Das Measurement Protocol: Dem Googlebot zuschauen (serverseitiges Tracking)
Dieser Beitrag ist Teil einer Artikelserie zum Measurement Protocol. Diesmal geht es wieder um den Kern von Analytics: Echte Webanalyse. Nur schauen wir nicht (nur) auf reale Besucher, sondern primär auf Bots, die sich naturgemäß sonst aus der Sache gern heraushalten. Statt Spambots auszuschließen, laden wir diesmal also Crawler ein, sich von uns über die Schulter schauen zu lassen.
Alle Teile dieser Serie
- Überblick und Anwendung
- Praxistipps und Einsatzmöglichkeiten
- LifeLogging mit IFTTT
- Transaktionen stornieren per Refund-Event
- Serverseitiges Tracking: Dem Googlebot zuschauen
Serverside: Vor- und Nachteile
Wie im zweiten Beitrag angesprochen, kann man mit serverseitigem Tracking eine Menge Probleme umgehen. Nicht nur, aber auch das aktive Blockieren von Trackingmaßnahmen und die "Unsichtbarkeit" des Trackings sind für viele ein schlagendes Argument, auf diese Variante zu setzen.
Dafür werden Dinge plötzlich zu Problemen, die von Anbietern in diesem Bereich unterschiedlich angegangen werden müssen, während das clientseitige Tracking per JavaScript davon kaum betroffen ist. Der Cache des Browsers ist ein solcher Kandidat, denn eine vorher besuchte Seite wird damit nicht neu vom Server abgerufen, während das JavaScript-Tracking den Hit davon unbeeindruckt an die Webanalyse sendet. Proxies, CDNs etc. kommen als weitere Problemquellen dazu. Da wir uns hier aber nicht mit Problemen, sondern neuen Einsatzgebieten des Measurement Protocols befassen wollen, schieben wir diese Punkte erst einmal beiseite. Die meisten Sites betreiben ohnehin klassisches Tracking und auf diese Zahlen wollen wir auch gar nicht verzichten.
Serverside Tracking mit dem Measurement Protocol: Einsatzmöglichkeiten
Seitenaufrufe und Sitzungen der gleichen Website zu vergleichen, die sowohl client- als auch serverseitig gesammelt wurden, kann ungeachtet dieser Einschränkungen interessante Einblicke gewähren. Außerdem bekommen wir am Server alle Hits mit; also auch die vom geliebten Googlebot und anderer Besucher. Deren Spuren bleiben oft in nie ausgewerteten Serverlogs verborgen - das soll hier mit Hilfe von Google Analytics geändert werden.
Kein Ersatz für Logfileanalyse
Das folgende Beispiel soll möglichst alle Hits erfassen, die Seiten betreffen, welche von einem PHP-basierten CMS ausgeliefert werden. Das kann z. B. WordPress sein. Alles andere wird allerdings dabei bewusst nicht abgedeckt. Nun besteht eine Website aber aus einer ganzen Menge an weiteren Dingen wie Bildern, Scriptfiles, CSS-Dateien, PDFs, Downloads und mehr. Während sich in einem Serverlog alle Zugriffe auf diese Ressourcen nachverfolgen lassen, beschränken wir uns auf "CMS-Inhalte" im weitesten Sinn. Durch andere Ansätze, die direkt am Server implementiert werden, können solche Lücken zwar geschlossen werden, aber im Sinne eines möglichst einfachen Beispiels begnügen wir uns mit dem, was das CMS ausliefert.
Ebenso kann anders als hier bei der Logfileanalyse auf Besonderheiten wie Zugriffe auf nicht vorhandene, nicht öffentlich zugängliche oder weitergeleitete URLs geschaut werden. Selbst mit diesen Einschränkungen kann ein "Bot-Tracking" über das Measurement Protocol viele spannende Fragen beantworten. Unter anderem:
- Welche Bots kommen überhaupt auf meine Site?
- In welcher Tiefe und Frequenz befasst sich der Googlebot (oder ein anderer) mit den Inhalten?
- Wann wurde Seite x zuletzt von Bot y besucht?
- Wie lange brauchen neue Inhalte, bis diese gefunden und besucht wurden?
Tipp: Wer sich mit der Analyse von Logfiles auseinandersetzen möchte, findet in Logalytrix ein geeignetes Werkzeug für einen möglichst einfachen Einstieg.
Warum nur Bot-Tracking?
In der früheren Version dieses Beitrags (noch mit Universal Analytics) gab es zwei Varianten: Eine für alle Besucher und eine nur für Bots. Mit dem GA4 Measurement Protocol hat sich die Situation geändert: Das MP sendet Daten ohne Session-Kontext, wenn es keine echte Session durch reguläres Tagging im Browser gibt. Es gibt keine Möglichkeit, ausschließlichüber das Measurement Protocol eine Quelle oder ein Medium zuzuweisen - diese Zuordnung übernimmt GA4 intern. Für echte Besucher ist das ein erhebliches Manko, weil die serverseitig gesammelten Daten keine sinnvolle Kampagnenzuordnung erhalten. Mehr dazu im Experiment zum Website-Tracking per Measurement Protocol.
Für Bot-Tracking hingegen ist das kein Problem: Bots haben keine Kampagnen. Daher konzentriert sich dieses Update auf das, was das GA4 MP gut kann - Bots tracken und deren Verhalten in einer eigenen Property sichtbar machen.
PHP-Codebeispiel
Der folgende Code zeigt eine Funktion, welcher als Parameter nur der Dokumenttitel übergeben werden muss, der beim Hit verzeichnet werden soll - diese Information hat man i. d. R. spätestens bei der Generierung des Footers einer Seite in einer Variable zur Verfügung. Ist der Titel unbekannt, wird die Funktion zur Not mit einem konstanten Titel versorgt... primär interessiert bei Besuchen von Bots ohnehin eher die URL. Die Funktion beschränkt sich auf Bots und ignoriert alle anderen Besucher.
function track_bot_ga4($title) {
$measurement_id = 'G-XXXXXX';
$api_secret = 'YOUR_API_SECRET';$segments = array(
'googlebot_001' => 'Googlebot::(Googlebot|Mediapartners-Google|AdsBot-Google)',
'bingbot_001' => 'Bingbot::bingbot',
'baidubot_001' => 'Baidu Spider::(Baiduspider|baiduspider)',
'yandexbot_001' => 'YandexBot::YandexBot',
'other_bot' => 'Other::bot|crawl|spider|slurp'
);
$agent = $_SERVER['HTTP_USER_AGENT'] ?? '';
$bot_name = null;
$client_id = null;
foreach ($segments as $cid => $config) {
list($name, $pattern) = explode('::', $config);
if (preg_match('/' . $pattern . '/i', $agent)) {
$bot_name = $name;
$client_id = $cid;
break;
}
}
if (!$bot_name) return; // Kein Bot erkannt
$url = (isset($_SERVER['HTTPS']) ? 'https' : 'http')
. '://' . $_SERVER['HTTP_HOST']
. $_SERVER['REQUEST_URI'];
$payload = json_encode([
'client_id' => $client_id,
'events' => [[
'name' => 'page_view',
'params' => [
'page_location' => $url,
'page_title' => $title,
'engagement_time_msec' => 1,
'bot_name' => $bot_name,
'user_agent_string' => substr($agent, 0, 100)
]
]]
]);
$ch = curl_init(
'https://www.google-analytics.com/mp/collect'
. '?measurement_id=' . $measurement_id
. '&api_secret=' . $api_secret
);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $payload);
curl_setopt($ch, CURLOPT_HTTPHEADER, ['Content-Type: application/json']);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_TIMEOUT_MS, 50);
curl_exec($ch);
curl_close($ch);
}
Was passiert da?
Zunächst benötigt die Funktion zur Konfiguration die Angabe der $measurement_id (die G-XXXXXX-ID der GA4-Property) und eines $api_secret. Das API Secret wird in der GA4-Oberfläche unter Verwaltung > Datenstreams > [Stream auswählen] > Measurement Protocol API Secrets erstellt. Darunter folgt als $segments ein Array von Angaben zu Bots, die zu eigenen Event-Parametern führen sollen. So sind diese später in GA4 Explorations oder BigQuery separat auszuwerten.
Das "Bot-Array"
Im Array ist für jeden Bot ein Key/Value-Paar vorhanden, in dem der Key der client_id eines eindeutigen Nutzers entspricht, so dass jeder Bot als separater Nutzer in Analytics gezählt wird. Der String-Value enthält zuerst den gewünschten "Klarnamen" des Bots, wie er später im Event-Parameter bot_name wieder zu finden sein soll und nach einem "::" als Trenner ein RegEx-Filtermuster, anhand dessen der Bot erkannt wird.
Dabei muss man sich mit Regular Expressions nicht großartig auskennen, denn alle Bots, die als solche erkannt werden wollen, nennen sich "IrgendwasBot" in der einen oder anderen Form, so dass man mit reinen Zeichenketten ohne RegEx-Besonderheiten auskommt. So enthält im Beispiel (außer Google und Baidu) keine der angegebenen Regeln mehr als nur den Namen des Bots aus dem User Agent in Klammern. Im Fall von Baidu gibt es zwei unterschiedliche Schreibweisen, die beide abgedeckt werden sollen. Zur Trennung von optionalen Zeichenketten als Treffer dient in RegEx ein "|". Die "komplexeste" Definition ist der Googlebot in der ersten Zeile mit dem Muster (Googlebot|Mediapartners-Google|AdsBot-Google), der damit alle Varianten abdeckt. In anderen Fällen möchte man ggf. differenzierter segmentieren und erstellt genauere Muster gemäß der Liste der User Agents, die Google verwendet. Wer bestimmte Bots im Sinn hat, aber nicht genau weiß, welche Kennung(en) diese nutzen, kann entweder nach dem Betreiber bzw. Bot inkl. "User Agent" googeln.
Im Fall der Domain, die unten in den Beispielauswertungen genutzt wird, werden z. B. die Besuche des darauf zielenden Monitors UptimeRobot und ein paar SEO-Tools wie Majestic und andere separat getrackt. Jede Domain wird eine eigene sinnvolle Definition benötigen. Um einzusteigen, reicht ein unverändertes Array und es müssen nur eine passende Measurement ID und ein API Secret eingetragen werden, um mit Hilfe des Beispielcodes Daten zu erhalten.
Funktionsweise
Die Funktion durchläuft das Bot-Array und versucht, den User-Agent-String des aktuellen Requests einem bekannten Bot zuzuordnen. Wird kein Bot erkannt, bricht die Funktion sofort ab - es wird kein Hit gesendet. Das spart Zeit und verhindert unnötige Requests an die GA4-API.
Wird ein Bot erkannt, baut die Funktion die aktuelle URL zusammen und erzeugt den JSON-Payload für das GA4 Measurement Protocol. Anders als beim alten UA-Protokoll, das einen simplen GET-Request mit URL-Parametern nutzte, erwartet GA4 einen POST-Request mit einem JSON-Body. Im Payload stecken neben dem Event-Namen page_view die wichtigsten Informationen: URL, Seitentitel und - entscheidend - der bot_name und ein gekürzter user_agent_string als Event-Parameter.
Wichtig: engagement_time_msec
Der Parameter engagement_time_msec mit dem Wert 1 ist kein Versehen: Ohne diesen Wert werden Events vom GA4 Measurement Protocol zwar angenommen, tauchen aber nicht in den Standardberichten auf. Das ist eine der Eigenheiten des GA4 MP, die man kennen muss.
Übertragung per CURL
Ist der Payload zusammengesetzt, wird er mittels CURL als POST-Request an den GA4 Measurement Protocol Endpoint übertragen. Das ist nicht die ideale Lösung, aber es werden zumindest neben dem restlichen Aufwand nicht mehr als 50 Millisekunden investiert, um den Hit abzusetzen. Mit dem Wert für CURLOPT_TIMEOUT_MS kann man je nach Ausstattung des eigenen Servers noch spielen und den Wert so lange reduzieren, bis im Echtzeitbericht der beschickten Property keine Daten mehr ankommen, wenn man parallel in einem zweiten Tab eine Seite auf der eigenen Site neu lädt (via STRG+F5).
Troubleshooting Tipp: Sollte das Ganze nach Implementierung nicht funktionieren, kann das an der eingesetzten PHP-Version liegen. Im Verdachtsfall die Zeile mit CURLOPT_TIMEOUT_MS auskommentieren. Wenn dann Daten ankommen, auf CURLOPT_TIMEOUT umsteigen und als Wert "1" verwenden, denn in diesem Fall reden wir von Sekunden statt Millisekunden. Mehr als eine Sekunde will bestimmt niemand investieren.
Was es zu beachten gibt
Wer die Funktion in ein eigenes System implementieren möchte, sollte auf jeden Fall eine eigene GA4-Property dafür anlegen und gerade bei größeren Sites engmaschig kontrollieren. In vielen Fällen kommen auf diesem Weg schnell sehr viele Daten zusammen, so dass man abwägen muss, welchen Wert man aus den Daten ziehen und wie man sie minimieren oder durch Anpassung des Trackings so organisieren kann, dass sie übersichtlich bleiben.
Das Tracking kostet Zeit. Diese geht direkt in die serverseitige Latenz der Website ein. Wenngleich der Beispielcode den Trackingaufruf bereits "quasiasynchron" absetzt und nicht auf Antwort wartet, sind ausgereiftere Methoden sinnvoll, wenn man damit jenseits von ein paar Tests länger arbeiten will. Es wurde zur Übersichtlichkeit des Beispiels bewusst auf "Overhead" verzichtet. Der Echtbetrieb sollte den Faktor "PageSpeed" aber nicht einfach so ignorieren.
Wer das Tracking z. B. in ein WordPress-Blog einbauen will, muss dazu nur in der footer.php möglichst weit unten einen PHP-Block einfügen oder im letzten Block, in dem i. d. R. wp_footer() aufgerufen wird, die Trackingfunktion anfügen. Measurement ID und API Secret eintragen, ggf. Bot-Array anpassen und unter der Definition der Funktion diese direkt aufrufen:
track_bot_ga4(wp_title('-', false));
Nach dem Hochladen auf den Server sollte der Echtzeitbericht in GA4 direkt Daten anzeigen, wenn der erste Bot vorbeikommt und Spuren hinterlässt. Auf jeden Fall sollte nach der Anpassung des Templates geprüft werden, ob die Site noch funktioniert oder ob Probleme durch die Änderung entstanden sind. Troubleshooting Tipp 2: Kommen keine oder nur verdächtig wenig Daten an, wird das am Einsatz eines der beliebten und sinnvollen Plugins zum Caching in WordPress liegen. Das macht die Site zwar schnell, hilft aber nicht beim serverseitigen Tracking und muss deshalb wohl oder übel ausgeschaltet werden. Zumindest solange, wie man auf diese Weise Daten über Bots sammeln will.
Tipp: Auf "benötigte" Bots beschränken
Wer den Code einsetzt und auf den Kernzweck des Trackings von Bots beschränken will, kann zur schrittweisen Konfiguration und Reduktion der Hits wie folgt vorgehen:
- Die Funktion implementieren und mit den vorkonfigurierten Bots starten
- Den Event-Parameter bot_name für "Other" regelmäßig nach Bots durchsuchen, deren Besuche man separat tracken möchte. Der zusätzlich übergebene user_agent_string hilft bei der Identifikation:
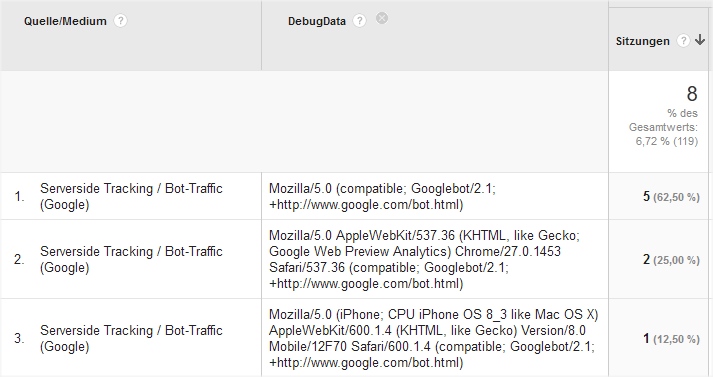
- Für diese Bots eigene Einträge über das Array erzeugen und so "Other" so weit wie möglich minimieren
- Nur tracken, was man tracken muss: Mittelfristig unbekannte oder "irrelevante" Bots aus dem Tracking ausschließen, indem der letzte Eintrag des Segment-Arrays entfernt wird.
Tipp: GA4 Measurement Protocol validieren
Anders als beim alten UA-Protokoll gibt es für das GA4 MP einen eigenen Validierungs-Endpoint. Statt an /mp/collect sendet man den identischen Request an /debug/mp/collect - die Antwort enthält dann eine JSON-Nachricht mit Hinweisen auf eventuelle Fehler im Payload. Das spart viel Debugging-Zeit bei der Ersteinrichtung.
Unterschiede zu UA: Was sich in der Auswertung ändert
Im alten Universal Analytics konnte man Bots über Quelle/Medium separieren, eigene Datenansichten mit Filtern anlegen und so sauber zwischen Bot- und User-Daten trennen. Mit GA4 und dem Measurement Protocol funktioniert das grundlegend anders:
- Kein source/medium über das MP: Das GA4 Measurement Protocol erlaubt keine Zuweisung von Kampagnenparametern. Alle MP-Hits landen als "(direct) / (none)" in der Akquisition.
- Keine Datenansichten: GA4 kennt das Konzept der Datenansichten aus UA nicht. Stattdessen arbeitet man mit einer eigenen Property für Bot-Daten.
- Auswertung über Event-Parameter: Der bot_name wird als Event-Parameter gesendet. In GA4 kann dieser als benutzerdefinierte Dimension registriert und dann in Explorations oder Standardberichten zum Filtern genutzt werden.
- BigQuery als Alternative: Wer die GA4-Property mit BigQuery verknüpft, kann die Bot-Daten dort mit SQL auswerten - flexibler und mächtiger als alles, was die GA4-Oberfläche bietet.
Das Ergebnis in Google Analytics
Implementiert man die Funktion, sammelt selbst eine kleine Website schnell Daten und schon nach einem Tag lohnt sich ein Blick in die Auswertungen. Die folgenden Screenshots stammen aus einer älteren UA-Implementierung des gleichen Konzepts - die Darstellung in GA4 sieht anders aus, aber das Prinzip bleibt identisch: Man sieht, welche Bots kommen, wie oft und welche Seiten sie besuchen.
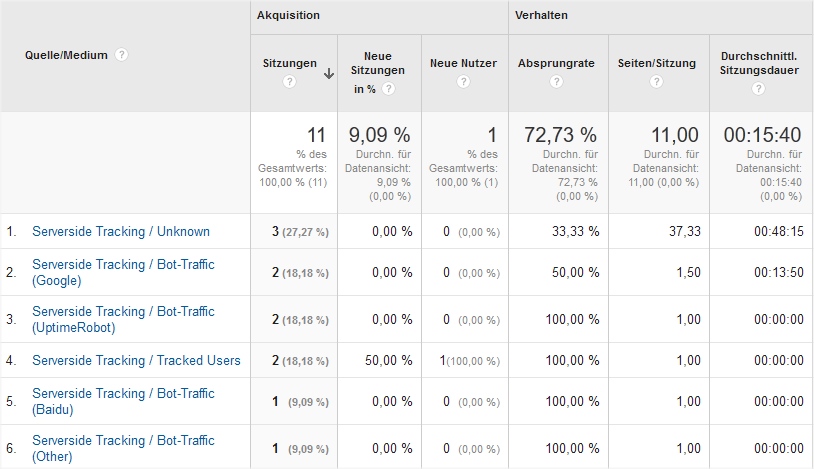
Verteilung nach Bots - in GA4 statt über Quelle/Medium über den Event-Parameter bot_name in einer Exploration auswertbar.
Dashboards und Explorations
Mit diesen Daten lassen sich hilfreiche Explorations in GA4 aufsetzen, die z. B. neben einer Übersicht über alle Bots einen detaillierteren Blick auf Besuche oder Seitenaufrufe des Googlebots bieten.
Googlebot-Besuche auf Seitenebene
Für jeden Bot lässt sich über den Event-Parameter bot_name filtern. Damit lässt sich eine Exploration anfertigen, die exklusiv die Seiten zeigt, die ein bestimmter Bot besucht hat. Ein Klick auf eine Seite und schon ist erkennbar, wann und wie oft diese von Google besucht wurde. Auch die Information, welche Seiten nicht besucht wurden, ist ermittelbar, wenn man die Daten z. B. per BigQuery oder Data API regelmäßig abgreift und mit der eigenen Sitemap abgleicht.
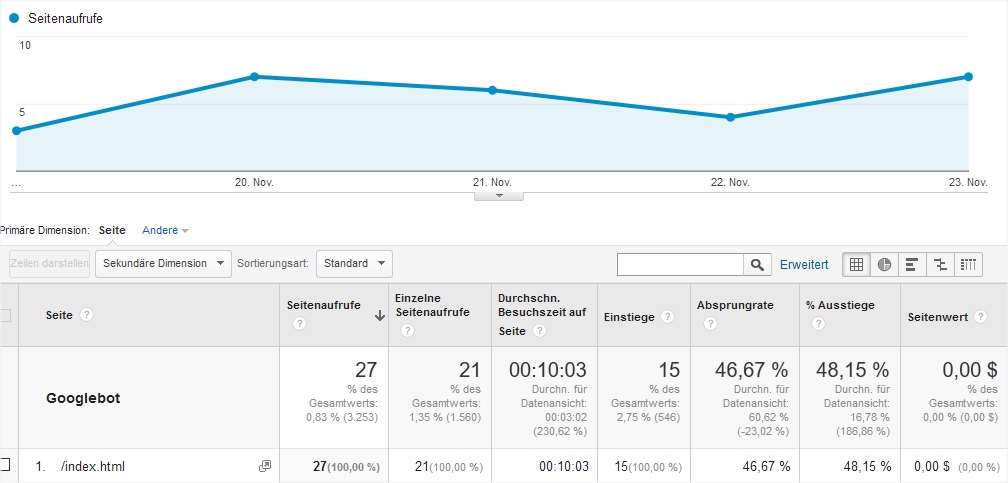
Jede Menge Kennzahlen
Auch wenn nicht alles stets sinnvoll ist - z. B. interessiert die Absprungrate bei Bots wenig -, kann ohne aufwändige Aufbereitung von Logfiledaten direkt in GA4 abgelesen werden, wie oft der Googlebot in einem beliebigen Zeitraum vorbeigekommen ist, wie viele Seiten er sich angesehen hat und wie viel Zeit er "auf der Site" verbracht hat. Nett, oder?
Inspiriert?
Wer sich durch die ganze Artikelserie gekämpft hat, wurde hoffentlich mit einem tieferen Einblick und Verständnis für die zahlreichen Möglichkeiten beglückt, die sich mit dem Measurement Protocol ergeben. Die Grundidee - Bots serverseitig zu tracken und deren Verhalten in Analytics sichtbar zu machen - ist mit GA4 genauso gültig wie zu UA-Zeiten. Die Technik hat sich geändert, das Konzept bleibt zeitlos. Spätestens die Möglichkeit zum Tracking von Bots sollte ausreichen, um eine Implementierung in Betracht zu ziehen - auch parallel zur üblichen Webanalyse und tiefer Tauchgänge in Logfiledaten, die nach wie vor ihren Sinn haben.