Daten anreichern im serverside Google Tag Manager: Firestore und APIs als "Gamechanger"?
Einer der großen Nachteile des serverside Google Tag Manager (ssGTM) im Vergleich zu einer vollwertigen CDP, Lösungen wie Tealium oder einem Tracking-Endpunkt im Eigenbau war bisher die fehlende Möglichkeit der Anreicherung von Daten vor der Weitergabe an Empfänger. Ein wenig Transformation und Zusammenbasteln von im Request vorhandenen Informationen - das wars eigentlich.
Mit dem Update Anfang 2022 sind mit Firestore als Datenbank mit Lese- und Schreibzugriff sowie die Verfügbarkeit von Promises für den Abruf von weiteren Daten über externe APIs alle erforderlichen Mittel hinzugekommen, um diese Lücke zu schließen. Ist das nun gut? Und was genau kann man damit nun anfangen?
Promises? WTF?
Promises dienen in JavaScript dazu, asynchrone Vorgänge wie z. B. den Aufruf einer API in einer Funktion so zu gestalten, dass man im Code auf das Ergebnis "warten" kann. Der Rückgabewert der Funktion besteht also nicht direkt aus dem eigentlichen Ergebnis, sondern nur dem "Versprechen", dieses zu liefern, sobald es zur Verfügung steht.
Das empfangene Ergebnis wird nach Erhalt ausgewertet und fließt in den Rückgabewert der Funktion ein. Der aufrufende Code wartet, bis das Versprechen eingelöst wird (oder die Rückmeldung erfolgt, dass dies nicht funktioniert hat) und verwendet dann das Ergebnis. Das klingt nach einer Kleinigkeit, wenn man bedenkt, dass dies in JavaScript kein neues Konzept ist. Im ssGTM aber war es bisher nicht möglich, Daten aus solchen externen Aufrufen mit unbekannter Laufzeit zu nutzen, um damit Daten am Tracking-Endpunkt anzureichern.
Das ist nun mit dem Update anders und es besteht sowohl die Option, im Code von selbst erstellten Elementen wie einer Variable, einem Tag oder einem Client Promises zu nutzen. Dabei ist man nicht nur auf die typischen vorhandenen APIs für Google Tag Manager Templates angewiesen, die diese Fähigkeit nun besitzen, sondern kann selbst asynchrone Vorgänge einzeln oder in Gruppen anstoßen bzw. hintereinander stapeln und jeweils nach Erhalt der Ergebnisse schlussendlich ein Ergebnis liefern oder die Ausführung des Codes (z. B. im Fall eines Tags) mit einer Erfolgsmeldung abschließen. Hat man dies vorher versucht, ist die Laufzeit des Containers i. d. R. beim Eintreffen von Ergebnissen bereits verstorben und sie liefen ins Leere. Nun ist durch die Implementierung von Promises die ganze Welt der APIs auch für den ssGTM gleichermaßen offen, wie es bei einem Endpunkt in Eigenregie der Fall ist.
Das bedeutet, dass man mit Identifizierungsmerkmalen wie Datenschnittstelle eines CRM, Wetterdaten für den Ort des Browsers, demografische Daten und alles andere abrufen kann, wofür es eine API gibt und was im Kontext des Trackings sinnvoll sein mag. Wollte man so etwas vorher erreichen, waren Umwege über hintereinander geschachtelte Requests und Logik außerhalb des ssGTM erforderlich. Ein Beispiel dazu hat Lukas Oldenburg auf Medium veröffentlicht. Es veranschaulicht gut, wie umständlich man Dinge umsetzen musste, die jetzt komplett direkt im ssGTM erledigt werden können.
Firestore als Datenbank
Passenderweise stimmt die Datenbank, die im obigen Beispiel verwendet wird, mit der überein, die nun im ssGTM als Persistenz erster Wahl verfügbar ist. Firestore ist eine noSQL Datenbank, die mit den Anforderungen auf der gleichen Plattform (GCP) leben und skalieren kann, auf der auch der ssGTM (normalerweise) lebt. Sie bietet neben einfachem (bei Bedarf transaktionalen) Zugriff vor allem eins, was man bei Big Query als einzige Option im ssGTM bisher nicht hatte: blitzschnellen Schreib- und Lesezugriff. Wer Daten in einer Firestore Datenbank ablegen kann, die für die Anreicherung geeignet sind, kann diese direkt und ohne Programmieraufwand mittels einer neuen Variable vom Typ "Firestore Suche" ("Lookup" im Original trifft es besser) auslesen und nutzen.
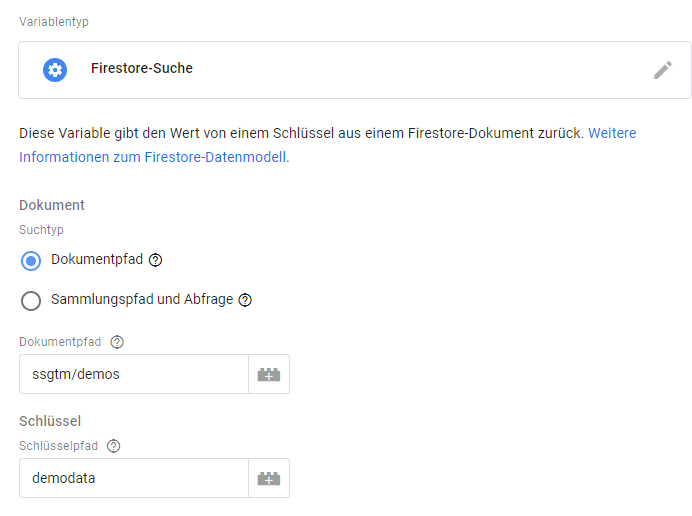
Damit ist das Thema aber freilich nicht durch, denn auch in Templates stehen APIs zum Lesen und Schreiben in Firestore zur Verfügung. Damit kann also z. B. ein "Sitzungscache" gebaut, eine je Client Id gespeicherte Historie von Umsätzen zur schnellen Bestimmung des Kundenwertes, Klassifizierung von Daten, Anreicherung von Produktdimensionen und überhaupt alles umgesetzt werden, was man sich vorher nur in anderen Umgebungen denken konnte. Also auch das, was man nicht bauen sollte wie Hash Tables, die langlebige, unsichtbare und cookielose Speicherung von Werbe-Identifizierungsmerkmalen erlauben und ähnliche Scherze. Eine harmloseres, wenngleich etwas konstruiertes Beispiel zeigt Simo Ahava in seinem Post zu Verfügbarkeit von Firestore. Damit nach aller Begeisterung für die Einsatzmöglichkeiten zur Einschätzung des Potenzials.
Nutzbarkeit und Nutzen
Primär ist der ssGTM ein praktisches Werkzeug, um Kontrolle über das Tracking auf einer Website zu übernehmen. Solange man für seine Anforderungen entweder auf die vorhandenen Elemente zurückgreifen kann oder in der Community Template Gallery eine passende Lösung findet, öffnen die neuen Möglichkeiten also theoretisch den Nutzungshorizont für alle, die jetzt bereits mit dem ssGTM arbeiten oder einen Einsatz planen. Erste Templates sind bereits zu finden und die Landschaft wird laufend vielfältiger. Ist für eine geplante Anbindung wie z. B. der Snapchat Conversion API bereits ein Template vorhanden und wird dort Firestore genutzt, ist eine Einrichtung mit mehr Aufwand verbunden, als nur ein Template zu importieren und ein paar Felder mit Werten zu belegen.
Dafür oder zur Umsetzung eigener Ideen muss - wie beim ssGTM selbst - die Einrichtung einer Firestore Datenbank und Versorgung mit den erforderlichen Daten (wenn Sie z. B. aus anderen Systemen stammen sollen) als Hürde genommen und die DB anschließend in Betrieb gehalten werden. Selbst die Einrichtung kann je nach Rahmenbedingungen durchaus herausfordernd sein und umfasst mehrere Schritte in der Google Cloud Platform und der Konsole von Firebase (kein Schreibfehler; Firestore ist die "Haus und Hof-Datenbank" für Firebase Projekte). "Hürdenfrei" ist das sicher nicht zu nennen.
Individuelle Anforderungen = individuelle Templates
Auf der anderen Seite der Gleichung müssen Tags oder Variablen irgendwo herkommen, welche Promises zum Abruf von Daten über APIs oder aus Firestore nutzen sollen, wenn es um individuelle Anforderungen und Lösungen geht. Die Template APIs öffnen diesen Kosmos zwar, doch es besteht zweifelsfrei eine Hürde, um wirklich Nutzen daraus zu ziehen: diese müssen entwickelt werden. Das passiert zwar in JavaScript, aber die Rahmenbedingungen zur Laufzeit eines ssGTM Containers sind durchaus besonders. Ohne Kenntnisse, wie im ssGTM aus JavaScript Code nutzbare Elemente werden, ist also das reine Wissen über die Sprache selbst nicht ausreichend. Ich habe daher meinem E-Book zur Template-Entwicklung für den ssGTM ziemlich früh ein Update verpasst, in dem die Nutzung von Promises und Firestore mit konkreten Beispielen verdeutlicht wird. Meint: Ohne individuellen Code kann man nur selten das umsetzen, was man im Sinn hat, wenn es um Anreicherung von Daten geht.
Zauberei? Leider meistens eher schwarze Magie...
Außerdem gilt wie immer: Tracking vom Server aus unterliegt den gleichen Regeln, welche im Browser gelten. Verarbeitung und Anreicherung ohne entsprechende Zustimmung darf nicht das Ziel sein, wenn man sich für einen eigenen Tracking-Endpunkt entscheidet. Die o. a. Hash Tables können war nicht nur für fragwürdige Zwecke eingesetzt werden, es ist nur leider allzu oft der Fall. Es ist daher auch in diesem Blogpost nicht zu vermeiden, diesen Aspekt deutlich anzusprechen: Der ssGTM und serverside Tagging im allgemeinen sind nicht dazu gedacht, bestehende Regulierungen zu umgehen. Wenngleich es leicht gemacht wird und kaum nachvollziehbar ist: Es gibt genug Luft für sinnvollen Einsatz, ohne unethisches oder gar rechtsbrüchiges Tracking zu bauen.
Dummerweise verschwimmt diese Grenze genau dort, wo es technisch "zu einfach" ist, Dinge auf der Serverseite zu implementieren, ohne dabei an die Auflösung der Zustimmungslage wirklich zu denken. Das hat gar nicht unbedingt mit den neuen technischen Mitteln zu tun - schon vorher war die Situation stets darauf angewiesen, dass man den Datenstrom wirklich bewusst steuert. Ein Beispiel: Sollte man die Facebook Meta CAPI auch dann mit Daten füttern, wenn keine Zustimmung besteht? Nein, sicher nicht. Wenn nur bei Zustimmung: Mit welchen Daten? Dabei geht es hier gar nicht primär um die strittige IP Adresse, die ohnehin stets mehr oder minder unverzichtbarer Teil des Datenverkehrs mit der CAPI ist. Ob man diese an einen US Dienst wie Meta senden soll oder nicht, muss man ohnehin mit seinem Datenschützer besprechen. Wie sieht es jetzt z. B. mit einer E-Mail-Adresse aus? Unter welchen Bedingungen kann man diese an welchen Dienst weitergeben? "Zustimmung" allein ist dabei nicht zwingend weit genug gedacht. Wenn die Mail-Adresse oder deren Hash (was keinen wirklichen Unterschied ausmacht aus Sicht des Datenschutzes) dann sendet, wenn jemand im Browser auf der Website angemeldet und informiert ist, mag das "okay" sein. Wurde aber die Mailadresse nur bei diesem (oder gar einem früheren) Besuch in einem angefangenen, jedoch nie beendeten Registrierungsprozess angegeben und lebt diese Information nun in einer Firestore Datenbank, aus der man sie jederzeit anhand einer Client Id wieder hervorholen kann, ist das ganz sicher nicht "okay". Diese unangenehmen Feinheiten wollen zumindest bewusst risikobewertet werden, bevor eine Implementierung über das hinausschießt, was man als Unternehmer tragen und verantworten kann.
Bei der Verwendung von APIs zur Anreicherung sieht es ähnlich aus. Den meisten APIs muss man eine Referenz geben, wenn man Daten beziehen will. Das kann ein Ort, eine IP oder ein anderes Datum sein, das auf die eine oder andere Weise für Personen stehen kann. Diese Daten an APIs zu senden, ist je nach Umfang, Anbieter und eingesetzter Infrastruktur evtl. ein Problem für den eigenen Datenschützer im Haus. Diesen sollte man daher konsultieren, bevor man sich an die Implementierung von Anreicherungen jeglicher Art macht.
Brauche ist das? Jetzt?
Vielleicht ist die Antwort schon heute Ja. Bereits "im Kleinen" kann eine Speicherung von Daten zwischen den einzelnen Requests einer Sitzung einen großen Wert haben. Selbst beschränkt auf die akzeptablen "white-hat" Einsatzzwecke steigt der potenzielle Wert eines ssGTM mit den neuen Mitteln zur Datenanreicherung enorm... wenn man bereits entsprechende Anforderungen hat. Betreibt man einen serverseitigen Google Tag Manager primär deshalb, weil dadurch Cookies gehärtet, die Kluft zwischen gegebenem Consent und browserseitigem Trackingschutz geschlossen und die Last der unzähligen Trackingscripts im Browser verringert wird, dann braucht man die neuen Fertigkeiten des ssGTM vielleicht nicht. Noch nicht. Es bleibt trotzdem gut zu wissen, dass die Flexibilität gestiegen ist, denn in der sich ständig ändernden Tracking-Welt weiß man nie, was morgen kommt 😉