B. wie oben beschrieben immer noch ein “Analytics-Hit” an den Tracking-Endpunkt des Website-Betreibers gehen, werden aber eben von dort nicht an Google Analytics gesendet. Möglicherweise nutzt der Server die Information aber dennoch, um das Ereignis z. B. in eine Datenbank zu schreiben oder im Fall einer Transaktion einen Slack Channel zu benachrichtigen. Alles also im Rahmen der Zustimmung, aber eben nicht mehr “vom Browser aus” nachvollziehbar.
Spätestens bei Verwendung eines nicht so verbreiteten Scripts zur Datensammlung, bei dem man ggf. auch nicht unbedingt anhand der Parameter der ausgehenden Requests erkennen kann, dass es sich um Tracking handelt, ist also auch das Erkennen von serverseitigem Tagging nicht unbedingt auf den ersten Blick möglich.
Fazit: Jein
Die Länge des Beitrags unterstreicht vor allem eins: Die Antwort ist komplexer als ein einfaches “Nein” oder “an diesem und jenem”. Generell kann ein vollkommen unsichtbares serverseitiges Tracking stattfinden. Es ist nur (noch) nicht weit verbreitet, weil die Verwendung einer clientseitigen Datensammlung nach wie vor viele Vorteile bietet.
Ausgehende Requests an einen erkennbaren oder gut getarnten Endpunkt auf dem eigenen Webserver können ein Anzeichen von Tracking sein, müssen wie beschrieben nicht bedeuten, dass wirklich ein Tracking für einen oder auch einhundert Dienste stattfindet.
Auch die Existenz oder Abwesenheit von Cookies hilft in dieser Frage nicht viel. Beides kann beides bedeuten. Tracking ist nicht auf Cookies angewiesen… und Cookies können auch ohne Tracking vorhanden sein. Selbst “fremde” IDs, die von einem System wie Google Ads, Facebook und anderen an URLs gehängt werden, wenn Besucher auf eine Website geleitet werden, sind mit entsprechendem Aufwand ohne sichtbare Spuren im Browser rein serverseitig für eine theoretisch unbegrenzte Zeit speicherbar und können verwendet werden, um Tracking-Ereignisse an die jeweiligen Anbieter für den Besucher unsichtbar zurück zu senden. Solange Betreiber sich dabei im Rahmen des rechtlich Erlaubten, der Zustimmung der Besucher und des Datenschutzes bewegen, ist auch nichts dagegen einzuwenden. Anders als rein clientseitiges Tracking ist es aber tatsächlich technisch so einzurichten, dass es nicht erkannt werden kann. Ja: das ist gruselig.
Zum Glück ist das aber alles nichts Neues. Es wird nur in der nächsten Zeit deutlich mehr “serverseitig getrackte Dinge” geben - soviel ist in Zeiten von ITP, Trackingschutz und dem Sterben von 3rd Party Cookies zu erwarten. Vielleicht ist es an der Zeit, dass wir Standards bekommen, nach denen Anbieter in einem nachvollziehbaren Format darüber informieren können, was genau serverseitig mit gesammelten Daten passiert. Aber mal ganz ehrlich: Wie soll man sicherstellen, dass diese Angaben stimmen? Und wer wird sie überhaupt lesen? Schon jetzt sind Datenschutzhinweise voller Zeugs, dazu Consent Dialoge... wer will da ernsthaft noch eine Liste serverseitiger Verarbeitungen lesen, von der man nicht einmal weiß, ob sie richtig und vollständig ist? Ich bin skeptisch, ob wir so wirklich mehr Transparenz in die Sache bekommen. Bleibt also nur Vertrauen. Und je nachdem, was man im Web so anstellt - zum Beispiel mit sensiblen Daten -, ist Vorsicht angebracht. Aber auch das ist nichts Neues 😉