Eigene Clients und Tags für den GTM Tag-Server
Der serverseitige Einsatz von Google Tag Manager Containern steckt aktuell noch in den Kinderschuhen und ist (noch) fokussiert auf Google Analytics. Das zudem vorhandene Tag zum HTTP-Aufruf einer beliebigen URL bietet zwar ein kleines Plus an Freiheit, aber außer der Weiterleitung der Parameter oder anderer Merkmale eingehender Requests (damit sind Anfragen an den Server / auf dem Server aufgerufene URLs gemeint) an einen beliebigen Endpunkt ist damit aktuell nicht viel anzufangen.
Die Stärken serverseitigen Taggings sollen sich aber auf ganz andere Weise zeigen. Gemeint sind: Wirkliche Kontrolle über die empfangenen Daten im Sinne der Reduktion, Anreicherung und gezielten Weitergabe. Empfangen und verarbeiten von mehr als nur "Analytics-Hits". Und schlussendlich (und wesentlich) die Verwendung der empfangenen Daten für mehr als nur einen Dienst. Denn nur so können PII-Löcher gestopft, Cross-Site-Tracking verhindert und die Last aus dem Browser genommen werden, weil die Anbindung der Trackingdienste auf den Server verlagert wird.
Damit dieses Potential gehoben werden kann, ist Logik in Form von Code erforderlich. Und dieser steckt in den beiden zentralen Elementen des serverseitigen GTM: Den die Daten empfangenden Clients und den an (Tracking-) Dienste weitergebenden Tags. Dieser Beitrag zeigt dazu im ersten Teil an einem möglichst einfachen Beispiel, wie ein "selbst gebastelter" Tracking-Request in einem eigenen Client angenommen und verarbeitet wird. Danach wird dieser Request an einen eigenen experimentellen "Mini-Trackingdienst" auf dem eigenen Server versendet.
Alternative Videofassung 😉
Wem das hier zu viel Text ist, kann sich mit der inzwischen entstandenen Video-Fassung behelfen. Es gibt zwar eine kleine Panne am Ende (siehe Kommentare bei YouTube), aber das hier beschriebene Prinzip, der Client und eine neue Tag-Vorlage sind auch dort beschrieben.
Kurzgefasst: Das passiert in einem Tag-Server
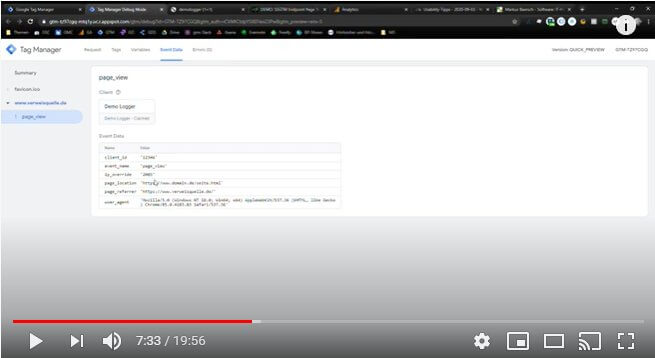
Der Weg der Daten aus dem Browser zum Trackingdienst wird bei Einsatz eines Tag-Servers um eine Zwischenstation erweitert. Dass auf diesem Stopp viele wundervolle Dinge mit den Daten geschehen können, hat der erste Beitrag bereits aufgezeigt. Zuständig dafür sind im Kern das Zusammenspiel von Clients und Tags. Spezialisierte Clients kennen die unterschiedlichen Formate, in denen Daten per Request an den Tag Server gesendet werden und sind in der Lage, diese zu verarbeiten. Dabei können mehrere Clients den gleichen eingehenden Datenstrom auf unterschiedliche Weise verarbeiten und behandeln - je nachdem, was ihre spezielle Aufgabe ist.
"Raus" kommen dabei Daten in einem Format, das von möglichst vielen Tags gelesen werden kann. Deren Aufgabe ist es, die ihnen in einem sehr einfach kontrollierbaren Umfang bereitgestellten Informationen an Trackingdienste, Backendsysteme, Datenbanken oder beliebige andere Empfänger weiterzuleiten, wenn die Informationen für diese Dienste bestimmt und freigegeben sind. Wie auch bei den Clients können mehrere Tags die gleichen Daten zu unterschiedlichen Zwecken nutzen, ohne dass diese auf der Website mehrfach und in unterschiedlichen Formaten gesammelt werden müssen.
Den Anfang bildet immer ein eingehender Datenstrom, der von der Website, einer App oder auch aus anderen Quellen kommen kann. Alles, was wir heute zum Beispiel per Trackingcode in Apps und auf Websites oder direkt per Measurement Protocol an Google Analytics senden, kann durch einen Tag-Server geleitet, von Clients verarbeitet und Tags weitergegeben werden. Websites und Apps werden so von Tracking-Systemen "entkoppelt".
Auch unser Test braucht einen Datenstrom in Form eingehender Requests. Die meisten Beiträge zum serverseitigen Tag Manager Container konzentrieren sich auf mittels analytics.js oder gtag.js Trackingcodes gesammelte Daten. Da wir aber eigene Clients und Tags bauen wollen, nehmen wir auch einen eigenen Datenstrom und nutzen überschaubar komplexe Anfragen, die dazu an den Tag-Server gesendet werden.
Das Request-Format: Der "simple Logger"
Im Beitrag zu serverseitigem Tracking mit Google Analytics wurde bereits ein einfaches, größtenteils auf GET-Parametern basierendes Trackingformat beschrieben, das sich auf Seitenaufrufe und Events beschränkt. Ein entsprechendes Script zum Auslösen des Requests und ein serverseitiger Logger, der diese Anfragen verarbeitet und an Google Analytics weiterleitet, findet sich auf GitHub. Ein ähnliches Format nutzen wir hier stellvertretend für andere (und normalerweise umfangreichere / komplexere) Request-Formate, die prinzipiell auf gleiche Weise (nur mit mehr Aufwand) verarbeitet werden können, wenn ein passender Client vorhanden ist. Wobei die Daten dort eben auch im Header (u. a. Cookies) oder der POST-Nutzlast des Aufrufs stecken können.
Für den Test eigener Clients und Tags in GTM sparen wir uns möglichst viel Komplexität. Zum Füttern des Clients beschränken wir uns auf Aufrufe, die wir direkt im Browser absetzen und ergänzen dazu das o. a. Format um einen Parameter, der uns den fehlenden Referrer aus dem Header ersetzt, in dem im Normalbetrieb die Information über die aufrufende Seite stecken würde.
Reduziert auf Seitenaufrufe
Um einen Seitenaufruf zu vermessen, wird als Minimalanforderung die URL der entsprechenden Seite benötigt. Soll dieser Aufruf einer Sitzung zugeordnet werden können, muss zumindest für die Dauer dieser Sitzung eine gleichbleibende Id her. Und soll auch die Quelle eines Besuchers messbar sein, ist weiterhin der Referrer erforderlich. Wollen wir auch Events vermessen, müssten zudem Parameter für Kategorie, Label etc. des Events her und der Aufruf muss Events und Seitenaufrufe unterscheidbar machen. Da es hier um das Prinzip geht, lassen wir den ganzen Kram also lieber weg und beschränken uns in diesem Beispiel auf Seitenaufrufe.
Dazu werden maximal drei Parameter für URL, ID und Referrer benötigt. Kommt die Id aus einem Cookie, kann diese weggelassen werden. Kann der Referrer des Trackingaufrufs aus dem Request ausgelesen werden, wenn der Aufruf tatsächlich von einer HTML-Seite ausgelöst wird und nicht manuell in die Browser-Adresszeile eingegeben, ist auch dieser nicht erforderlich. Das wollen wir uns aber ersparen und nutzen deshalb für alles (optionale) Parameter. Diese benennen wir url für die Adresse, cid für die Client-/Session-Id und ref für den Referrer.
Ein Trackingaufruf für die URL https://www.domain.de/seite.html, deren Besucher mit der Id 12345 über einen Verweis auf https://www.verweisquelle.de/ auf die Seite gekommen ist, kann also so aussehen, wenn unser Trackingserver - Endpunkt die Adresse https://track.meinedomain.de/pagelogger hat:
https://track.meinedomain.de/pagelogger?url=https://www.domain.de/seite.html&cid=12345&ref=https://www.verweisquelle.de/
Hinweis: Solange wir keine URLs hierüber weitergeben, die selbst wiederum eigene Parameter haben, können wir uns das Codieren der Parameterwerte zu Gunsten der Lesbarkeit sparen. Mit für den problemlosen Transport codierten Parameterwerten würde der obige Aufruf sonst so aussehen:
https://track.meinedomain.de/pagelogger?url=https%3A%2F%2Fwww.domain.de%2Fseite.html&cid=12345&ref=https%3A%2F%2Fwww.verweisquelle.de%2F
Das ist nicht ganz so schön lesbar. Also sparen wir uns lieber im Test URLs, in denen ein "?" oder "&" vorkommt 😉
Requests im Google Tag Manager annehmen: Der Client
Um einen Client in einem serverseitigen Container im GTM zu nutzen, muss eine Vorlage vorhanden sein. Da es für unser selbst erdachtes Format keine Client-Templates gibt, erstellen wir eine neue Vorlage in einem serverseitigen GTM-Container unter "Vorlagen" in der oberen Liste "Client-Vorlagen" mit der "Neu"-Schaltfläche.
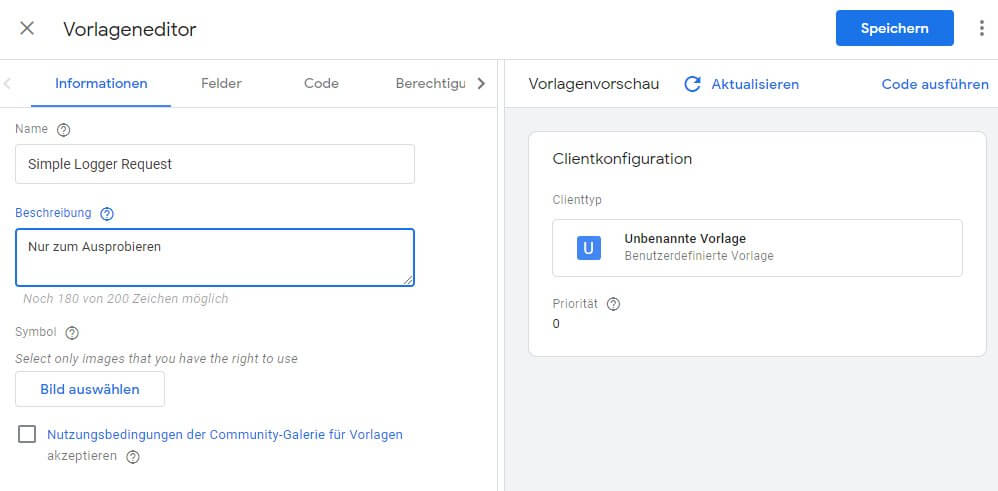
Auf der ersten Seite "Informationen" brauchen wir nur einen eindeutigen Namen. Die Vorschau im rechten Teilfenster übernimmt diese Bezeichnung nach Klick auf "Aktualisieren" und man sieht schon, wie der Client "aussehen" wird, wenn man später verwendet.
Den nächsten Reiter "Felder" können wir beim Client übergehen. Beim Tag werden wir diesen später noch zum Einsatz bringen.
Programmieren in der Sandkiste
Jetzt benötigen wir das Herz des Clients: Den Code. Und damit fängt das Drama an, denn wir werden nicht umhin kommen, das Verhalten des Clients mit JavaScript zu bestimmen. Und als wäre das nicht übel genug, steht leider auch nur ein Bruchteil dessen zur Verfügung, was man in dieser Sprache normalerweise nutzen kann. Der Grund ist, dass wir in einer "Sandbox" arbeiten müssen. Deshalb muss auch jede "weiterführende" Funktion, die wir nutzen wollen, explizit als API importiert werden... und dazu auch zur Verfügung stehen. Das ist nicht mit allen Funktionen so, die man sich wünscht und es ist zudem nicht alles sinnvoll durchführbar, wenn wir in einer Sandkiste auf dem Server sitzen. Eine Übersicht der verfügbaren APIs ist vorhanden, aber damit allein ist der Einstieg eher schwierig.
Hier zunächst der fertige Code mit erklärenden Kommentaren im Bild (ein Link zum Code folgt weiter unten)
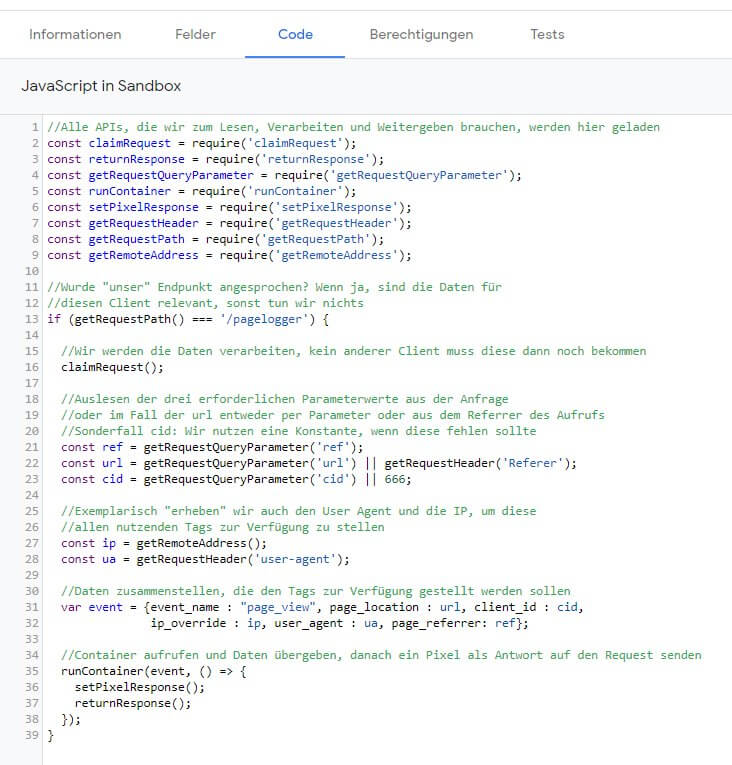
APIs laden
Im oberen Block werden zunächst die APIs geladen, welche im Client benötigt werden. Diese nutzen wir, um die Informationen aus der Anfrage zu lesen, zu verarbeiten und eine Antwort auf die Anfrage zu senden.
Ist die Anfrage für mich?
Den Start des Clients bildet die Abfrage, ob der Client überhaupt für einen Request zuständig sind. Dazu greifen wir auf den "Pfad" des Requests zu, der den Tag Server erreicht hat. Im Prinzip kann auf dem Tag Server jede beliebige URL aufgerufen werden. Alle Anfragen werden vom Tag Server allen Clients "angeboten" (in der Reihenfolge der Priorität) und diese entscheiden selbst, ob sie die Anfrage verarbeiten wollen oder nicht. Das geschieht i. d. R. anhand des "Endpunkts"; in diesem Fall "/pagelogger". Universal Analytics-Hits werden z. B. beim GTM normalerweise an den Endpunkt /collect gesendet. Auch andere Kriterien können entscheidend sein, ob ein Request angenommen wird oder nicht. Wir beschränken uns aber allein auf den Pfad. Wichtig ist zu wissen, dass ein Client auch mehrere Endpunkte bedienen kann - oder anhand anderer Informationen wie z. B. bestimmter GET-Parameter entscheidet, ob er zuständig ist oder nicht. So zeigt Simo Ahava in seinem Video zur Clienterstellung z. B., wie sein Client nicht nur Tracking-Hits verarbeiten kann, sondern auch Anfragen bedient, die zum Laden des analytics.js Trackingscripts im Browser dienen (direkt zu dieser Stelle im Video springen). Wir beschränken uns in diesem Beispiel auf einen einzelnen Endpunkt.
Stimmt der "Einstiegspunkt" eines Requests mit unserem Pfad /pagelogger überein, wird der innerhalb des Blocks befindliche Code ausgeführt; ansonsten bleibt der Client inaktiv.
Verarbeitung durch einen oder mehrere Clients
In der ersten Zeile des Codes wird mit "claimRequest()" bestimmt, dass die Anfrage exklusiv bearbeiten werden soll. Das bedeutet, dass anschließend keine weiteren Clients mehr "gefragt" werden, sondern die Anfrage als verarbeitet gilt. Fehlt diese Zeile, funktioniert der Client ebenso, aber es könnten noch andere Verarbeitungsschritte durch weitere Clients erfolgen. Das klingt wie eine Nebensache, ist es aber nicht. Es sind viele sinnvolle Szenarien denkbar, in denen ein Request von mehr als einem Client verarbeitet und die empfangenen Daten in passendem Umfang oder Formaten den Tags zur Verfügung gestellt werden.
Auslesen der Informationen
Der Request beinhaltet i. d. R. alle drei benötigten Informationen in Form der o. a. Parameter. Diese können via getRequestQueryParameter() ausgelesen werden. Als Ergänzung wird für den Fall, dass keine ID übergeben wird, ein konstanter Wert genutzt... und für "echte" Trackingaufruf, die i. d. R. keine url als Parameter, sondern in Form des Referrers im Header des Aufrufs mitbringen, dieser ebenfalls ausgelesen. Er wird nur verwendet, wenn der url-Parameter fehlt bzw. keinen Wert enthält.
Darunter werden weitere Informationen ausgelesen, die i. d. R. jeder "normale" Aufruf mit sich bringt: IP-Adresse und User Agent. Warum das, wenn man diese Daten gar nicht benötigt? In diesem Fall dient es zur Demonstration, dass ein Client auch Daten bereitstellen kann, die nicht in Form von "sichtbaren" Parametern empfangen wurden. Ob und wie diese in einem oder mehreren Tags verarbeitet werden, ist nicht Sache des Clients. Er hat die Aufgabe, die Informationen aus Requests entgegen zu nehmen, ggf. zu validieren, ergänzen (wie in diesem Beispiel), zu reduzieren oder sonstwie zu verarbeiten. Die Clients stellen diese "fertigen" Daten dann den Tags zur Verfügung. Wie machen die das?
Das Event - die "Datenschicht" zwischen Clients und Tags
Damit die empfangenen Daten an Tags weitergegeben werden können, werden sie in ein bestimmtes Format gebracht. Dieses ist theoretisch vollkommen frei definierbar. Im Sinne einer möglichst hohen Wiederverwendbarkeit ist es aber ratsam, sich an ein Schema zu halten. Die durch unserem Client bereit gestellten wenigen Daten bilden einem Ausschnitt dessen, was aus einem Google Analytics Hit gemacht wird, wenn dieser von einem vorgefertigten Client im serverseitigen GTM angenommen wird.
Dabei wird z. B. die URL unter dem Schlüssel "page_location" weitergegeben. Das muss freilich nicht so sein und der Client funktioniert auch dann, wenn wir den Schlüssel "url", "seite", "R2D2" oder "Klaus" benennen. Solange empfangene Tags wissen, was wo zu finden ist, ist das unproblematisch. Warum wir "page_location" verwendet haben, wird sich später bei der Nutzung durch Tags noch erweisen. Einzig der Schlüssel "event_name" ist nicht ganz wahlfrei, wenn man die im GTM vorgesehenen Prozesse beibehalten will. Da wir einen Seitenaufruf vermessen, verwenden wir den Wert "page_view", wie ihn das Event Model vorsieht. Der Vorteil ist, dass es - wenn sich alle Clients daran orientieren - egal sein kann, woher Daten stammen und wie sie empfangen wurden. Solange für ein Tag, das diese zu verarbeiten wünscht, alle erforderlichen Angaben vorhanden und dank der bekannten Struktur auch auffindbar sind. Deshalb halten wir uns mit unserem Client auch daran.
Weitergabe an Tags und Senden einer Antwort
Wenn alle Daten zusammengestellt wird, werden sie mittels der Variable event am Ende des Codes zur Verarbeitung durch die Tags weitergereicht, indem der Container mit den Daten "gestartet" wird. Anders als bei Google Analytics, wo Requests auch im Batch Betrieb gesendet mehrere Hits enthalten könnten, müssen wir diesen Vorgang nur einmal starten, denn wir haben stets nur ein Event. Bleibt nur noch, eine passende Antwort zu senden. Diese besteht bei unserem Client - wie bei vielen anderen Tracking Endpunkten - aus ein 1x1 Pixel. Damit wir das nicht selbst bauen müssen, wird wieder auf eine API zurückgegriffen.
Damit ist alles fertig und der Client könnte seine Arbeit aufnehmen. Spätestens jetzt ist ein guter Zeitpunkt zum Speichern 😉 Vor dem Einsatz müssen noch die Berechtigungen definiert werden. Ja richtig: Den Reiter "Tests" sparen wir aus. Aber schon jetzt wird ohne Definition der Berechtigungen ein Test ohne Request-Daten via "Code ausführen" in der Vorschau fehlschlagen, weil uns zum Lesen des Anfrage-Pfads die Rechte fehlen.
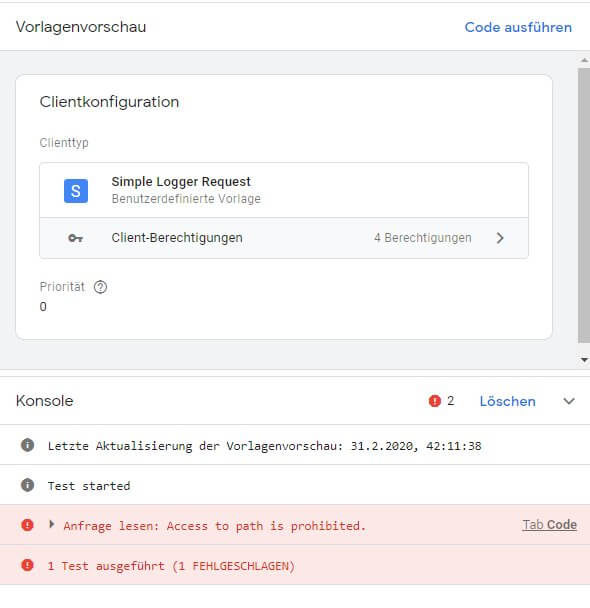
Berechtigungen: Was darf ein Client dürfen?
Auf dem Reiter "Berechtigungen" können für verschiedene Bereiche, die danach variieren, welche APIs man benutzt, Rechte des Clients definiert bzw. "angefordert" werden. Wollen wir den Anfragepfad lesen, um zu bestimmen, ob wir für den Request zuständig sind (siehe oben), muss Zugriff auf den Pfad der Anfrage bestehen. Ebenso auf Parameter, Header (wir lesen IP, ggf. Referrer und User Agent aus) und so weiter. Dabei kann man den Zugriff entweder "global" oder sehr granular definieren. So ist es auch möglich, einem Client nur das Lesen bestimmter Parameter, Cookies, Header etc. zu erlauben.
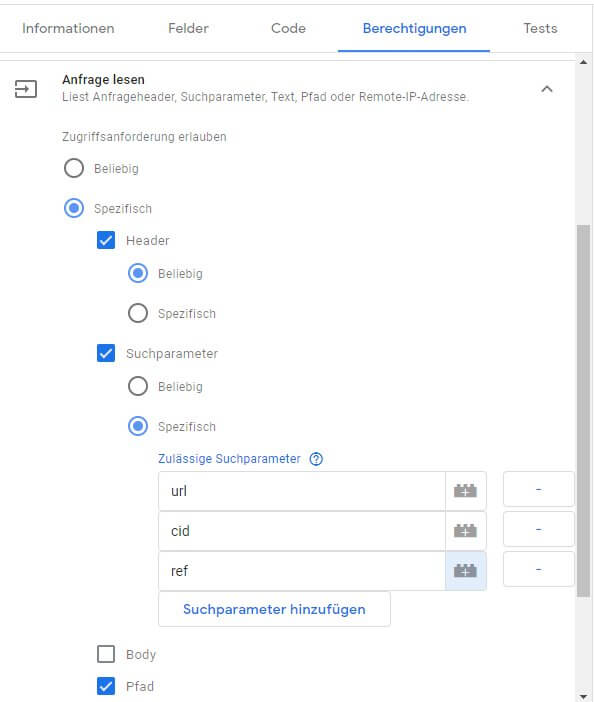
Es ist eine gute Idee, den Zugriff bei der Erstellung eines Templates - wenn möglich - auf das zu beschränken, was erforderlich ist. Dieses Konzept ist schon von den Templates für normale clientseitige GTM Container bekannt, erprobt und sinnvoll. Wer faul ist, gibt unserem Testclient Zugriff auf alle Felder und Bereiche der Anfrage und Antwort. Zudem müssen wir eine Antwort zurücksenden und Container ausführen.
Warum sind die letzten beiden Dinge nicht Standard? Erstens ist es nicht erforderlich, eine Antwort zu senden. Eher selten ist ein eingehender Request auf eine Antwort angewiesen. Stichwort: "Fire And Forget". Auch die Weitergabe an den Container ist nicht unbedingt erforderlich. Theoretisch kann die Verarbeitung und z. B. Weiterleitung an einen anderen Endpunkt schon im Client passieren. Schritte wie z. B. das "Härten" eines Cookies, wie ebenso von Simo gezeigt, sind durchaus Aufgabe des Clients. Weitere denkbare Szenarien sind "Cleanup-Clients", die auf einem Endpunkt sitzen, die Daten säubern und dann an einen weiteren Endpunkt auf dem gleichen oder einem anderen Server weitergeben, ohne dass überhaupt Tags im Spiel sein müssen.
Sind alle Rechte definiert, sollte "Code ausführen" keine Fehler mehr ausgeben. Das ist kein Garant, dass der Code nach dem Vergleich des Pfades mit dem Wunschendpunkt auch funktioniert... aber das prüfen wir stattdessen in der GTM Vorschau, mit einem echten Client und echten Requests. Daher kann der Vorlagen-Editor nach einem finalen Klick auf "Speichern" verlassen werden.
Das neue Client Template im Einsatz
Ist die Vorlage fertig, kann sie unter "Clients" über "Neu" verwendet werden, um einen Client anzulegen. Nach Auswahl des Typs bleibt außer dem Speichern nichts zu tun. Die Priorität ist egal, weil es nur einen Client geben wird, der sich um unseren selbst erdachten Endpunkt kümmert und weitere Felder haben wir nicht definiert.
Klickt man oben rechts im GTM auf "in Vorschau ansehen", wird die Vorschauansicht des Containers bzw. des Tag Servers in einem neuen Tab geladen. Diese wird über die Domain des Tag Servers bereitgestellt. Das ist je nach Setup die DNS-weitergeleitete eigene Domain oder eine Subdomain wie gtm-abcde12-xxx.uc.r.appspot.com. Genau an diese Domain senden wir in einem weiteren Tab (gleicher Browser, sonst sieht man nichts) unsere Test-Anfragen an den von uns bestimmten Endpunkt. Noch passiert dabei nichts mit den Daten, aber eine Funktionskontrolle ist auch so möglich. Starten wir dazu mit dem Beispiel aus dem Abschnitt weiter oben; diesmal mit unserem Tag-Server als Empfänger:
https://gtm-abcde12-xxx.uc.r.appspot.com/pagelogger?url=https://www.domain.de/seite.html&cid=12345&ref=https://www.verweisquelle.de/
Hat alles geklappt, wird ein Pixel von unserem Client zurückgeliefert und im Titel des Reiters steht "pagelogger (1x1)".
Nach einem Wechsel auf die GTM-Vorschau hat sich in der Summary etwas getan, denn der Browser hat versucht, das Favicon abzurufen. Weil Browser das eben so machen. Um diesen Request hat sich niemand gekümmert und so ist dieser Request aus Sicht der Clients unbeantwortet geblieben. weiterhin sieht man einen Aufruf, der entweder nach dem Request oder ggf. einem Parameterwert benannt ist (das wird sich sicher noch ändern, wir sind in einer Beta). Das ist unser gerade manuell abgesetzter Tracking-Request.
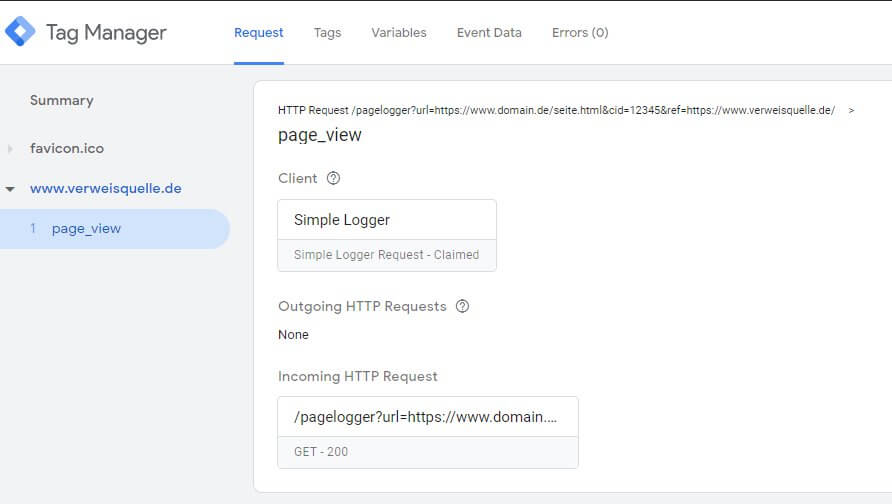
Die Ansicht "Request" zeigt die Anfrage inkl. aller Parameter. Auch sieht man dort unseren Client, welcher den Request verarbeitet hat. Darunter - mangels eines Tags - finden sich keine ausgehenden HTTP-Requests.
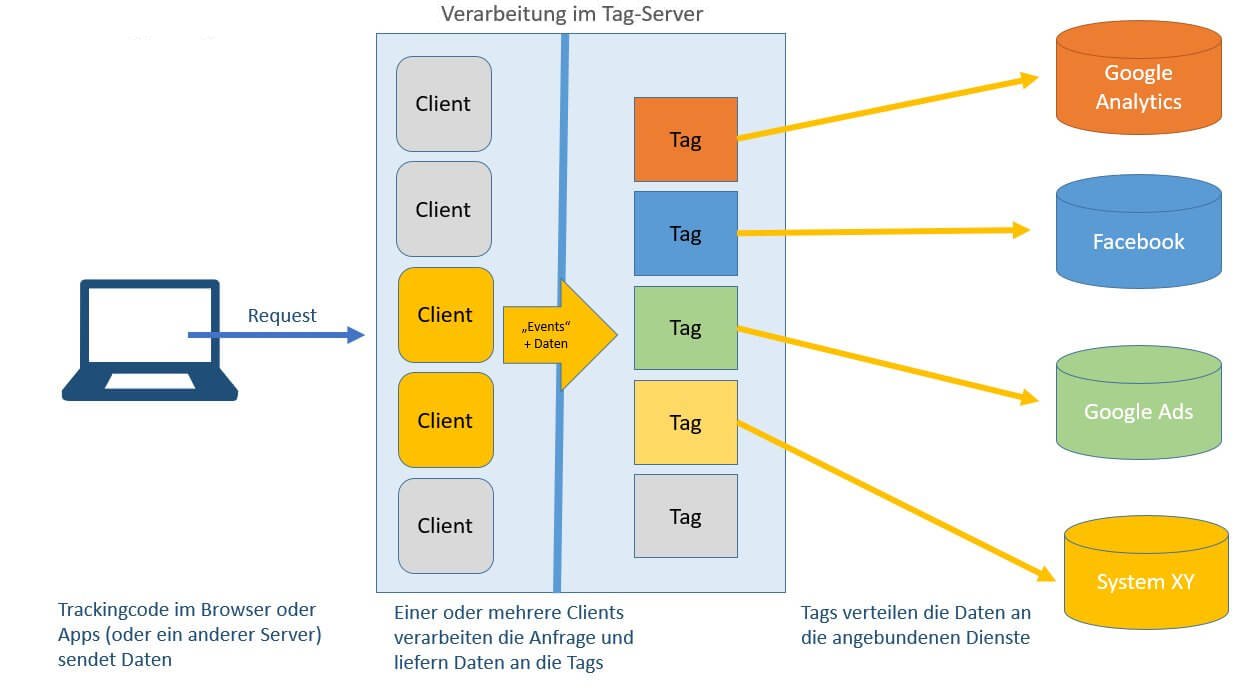
Dafür steht in der Summary unter dem Request als Zeichen der erfolgen Verarbeitung das Event, welches durch den Client ausgelöst wurde. Zur Erinnerung: Hier könnten auch weitere Events stehen, die von anderen Clients stammen, welche den Request ebenfalls verarbeitet haben. Oder mehrere Events aus einem Client, der mehrere (per POST) empfangene Hits im Batch verarbeitet hat. In unserem Fall ist nur das Event "page_view" zu sehen. Markiert man es, kann auf der Seite "Event Data" kontrolliert werden, was unser Client aus der Anfrage gemacht hat:
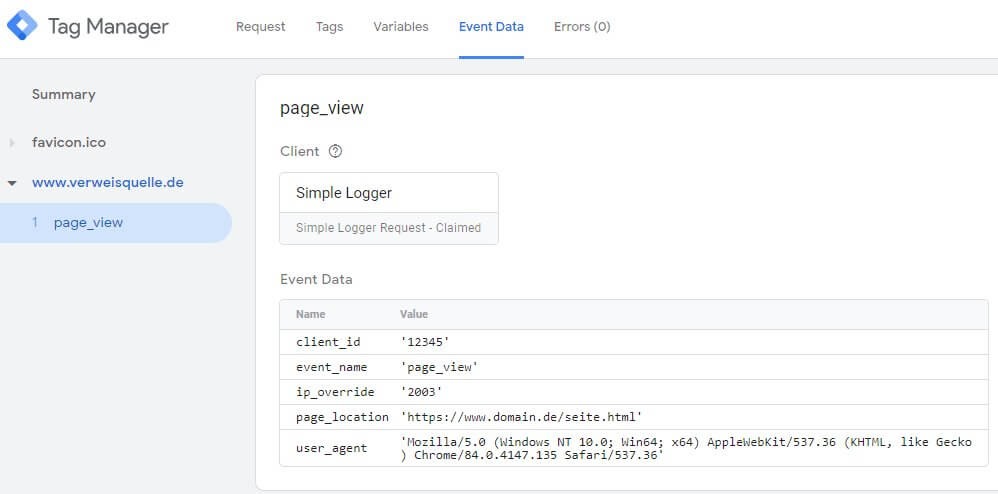
Wie zu erwarten war, sind die Eingangsparameter aus dem Request in den dafür vom Client vorgesehenen Feldern gelandet. Auch die (gekürzte) IP und der User Agent sind zu sehen. Damit ist der Client fertig und einsatzbereit, empfangene Daten an Tags weiterzugeben.
Daten nutzen: Tracking-Aufrufe an Google Analytics senden
Nach der ganzen Arbeit jetzt erst einen Client basteln, damit man endlich etwas jenseits der Vorschau sehen kann? OK, das ist vermutlich wirklich zu viel verlangt. Zum Glück haben wir uns an das Event Model von Analytics gehalten. Daher sollten sich diese (wenigen) Daten auch an Analytics senden lassen.
Um diese These zu erproben, sollte eine neue Universal Analytics Property angelegt werden, um keine Echtdaten mit unseren Tests zu verschmutzen. Diese kann vorbereitend in der Echtzeit-Ansicht geöffnet werden, nachdem aus den Einstellungen die Property-Id (UA-xxxxxxx-y) kopiert wurde. Danach legen wir ein neues Universal Analytics Tag an. In den Optionen wird das Überschreiben von Einstellungen aktiviert, um die Property-Id im Tag einzutragen. Zur Erinnerung: Unser Client bekommt keine Tracking-Id als Parameter mitgeteilt und liefert auch keine mit den Daten an die Tags aus. Daher muss die Zielproperty der Trackingaufrufe für Analytics vom Tag ergänzt werden.
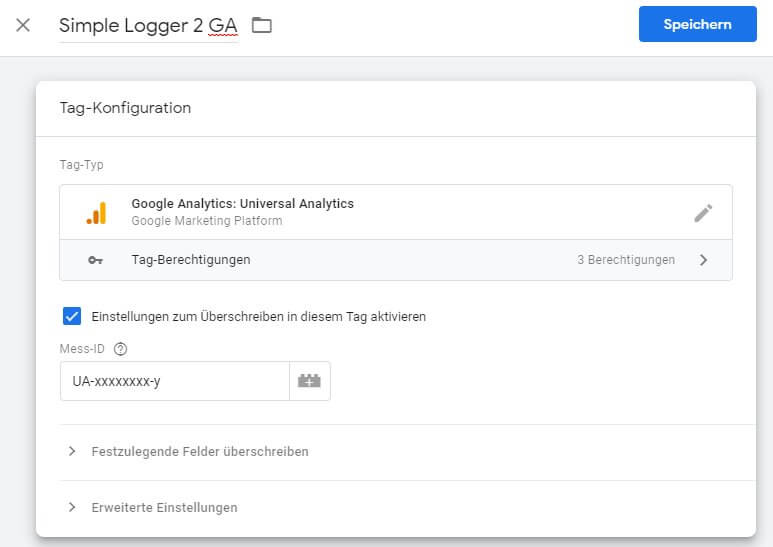
Damit das Tag weiß, wann es etwas zu tun hat, wird ein passender Trigger erstellt. Dieser feuert nur, wenn Daten von unserem neuen Client empfangen werden. Dazu dient die Bedingung, welche den Client Namen auswertet und nur Ereignisse bedient, die von unserem "Simple Logger" stammen. Wenn der Name des Clients aus dem Beispiel oben nicht übernommen wurde, diesen hier entsprechend anpassen.
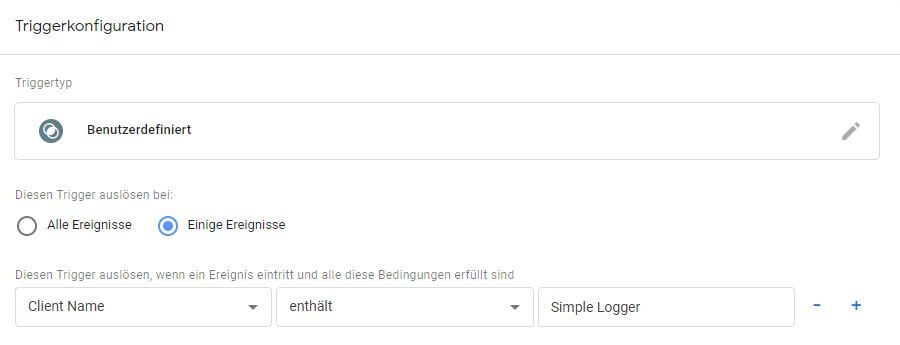
Ist der Trigger zugeordnet und das Tag gespeichert, kann über "in Vorschau ansehen" die Vorschau neu geladen werden. Alte Requests aus dem vorherigen Test sind verschunden. Also setzen wir neue ab, indem wir den Beispielaufruf von oben wiederholen. Dazu den Reiter mit dem Trackingpixel unter der vorherigen URL neu laden.
https://gtm-abcde12-xxx.uc.r.appspot.com/pagelogger?url=https://www.domain.de/seite.html&cid=12345&ref=https://www.verweisquelle.de/
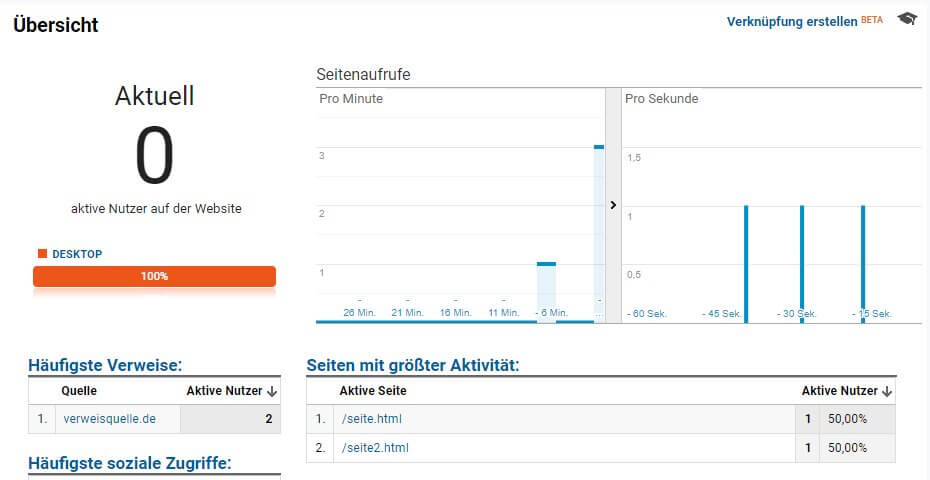
Ein Wechsel in die Echtzeitdaten von Analytics sollte diesen Aufruf schon zeigen. Um einen Besucher zu simulieren, kann danach ein weiterer Request an den Tag Server gesendet werden, bei dem z. B. die URL der Seite geändert und der Referrer entfernt werden.
https://gtm-abcde12-xxx.uc.r.appspot.com/pagelogger?url=https://www.domain.de/seite2.html&cid=12345
So wird in Analytics keine weitere Sitzung eröffnet. Wenn man beide Hits nochmal mit einer beliebigen anderen cid wiederholt, zeigen sich zwei Besucher in der Echtzeit, die über verweisquelle.de auf die "Website" gekommen sind.
So what?
Damit haben wir aus einem selbst definierten Trackingformat mit recht wenigen Daten (auf IP und User Agent hätten wir in diesem Test ebenfalls verzichten können) per Client ein Event ausgelöst, welches auch von einem Universal Analytics Tag verarbeitet werden kann. Das ist nicht mehr oder weniger, als auch mit wenigen Zeilen PHP des Beispiel-Loggers erreicht werden kann. Ohne den ganzen GTM Server-Schnickschnack.
Das liegt aber nur daran, dass wir wenige Daten auf einfachem Weg empfangen und damit außer dem "Übersetzen" in das Event Model nicht viel angefangen haben. Hier kann man sich also beliebig viel Komplexität der Datenanpassung dazu denken... oder die angesprochenen Beispiele wie Härtung von Cookies, Entfernen von sensiblen Informationen oder gezieltes Entfernen von Daten aus dem Event Model, bevor die Daten an Tags geliefert werden.
Eine Tag - Vorlage für den "eigenen Trackingdienst"
Um den in der Einleitung angesprochenen Vorteil der Mehrfachnutzung anzugehen, brauchen wir mehr als "nur" Tags für Google Analytics. Obschon wir das Ziel auch mit dem im GTM verfügbaren HTTP-Tag erreichen können, soll ein wenig mehr über die interne Arbeitsweise von Tags gezeigt werden. Dazu folgt die Entwicklung eines eigenen Tags. Die gute Nachricht: die meisten Konzepte sind bereits aus der Clienterstellung bekannt... und da das geplante Tag nicht viel können muss, kommen wir auch mit deutlich weniger Code aus.
Wie zuvor wird eine eigene Vorlage erstellt. Dazu unter "Vorlagen" im Bereich "Tag-Vorlagen" mit "Neu" ein neues Template erzeugen. Als Bezeichnung bietet sich "Simple Logger Tag" an; mehr braucht die erste Seite nicht. Bevor es an den Code geht, wird im Gegensatz zum Client mindestens ein Feld benötigt, in dem der Benutzer der Vorlage die URL des eigenen Trackingdienstes eintragen kann. Dazu wird unter "Felder" ein neues Textfeld angelegt und "endpointUrl" genannt. Der Anzeigename kann direkt definiert werden; über die Einstellungen sind weitere Attribute eines Felds einblendbar. Dort die "Validierungsregeln" aktivieren und als Regel hinzufügen, dass das Feld nicht leer sein darf (irgendwohin wollen wir die Daten schließlich senden). Denkbar wären weitere Validierungen, die z. B. über Reguläre Ausdrücke sicherstellen, dass eine gültige URL eingegeben wurde. Was wir uns jetzt aber sparen. Das Ergebnis sollte in etwa so aussehen:
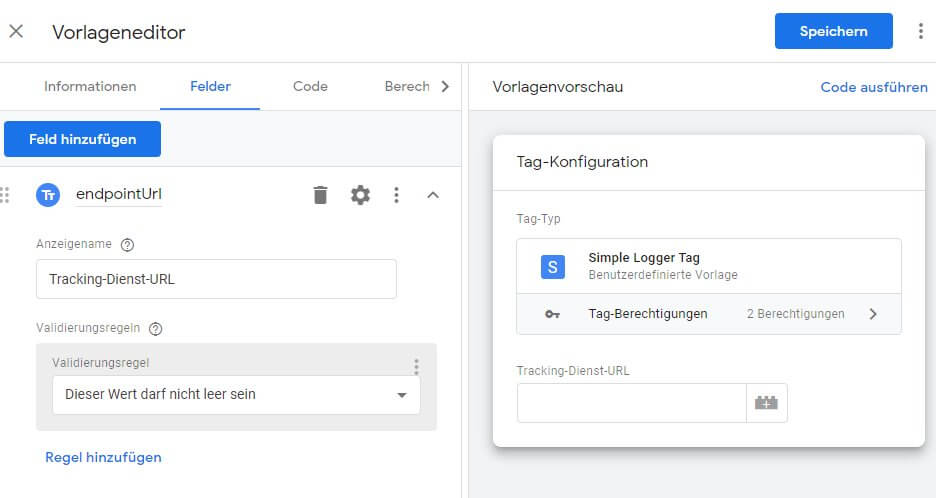
Weitere Felder benötigt unser Tag nicht. Vor den Berechtigungen, die vom Code abhängig sind, erstellen wir den überschaubaren Tag Code.
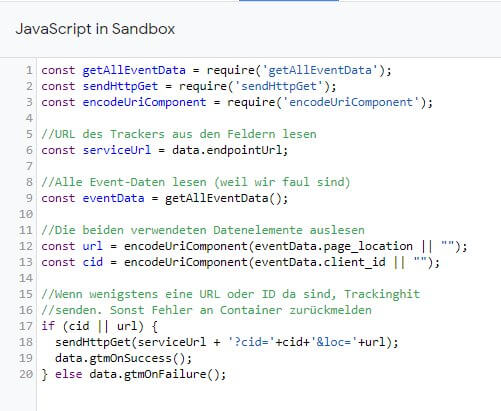
Kurze Erklärung Wie im Client werden zunächst die benötigten APIs geladen. Danach liest das Tag die URL aus den Einstellungen aus, die im Objekt data in allen Tags bereitstehen und extrahiert die Daten aus dem empfangenen Event. Das geht gezielter und man kann den Zugriff des Tags auf bestimmte Schlüssel des Event Models beschränken. Für das Verständnis des Grundprinzips reicht es zu wissen, dass man Tags ebenso wie Clients sehr gezielt Rechte einräumen und diese auch auf bestimmte Elemente einschränken kann... und sollte, wenn es um mehr als eine Spielwiese geht!
Reduzierte Lieferung von Daten an den Tracker
Aus den empfangenen Daten werden Parameter für die Übergabe an den Trackingdienst zusammengestellt und die URL mit diesen (codierten) Parametern aufgerufen. Mehr passiert in unserem Tag nicht. Warum also die Mühe? Weil man sehen kann, wie die Daten, die unser Client zur Verfügung gestellt hat, in ausgewähltem Umfang an Tracker gesendet werden können. Nur das, was der Tracker zur Verarbeitung benötigt. Das sind nur die URL und eine ID. Kein Referrer, kein User Agent, keine IP des Besuchers o. Ä. Da Hits aus Sicht eines Trackingdienstes nicht aus einem Browser, sondern vom Tag Server kommen, bleiben solche Informationen unbekannt. Der Tracker "sieht" nur die IP des Servers; eine Auswertung eines User Agents zur Bestimmung von Browser, Betriebssystem etc. ist nicht mehr möglich. Natürlich: Mit dem Rest kann man auf Empfängerseite nicht mehr viel anfangen. Aber das war ja der Zweck der ganzen Übung 😉
Unter den Berechtigungen muss der Tag Vorlage noch das Lesen der Ereignisdaten (in unserem Fall alle) und das Senden einer HTTP Anfrage erlaubt werden (an beliebige URLs, denn diese wird per Feld frei definiert). Abschließend wird die Vorlage gespeichert, der Editor verlassen und wie zuvor für Google Analytics ein neues Tag erzeugt.
Unter Verwendung des gerade erstellten Templates wird dieses angelegt, eine beliebige (oder reale) URL eines Tracking-Endpunkts eingetragen und der bereits für das Universal Analytics Tag angelegte Trigger verwendet.
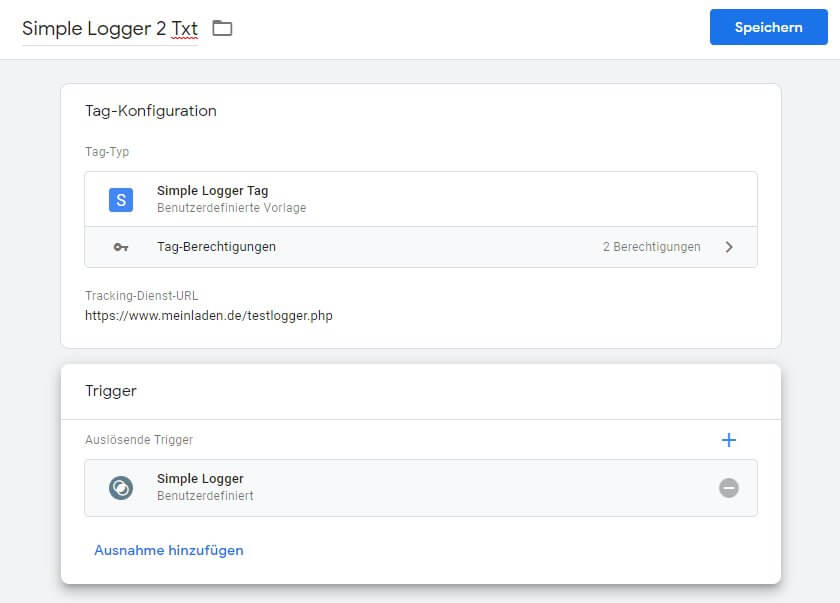
Nach dem Speichern und Aktualisieren der GTM-Vorschau kann einer der vorher schon erprobten Tracking-Hits per separaten Tab erneut an den Tag Server gesendet werden. Beim "page_view"-Event sieht man dann, dass neben dem Universal Analytics Tag auch das neue Tag gefeuert hat.
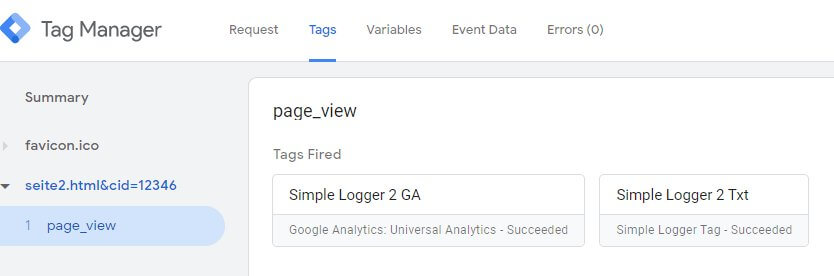
Auf dem Reiter "Request" sind neben einer eingehenden Anfrage die zwei ausgehenden Requests zu sehen - einer an Universal Analytics, der andere an den selbst definierten Endpunkt. Nach Klick auf den Request sieht man die selbst definierte URL und die übergebenen (und codierten) Werte der Parameter. Sonst passiert nichts, denn es wurden keine speziellen Header gesendet, kein Cookie zurückgeliefert oder andere Daten ausgetauscht.
Der eigene Endpunkt
Am anderen Ende des Requests steht theoretisch eine Datei "testlogger.php" auf dem eigenen Server - wie im Tag definiert. Wer wirklich den ganzen Weg der Daten von der Anfrage an den Tag Server bis in ein Zielsystem sehen will, kann dazu einen solchen Endpunkt auf der eigenen (Test-) Domain schaffen. Entweder über die beispielhafte logger.php... oder mit ein paar Zeilen Code, welche die Parameter auffangen und daraus eine Zeile in einer Textdatei auf dem Server machen (im Beispielcode enthalten; siehe Link unten).
Das Text-Log kann nach ein paar Testaufrufen heruntergeladen werden. Es zeigt die generierten Aufrufe nebst einem Zeitstempel. Was freilich nur exemplarisch für eine Ernst zu nehmende Verarbeitung steht - genau so gut kann am Endpunkt eine Weiterleitung an interne Systeme oder eine Speicherung in einer Rohdatenbank erfolgen, um daraus jenseits von externen Analysesystemen Auswertungen anzufertigen. Das allerdings vermutlich auf Basis von mehr als nur einem Zeitstempel, einer URL und einer ID. Schon ergänzt durch den Referrer kann man damit schon eine Menge anfangen, wie das Beispiel der an Analytics übergebenen Daten aus unserem simplen Client zeigt.
Bitte nicht vergessen: Den Testlogger wieder vom Server löschen und im GTM-Container aufräumen, wenn es kein Test-Container war und daher eine versehentliche Veröffentlichung der gerade erstellen Clients und Tags denkbar ist.
Bock bekommen?
Wer Lust auf mehr bekommen hat oder das Beispiel selbst nachvollziehen möchte, findet den Code der Vorlagen und des "Minimal-Loggers" in PHP hier auf GitHub. Damit sind nur bedingt reale Tracking-Anforderungen abzudecken. Es ist aber bereits eine ganze Menge an sinnvollen Templates für verschiedene eingehende und ausgehende Datenströme jenseits von Analytics Hits in der Template Gallery zu finden. Damit hat und wird das Einsatzspektrum der serverseitigen Container für GTM spannende neue Facetten erhalten. Wer hier Ideen und den Willen zur Umsetzung hat: Ich habe ein E-Book mit allem gefüllt, was man für die Erstellung eigener Vorlagen für den serverseitigen Tag Manager braucht.
WDarum das Ganze
Dieses Beispiel dient primär zur Verdeutlichung der Zusammenarbeit zwischen Clients und Tags im serverseitigen Tag Manager Container. Zwischen den Zeilen haben sich dabei - hoffentlich - bereits einige der Vorteile gezeigt. Vor allem in Hinblick auf die heute noch auf vielen Websites im Browser aktiven Trackingscripts, welche eigentlich alle das Gleiche tun, zeigt sich die Stärke serverseitiger Verarbeitung. Ein Seitenaufruf oder eine Transaktion, die Ablage eines Produkt im Warenkorb oder Betrachten von Detailseiten sind Informationen, die neben der Webanalyse oft an zahlreiche Plattformen gesendet werden. Aus dem Browser. Reduziert man dies auf einen "Datenstrom" zwischen Browser und Tag-Server, kann er kontrolliert Informationen je nach Zustimmungsumfang an andere Systeme verteilen. Dabei tritt das im Browser eingesetzte System zur Datensammlung in den Hintergrund. Ob diese Aufgabe das Script von Google Analytics, Matomo oder etwas ganz anderes versieht, ist zweitrangig. Weiterverarbeitung und Verteilung der Daten sind der weitaus wichtigere Teil der Informationskette. Und genau da setzen Tag-Server an.
Das ist / war natürlich auch ohne die neuen Container im Google Tag Manager umsetzbar. Mit anderen Systemen oder eigenen Anbindungen. Trotzdem senkt eine weit verbreitete Plattform wie GTM die Hürden gerade für kleinere Unternehmen, denn sie ermöglicht - spätestens seit Ablauf der Beta-Phase des GTM Tag-Servers - einen Einstieg ohne große Kosten oder Ressourcen. Die Komplexität der Anbindung von Conversion APIs bei Google, Bing, Facebook & Co., Tracking von Werbenetzwerken etc. wird auf die Verfügbarkeit entsprechender Tags und Clients reduziert. Zumindest wenn der eingehende Datenstrom alle entsprechenden Informationen inkl. der Angaben zum Umfang der Nutzbarkeit (Stichwort "Consent") sowie die erforderlichen Ids der anzubindenden Systeme enthält - auch ggf. in Form von Cookies. Wobei im Echtbetrieb freilich durchaus Kosten zu berücksichtigen sind.
Das alles in Eigenregie zu etablieren und durch die verschiedenen Versionen der APIs funktional zu halten, war für viele Unternehmen bisher keine realistische Option. Die mögliche Orchestrierung der Daten durch ein wachsendes Angebot an Clients und Tags für den GTM kann daran durchaus etwas ändern. Nicht falsch verstehen: Der Betrieb eines serverside Tag Managers kann je nach Traffic, der darüber vermessen werden soll, durchaus mehrere Hundert Euro im Monat erfordern. Die Flexibilität und erhöhte Datenqualität und -quantität kann diese Kosten schnell rechtfertigen.
Sind die APIs in der Lage, benötigte Cookies zum Browser zurückzuliefern, wenn dies erforderlich und vom Besucher akzeptiert wird, werden alle heutigen typischen Trackingszenarien abbildbar. Die derzeit erforderlichen zahlreichen Scripts und direkte Kommunikation zwischen Browser und Trackingsystem werden minimiert oder ganz unterbunden. Die positiven Folgen können nicht nur in besseren und zuverlässigeren Daten angebundenen Systemen bestehen, sondern entlasten auch den Browser, minimieren Risiken und setzen möglichst früh an, wenn es um Dinge wie Datenqualität geht.
Wer hat schon einmal in Google Analytics Berichte zu Seiten gesehen, in denen unsinnige Pfadangaben oder komplette URLs inkl. https:// und allem Schnickschnack aufgetaucht sind? Ich schon... einige! Das kann der schlaue und darauf spezialisierte Client im Tag-Server locker reparieren. Ebenso wie viele "Standardfilter" zu ersetzen, die heute noch "schnell vor die Datenansicht geklemmt werden", damit keine Fehler in Reports gelangen. Datensammlung per Trackingcode ist nicht perfekt. War sie nie und wird sie auch nicht werden. Dieser Beitrag hat aber hoffentlich demonstrieren können, wie serverseitige Tag Manager Container dabei helfen, zuverlässigere und effizientere Trackingsysteme aufzubauen. Spätestens wenn es um mehr als "nur" Webanalyse geht. Freuen wir uns darauf, bald viele neue Clients und Tags aus der Community und von Tracking-Anbietern auch serverseitig nutzen zu können. Wer bis hier dran geblieben ist, weiß auf welche Weise die Kernelemente im serverseitigen GTM funktionieren und welche Möglichkeiten sich damit bieten.