Analytics Ghost Spam Revival mit "trafficbot.live" etc. - Ein Strohfeuer?
Hinweis: Dieser Beitrag stammt aus Februar 2021 und analysiert eine Ghost-Spam-Welle ("trafficbot.live" etc.) in Universal Analytics auf Basis von über 400 UA-Properties. Seit Juli 2023 ist Universal Analytics abgeschaltet; der über das offene Measurement Protocol mögliche Server-to-Server-Ghost-Spam existiert in Google Analytics 4 in dieser Form nicht mehr. Auch der im Beitrag erwähnte Spam-Check bei Analytrix wurde mit der UA-Abschaltung eingestellt. Der Beitrag bleibt als Zeitdokument erhalten.
Anfang Februar war er auf einmal wieder Thema: Der schon totgeglaubte Ghost Spam in Google Analytics. Anders als in der "ersten Welle" mit Peak zum Jahresende 2015 sind es diesmal verschiedene Dimensionen und nicht nur der Referrer, die betroffen sind. Als Quelle, Medium, Seitenpfad, Referrer oder Keyword tauchen "traffic-bot.xyz", "bottraffic.icu" und viele ähnliche Varianten unerwünschter Weise in Google Analytics auf. Was tun?
Filtern? Verweisausschlüsse? .htaccess?
Genau wie damals sind es die Tipps aus der Überschrift, die man in diesem Zusammenhang auch jetzt wieder liest. Zusammen mit dem Ausschluss bekannter "Bots und Spider" in den Einstellungen der Datenansicht. Ein Schutz in der .htaccess ist aus ähnlichen Gründen wie die alten Hostname-Filter aber unwirksam - zumal dieser ins Leere greift, wenn der eigene Server gar nicht im Spiel ist. Und das gilt auch dieses Mal für den Löwenanteil des Spams. Er kommt wirklich über die Website, sondern direkt über das Measurement Protocol vom Spam-Server an Analytics gesendet wird. Dabei ist er deutlich besser gemacht als früher, aber immer noch nach dem gleichen Prinzip.
Während einige Filter auf Seitenpfade oder Hostnamen in diesem Fall u. U. einen gewissen Wert haben, da die Anzahl der hierbei verwendeten Domains nach aktuellem Stand überschaubar ist, waren die o. g. Option oder gar die Verweisausschlussliste noch nie die Antwort, denn damit ändert man nichts daran, dass die Daten in Analytics ankommen.
In dieser Spam-Generation ist auch nicht mehr der Hostname, sondern bevorzugt andere Dimensionen wie Keywords, Pfade oder Quellmedium-Angaben betroffen - und explizit nicht der Hostname oder Referrer. Daher bleibt das Einrichten von Filtern, die sich explizit gegen die genannten Einträge per Mustervergleich richten
- eine mühselige Angelegenheit
- fehleranfällig und mit Potential zur Datenvernichtung versehen
- unvollständig
- arbeitsintensiv
Außer Anbietern von Lösungen, wie sich mal mehr und mal weniger automatisch aktualisierenden Filterlisten wie dem Analytics Toolkit und anderen (dieser Link ist explizit keine Empfehlung), kann daher niemand diesen Ansatz ernsthaft für optimal halten. Oder dauerhaft sinnvoll. Es gibt aber eine Ausnahme (siehe unten): Die Browsergröße scheint - zumindest in dieser Welle - nicht besetzt zu sein, so dass hier ein entsprechender Filter tatsächlich fast alles fernhalten kann... oder nachträglich als Segment angewendet auch die bereits betroffenen Daten in Analytics davon bereinigt. Das Schöne an einem Filter (oder einem Segment) zum Ausschluss von "(not set)" als Browsergröße ist, dass man damit kaum etwas falsch machen kann, denn "valider" Traffic bringt dieses Merkmal eigentlich immer mit.
Nach wie vor eine gute Idee: Ein "Spamschutzkennwort"
Im Gegensatz zu den deutlich schwieriger zu vermeidenden Spuren von Headless Browsern und rendernden Bots in der Webanalyse kann man "echtem" Ghost Spam auch immer noch wirkungsvoll dadurch begegnen, dass man Hits, die wirklich vom Tracking auf der eigenen Website ausgelöst werden, mit einem Merkmal versieht, das Spam üblicherweise nicht aufweist. Eine benutzerdefinierte Dimension mit einem konstanten "Spamschutz-Kennwort" kann diesen Zweck erfüllen. Wenngleich man damit nicht gegen Spam gewappnet ist, wenn dieser z. B. die ausgehenden Hits der eigenen Website explizit nachbildet, ist dieses Mittel recht wirkungsvoll, weil Spam eben selten "zielgerichtet" ist.
Wir groß ist das Problem und was tun?
Das Spamschutz-Kennwort allein scheint auch diesmal nicht genug zu sein; jedenfalls nicht für alle betroffenen Properties. Erstens ist dieses Mal der Anteil von "Nicht-Ghost-Spam", also über Headless Browser, die die betroffene Website wirklich "besuchen", relativ hoch. Er erscheint auch neben den unterschiedlichen Zieldimensionen für die zweifelhaften Botschaften in Form von Domainnamen eine große Varianz bei anderen Dimensionen zu geben wie Land, Browser, Sprache etc. Das spricht dafür, dass hier ein (Bot-) Netzwerk realer Geräte im Spiel ist. Speziell dieser Part ist schwierig zu behandeln und so mag einem Betroffenen wirklich nichts anderes übrig bleiben, als zumindest gegen künftige Spuren etwas mit anderen Filtern als nur dem Spamschutz-Kennwort zu arbeiten. Was aber schwierig sein wird. Denn:
Die derzeit beobachteten Domain-Namen, die als Muster für die Erkennung und Behandlung dienen können, werden bald schlichtweg nicht mehr auftauchen. So war es 2015 (nicht alle haben so lange "gespammt" wie semalt.com) und so scheint es auch dieses Mal zu sein. Ich habe mir dazu mit entsprechenden Mustern, mit denen auch der aktualisierte Spam-Check auf Analytrix funktioniert, die Daten von über 400 Universal Analytics Properties angesehen und dabei eine offenbar sehr kurze Lebensdauer der "bot-traffic.xyz"-Varianten gefunden.
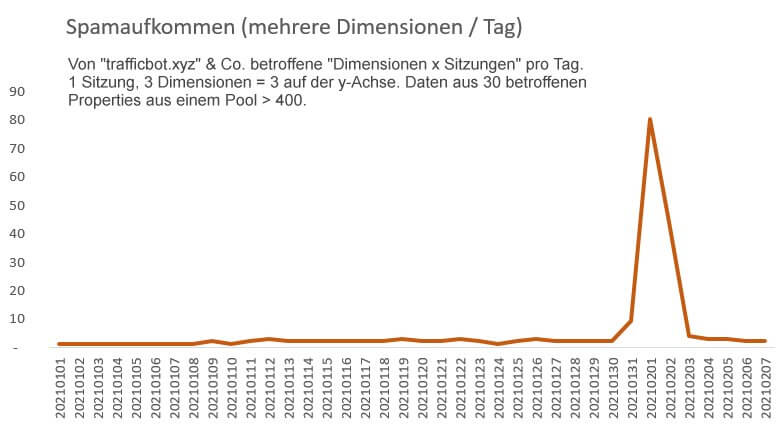
Die hierbei betroffenen Dimensionen waren:
- Quelle / Medium (111 betroffene Sessions)
- Keyword (43)
- Seitenpfad (43)
- Verweispfad (4)
Die Varianten der Domainnamen, die dabei als Treffer in den Daten gefunden wurden sind hauptsächlich diese hier:
- trafficbot.live
- trafficbot.life
- bottraffic.live
- bot-traffic.icu
- bot-traffic.xyz
Ich habe zwar "auf gut Glück" auch noch ein paar andere gefunden wie casinogamesjkk.com und auch ein paar nach dem Muster irgendwas4free.xyz, aber diese sind nur für das Grundrauschen um den 1.2. aus der obigen Grafik gut und daher m. E. nicht belastbar. Das Problem ist also eher zu wissen, nach welchen Mustern man suchen soll, wenn es keine zuverlässigen Gemeinsamkeiten der Spam-Hits oder Lücken in einer bestimmten Dimension gibt, die auch bei einer Standard-Implementierung auffallen würden. Aktuell ist dies tatsächlich wohl noch die nicht gesetzte Browser-Größe: Aus den in die oben angefertigte Analyse einfließenden Sitzungen mit Spam hatte nur ein Bruchteil von weniger als 1% hier einen Wert vorzuweisen. Es war zudem mit ziemlicher Sicherheit anhand anderer Dimensionen erkennbar ein Kandidat aus der Gruppe der Headless Browser, also kein Ghost Spam via Measurement Protocol. Dumm nur, dass schon beim nächsten Mal auch diese Lücke leicht geschlossen werden kann und die Version genauso wie der Browser selbst oder andere Dimensionen "natürlich" und nicht stets konstant belegt ist.
Die wesentliche Frage ist also: Wird es bei dieser Episode bleiben oder war das nur ein Testlauf für mehr Spam... mit anderen und wechselnden "Werbebotschaften" und damit wieder ein Problem? Und wie kann man damit umgehen?
Zumindest gegen den "Ghost-Anteil" kann man (eben auch prophylaktisch) mit einer Arbeitsdatenansicht inkl. Spamschutz-Kennwort und Filter arbeiten. Gegen Headless-Browser helfen die im oben verlinkten Beitrag angesprochenen Mittel wie der BotMarker oder reCAPTCHA ebenso bis zu einem gewissen Maß. Gegen bereits angerichteten Schaden in den Daten um den 1.2. herum helfen leider nur Segmente, die diese Sitzungen ausschließen. Dummerweise bedeutet das auch Arbeit in Reporting-Tools wie Data Studio für alle, die sonst den Empfängern der Reports erklären müssen, warum hier - je nach eigenem echten Traffic - ein solcher Anstieg zu sehen ist. Auch eine Anmerkung in Google Analytics kann helfen, dieses Phänomen auch noch in ein paar Monaten sicher zu erklären, ohne sich die Ursache wieder in den betroffenen Dimensionen erklicken zu müssen.
Ausblick
Wenn ich Spammer wäre, würde ich mir die ganze Mühe nicht machen, nur um an einem einzigen Tag eine Welle zu machen, die nicht nur im US-Raum, sondern auch bei uns in den Daten zu finden ist. 30 betroffene Properties von ca. 400 untersuchten fast ausschließlich deutschen Websites spricht m. E. jedenfalls dagegen. Ob es nun bei traffic-bot.life und seinen Freunden bleibt oder schon jetzt die nächsten falschen Daten einlaufen, ohne dass wir es so einfach sehen, bleibt diese Frage unbeantwortet. Ich werde jedenfalls für die kommenden Wochen die Untersuchung fortführen, die zur obigen Verlaufskurve geführt hat. Im Idealfall war das wirklich nur ein kurzer Scherz, im schlimmeren ein Testlauf.
Solange wir mit Universal Analytics arbeiten, wo über das recht offene Measurement Protocol einfacher "Server-to-Server-Spam" möglich ist, werden wir das Thema vermutlich nie ganz los werden. Google Analytics 4 wird diesen Weg zum Glück unmöglich machen. Wie gut in GA4 von Google direkt etwas dagegen unternommen werden kann, werden wir erst wissen, wenn sich GA4 ausreichend durchgesetzt hat. Ich werde damit starten, Bot-Scoring von UA und GA4 zu vergleichen und hoffe darauf, in GA4 schlichtweg weniger von diesem Mist zu sehen. Denn Hoffnung stirbt ja bekanntlich zuletzt 😐