Google Analytics: Bots und Spider ausschließen
Hinweis: Dieser Beitrag stammt aus Oktober 2015 und beschreibt die Datenansicht-Option "Bots und Spider ausschließen" in Universal Analytics. Seit Juli 2023 ist UA abgeschaltet, in Google Analytics 4 gibt es diese Option nicht mehr - Bot-Filterung läuft dort automatisch im Hintergrund und ist nicht konfigurierbar. Die grundsätzliche Erkenntnis, dass bekannter Bot-Traffic einen deutlichen Anteil des "Direct"-Topfs ausmacht, bleibt aber richtig. Wer heute mehr Kontrolle über die Bot-Filterung braucht, findet aktuellere Ansätze im Beitrag zur serverseitigen Erkennung rendernder Bots. Der Beitrag bleibt als Zeitdokument erhalten.
In den Einstellungen einer Datenansicht in Google Analytics findet sich schon seit einiger Zeit die Option "Alle Treffer von bekannten Bots und Spidern ausschließen". Ich muss zugeben, diese recht lange ignoriert zu haben. Vielleicht weil mich absolute Zahlen wenig interessieren und ich i. d. R. auf ein Rauschen ohne große Ausreißer hoffe. Also den idealen "Messfehler": Konstant und bei Betrachtung von Tendenzen und Kennzahlen im Kontext eher irrelevant. Aber stimmt das eigentlich?
Den letzten Schubser habe ich von Michael Janssen bekommen, als er sich mit den gängigen Mythen rund um Referral Spam auseinandergesetzt hat. Denn auch in diesem Zusammenhang liest man gern, dass die Option zum Ausschluss von Bots und Spidern hier helfen soll. Wirklich? Ich habe da eher auf "Nein" getippt und wollte es genauer wissen
Hilfe? Nicht hilfreich!
Schaut man in der Hilfe zu Analytics bei den Hinweisen zu den Einstellungen der Datenansicht nach, wird man nicht schlauer:
"Bot-Filterung: Aktivieren Sie diese Option, um Sitzungen bekannter Bots und Spider auszuschließen."
Ja, super. Danke auch. Die englische Fassung ist ebenso keine Hilfe: Bot Filtering: Select this option to exclude sessions from known bots and spiders.. Siehe oben.
Auch sonst findet sich nur wenig zu der Option. Allerdings hat das Analytics-Team dazu an anderer Stelle ein paar erhellende Worte verloren, unter anderem bei Google Plus (Link nicht mehr möglich, weil G+ verstorben ist).
Der wichtige Part:
"... exclude all hits that come from bots and spiders on the IAB know bots and spiders list. The backend will exclude hits matching the User Agents named in the list..."
Aha. Es geht also "nur" um bekannten Traffic von sich entsprechend im User Agent outenden Maschinen, die auf der IAB-Liste zu finden sind. Ich habe zwar keinen Einblick in diese Liste (das wäre auch teuer), aber es ist davon auszugehen, dass es hier eher um Crawler und Bots von verbreiteten und bekannten Systemen geht (Similarweb gehört ganz sicher dazu ;)). Nicht um knöppe-für-websites.irgendwo & Co. Damit wäre das Thema "Referral Spam" wohl vom Tisch. Ich habe deren Requests zwar noch nie gesehen, aber wenn ein identifizierbarer User Agent String zu sehen wäre, würde mich das sehr wundern. Analytics zeigt in Datenansichten ohne diese Option auch nichts, was diese Meinung ändern würde. Außer vielleicht neben "not set" hier und da "PTST" - den "Browser" von webpagetest.org und anderen, die durch die Option abgefangen werden, wenn sie denn aktiviert ist. Referral Spam kommt aber freilich immer noch durch. Ganz andere Baustelle!
Woher kommt der ganze "Direct Traffic"?
Für diese Frage ist die Option viel relevanter. Denn mit der Option ausgeschlossener Traffic landet sonst in einem übergroßen "Direct"-Topf, bei dem man sich auch schon mal bei unreflektierter Betrachtung zu Unrecht auf die Schulter klopft. Hat man doch den internen Traffic mühselig ausgeschlossen, um "echte" Besucher zu zählen. Hier kann die Option zu Bots und Spidern bei einzelnen Sites wirklich einen nennenswerten Unterschied ausmachen.
Auswirkungen des Ausschlusses
Bleibt noch zu klären, wie groß das Rauschen durch diese Bots ist und welchen Schwankungen der Traffic unterworfen ist. Ich habe mir dazu Datenansichten von ca. 20 Websites unterschiedlicher Größe angesehen, die ich eigens dazu gleich nach Michaels Beitrag angelegt hatte. In diesen Vergleichsprofilen wurde nur die Option aktiviert und ansonsten keine weiteren Filter angewendet, um diese mit den vorhandenen "Rohdatenprofilen" zu vergleichen.
Das Ergebnis liefert leider keinen klaren Trend und auch keine besonders belastbaren Fakten. Aber: Kleine Sites haben i. d. R. auch weniger Traffic aus diesen Quellen als größere... aber dafür kann der prozentuale Anteil maschineller Besucher dort schnell Überhand gewinnen, wenn man bei zwei oder drei fleißigen Tools auf der Liste steht. Der Unterschied ist fast überall spürbar. Der Anteil der ausgefilterten Sitzungen über 2 Wochen schwankte im Testfeld zwischen 2 bis zu knapp 60 Prozent; eine Null war bei meinen Kandidaten gar nicht dabei (mag es aber geben). Leider ist der Zeitraum mit weniger als 30 Tagen nicht besonders lang - dass es dennoch messbare Unterschiede gibt, spricht aber für einen deutlichen Nutzen der Option.
Ein Beispiel, das ich für zumindest typisch für viele Websites halte, zeigt die Auswirkungen auf den direkten Traffic. Dazu zuerst ein Blick auf die Verteilung der Trafficquellen aus dem ungefilterten Profil:
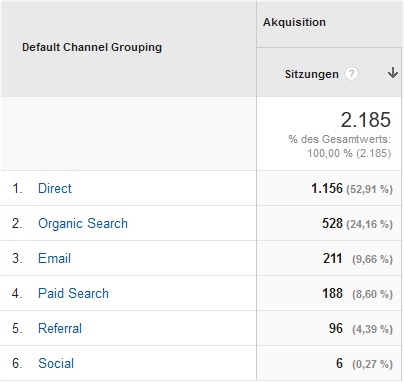
Sieht man sich den gleichen Zeitraum im Vergleichsprofil an, wird der Anteil der direkten Besuche deutlich reduziert und schon steht ein anderer Kandidat auf dem ersten Rang:
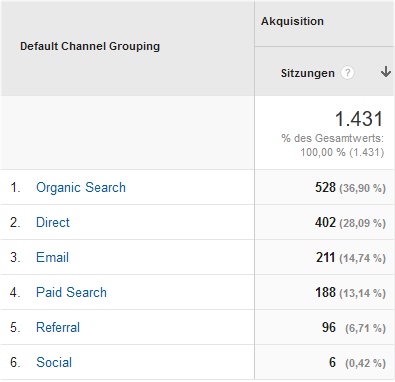
Sind diese Zahlen nun richtig? Natürlich nicht. Absolute Zahlen in der Webanalyse stimmen eigentlich nie. Aber die Werte sind zweifelsfrei "richtiger". Auch andere Kennzahlen wie Absprungrate, Besuchstiefe und Verweildauer sind von der Filterung betroffen und geben das tatsächliche Verhalten ohne Bots zweifelsfrei besser wieder. Die Verwendung in einem Arbeitsprofil sollte also auf jeden Fall Pflicht sein.
Schwankungen in den Werten sind definitiv nicht zu vernachlässigen. Auf Tagesbasis schwankt der Anteil der Bots, die im Topf "Direct" enthalten sind, anhand der hierbei untersuchten Daten zwischen 0% und 95%. Oder anders gesagt: an machen Tagen kommt gar kein Bot vorbei, an anderen kaum jemand anderes.
Dazu Zahlen aus Analytics zur Veranschaulichung. Zu sehen sind die direkten Besucher des Gesamtprofils und des gefilterten Vergleichsprofils. Daraus berechnet werden Anzahl und Anteil der Bots im direkten Traffic:
| Datum | Gesamtprofil | Gefiltert | -> Bots | Anteil Bots |
| 24. Sep | 143 | 52 | 91 | 64% |
| 25. Sep | 136 | 50 | 86 | 63% |
| 26. Sep | 107 | 14 | 93 | 87% |
| 27. Sep | 104 | 13 | 91 | 88% |
| 28. Sep | 123 | 37 | 86 | 70% |
| 29. Sep | 140 | 59 | 81 | 58% |
| 30. Sep | 133 | 48 | 85 | 64% |
| 01. Okt | 124 | 41 | 83 | 67% |
| 02. Okt | 125 | 30 | 95 | 76% |
| 03. Okt | 105 | 11 | 94 | 90% |
| 04. Okt | 107 | 17 | 90 | 84% |
| 05. Okt | 134 | 63 | 71 | 53% |
| 06. Okt | 142 | 49 | 93 | 65% |
| 07. Okt | 101 | 48 | 53 | 52% |
| 08. Okt | 51 | 46 | 5 | 10% |
Fazit und Empfehlung
Das gezeigte Ergebnis mag nicht jeden überraschen; ich hatte aber mit einem weniger wankelmütigen Messfehler gerechnet. Die Auswirkungen auf absolute Zahlen bzw. Trends sowie der Größe des Direct-Segments sind zum Teil enorm. Zum Wohl der Daten sollte man die Option daher nicht übergehen. Traffic von Bots, die sich mit dieser Einstellung abdecken lassen, sollten auf jeden Fall ausgeschlossen werden.... nur eben nicht mit dem Ziel, damit Referral Spam loszuwerden. Dazu sind nach wie vor individuelle und regelmäßig zu ergänzende Filter erforderlich, bis Google sich endlich etwas Skalierbares dazu einfallen lässt.