Auswirkungen von Javascript-Crawlern mit Rendering auf Google Analytics
Hinweis: Dieser Beitrag entstand im April 2018 und dokumentiert eine Testreihe gegen Universal Analytics Properties. Seit Juli 2023 ist UA abgeschaltet, die gezeigten Datenansichten, Filter und Screenshots gibt es in dieser Form nicht mehr. Die Kern-Erkenntnisse - dass einige Crawler aktiv Tracking-Scripts blocken und andere nicht, und dass Filter nur gegen eigene Testcrawls helfen - sind als Prinzip weiter gültig. Wer heute rendernde Crawler aus den eigenen Daten halten will, findet einen aktuellen, tool-übergreifenden Ansatz im Beitrag zur serverseitigen Erkennung rendernder Bots. Der Beitrag bleibt als Zeitdokument erhalten.
Auf der CAMPIXX habe ich in Diskussionen im Anschluss an mehrere Sessions gehört, dass die Untersuchung der eigenen Website mit Tools wie dem Screaming Frog SEO Spider zunehmend Spuren in der Webanalyse hinterlässt, seit deren Crawler in der Lage sind, nicht nur den Quelltext einer Seite herunterzuladen und zu analysieren, sondern auch wie ein normaler Browser zu rendern. Ganz nach dem Vorbild von Google.
Aber stimmt das wirklich? Als “Webanalyse-Spam-Fan” bin ich darauf natürlich angesprungen und wollte es genauer wissen. Für eine Antwort muss also überprüft werden, ob sich in Google Analytics Hits nachweisen lassen, die durch Crawl-Vorgänge mit gängigen SEO- und OnPage-Tools entstehen, wenn deren Crawler die untersuchten Seiten auch rendern und nicht nur den Quellcode abrufen.
TL;DR
Für die untersuchten Tools wurde unterschiedlich hoher Aufwand betrieben, was sowohl an Verfügbarkeit von Crawl-Vorgängen als auch den erzielten Ergebnissen abhängig war. Der daraus abzuleitende “Zwischenstand”:
- Der Frosch beißt Google Analytics nachweislich nicht!
- UPDATE 10/2019: ... aber durch die neue Option der Ermittlung von Lighthouse-Scores via PageSpeed API gelangen die durch die API gerenderten Seiten als Besuch in Analytics. Infos zu in einem separaten Beitrag.
- Das zu erwartende Volumen der durch andere Tools entstehenden Störsignalen ist gering und es besteht vermutlich für 99% aller Websites kein Grund zur Sorge.
- Generell aber gehen Hits raus, wenn ein Tool rendert und sie kommen i. d. R. auch an, wenn man nichts dagegen unternimmt - entweder als Anbieter oder Benutzer.
- Ausnahmen gibt es. Screaming Frog gehört dazu.
- Filter können dort helfen, wo das Tool keine eigenen Maßnahmen ergreift, aber das hilft ggf. nur gegen “eigene” Besuche.
- Analytics und andere Systeme sind theoretisch vermutlich dazu in der Lage, Crawler zu erkennen und aus den Daten zu halten. Sie tun dies aber nicht; zumindest nicht zuverlässig.
- Stellvertretend für andere Systeme wurde der etracker parallel getestet. Die Ergebnisse weichen von Google Analytics ab, das Problem besteht in der Praxis aber auch hier; nur bei anderen Tools.
Untersuchte Tools
Untersucht wurden die Auswirkungen der folgenden installierbaren oder cloudbasierten Tools mit renderfähigen Crawlern:
So wurde gemessen
Es werden separate Einstiegsseiten untersucht, deren Start-URLs über einen Parameter eindeutig auf einen Crawl-Vorgang zurückgeführt werden können. Dies wurde auf zwei unterschiedlichen Domains vorgenommen, wobei dort jeweils zwei Analytics-Profile im Einsatz sind.
- die normale clientseitige Implementierung in den Seiten in Form des direkt eingebauten Universal Analytics Codes und
- serverseitige Messung via Google Measurement Protocol als schnellen Ersatz für Logfileanalyse.
Die zweite serverseitige Messung sollte vor allem dazu dienen, schnell an die Daten der Crawlvorgänge zu kommen, deren besuchte URLs und Umfang des Crawls zu bestimmen und eine Vergleichsdatenansicht zu haben, durch die der Zeitpunkt bestimmt werden konnte, zu dem die Hits auch im clientseitigen Profil erwartet werden dürfen, wenn diese dort durchkommen.
- Untersucht wurden filterlose Rohdatenansichten der Properties. Um mehr über die Hits zu erfahren, sammeln beide Websites sowohl client. als auch serverseitig in einer benutzerdefinierten Dimension (auf Session-Ebene) zusätzlich die Angaben des UserAgents.
- Die Option zum Ausschluss bekannter Bots und Spider war in den Datenansichten deaktiviert.
- Um zu bestimmen, ob Spuren solcher Crawler ggf. andere Tools betreffen, wurde zudem auf beiden Domains parallel mit einer Testversion von etracker Web-Controlling gemessen.
Zu jedem Test wurde jeweils eine eindeutige Kennung als Parameter in der Einstiegs-URL angehängt. Dieser wurde als zu erhaltender Parameter im etracker eingetragen, damit die Einstiege anhand der URLs auch dort erkennbar werden.
Ergebnisse
Screaming Frog SEO Spider
Die Vermutung, dass Crawling mit dem Frosch auch in Google Analytics zu sehen sein müsste, wenn die Seiten gerendert werden, war der eigentliche Anlass dieser Testserie.
Es ließen sich allerdings keine Daten nachweisen, die es durch einen Crawl-Vorgang mit eingeschaltetem Rendering in die Webanalyse geschafft haben.
Trotz der zahlreichen Einstellungsmöglichkeiten ist es nicht gelungen, die Vermutung zu bestätigen. Es wurden mehrere vollständige Crawls beider Websites von zwei unterschiedlichen Standorten aus abgeschlossen. Dabei wurde der UserAgent mehrfach gewechselt und auch Werte für Crawl-Delay oder Cookie-Akzeptanz variiert. Das Ergebnis blieb stets gleich.
Spuren in Google Analytics
Serverseitig ließen sich die einzelnen Vorgänge stets nachweisen, wenn ein erkennbarer Crawler und / oder eine eindeutige Einstiegsseite verwendet wurde.
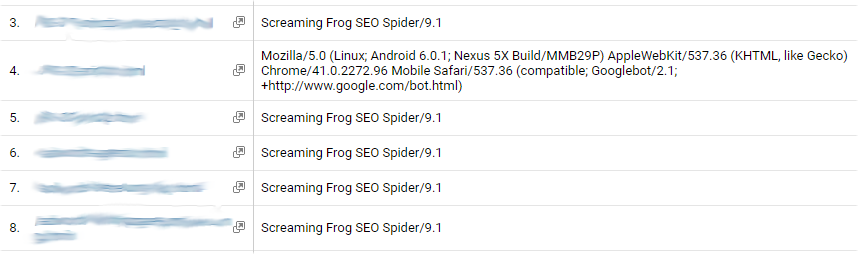
In der “clientseitigen” üblichen Messung hingegen konnten die markierten Einstiegsseiten nicht gefunden werden - und auch andere Seiten zeigten keine Besuche des testweise eingestellten UserAgents… auch nach mehr als 48 Wartezeit.
Erklärung: Es wird aktiv blockiert
Die Erklärung ist einfach. Auf Nachfrage gibt der Hersteller an, dass die Scripts für Google Analytics explizit geblockt werden. Genannt sind explizit ga.js und analytics.js - von gtag.js ist (noch) nicht die Rede, was ein Problem werden kann, sobald dieses auf eigenen Füßen steht und nicht an analytics.js “hängt”.
Zur Beachtung: Wenn PageSpeed-Werte ermittelt werden, landen auf Umwegen dann doch Spuren in Analytics.
Was ist mit anderen Tools? Ausschlüsse nutzen!
Andere Scripts von Webanalysetools, Werbenetzwerken oder Dingen wie Heatmapping- und Clicktracking-Werkzeugen werden nicht von selbst geblockt. Wer hier Daten sauber halten will, muss selbst tätig werden. Sind die beteiligten Scripts identifiziert, können diese in die Exclusion-Liste im Screaming Frog eingetragen werden - auch beim Rendern hält sich das Tool nach Herstellerangaben an diese Ausschlüsse, so dass unerwünschtes Tracking darüber unterbunden werden kann.
Tut man das nicht, sind Spuren zu erwarten. Hier ein Beispiel aus dem etracker, bei dem leider auch nichts vom eingestellten Browser (hier war es Chrome) zu sehen ist in den zusätzlichen Dimensionen:
![]()
Das ist aber nicht die Schuld des etracker, denn der Frog sendet Requests offenbar im Standard wirklich nur mit seiner Kennung, sonst nichts (wie man oben auch in den serverseitigen Hits nebst UserAgent sieht). Das ist zu wenig, um daraus Browser, Betriebssystem o. a. zu ziehen.
Wiederholt man aber den Test mit geblocktem Trackingscript “static.etracker.com/code/e.js”, bleibt es auch dort still nach einem Crawl. Ausschlüsse sind also eine gute Lösung, wenn man sich von evtl. Nebenwirkungen des Screaming Frogs (wie z. B. botgemachten Anzeigeneinblendungen :))) befreien will.
Sitebulb
Ähnlich wie der Screaming Frog dient auch Sitebulb als lokal installiertes Tool zur Untersuchung und zum Crawling von Websites. Es sollte also die gleichen potentiellen Probleme geben, wenn hier nicht ebenso aktiv blockiert wird.
In den Einstellungen des Crawlers kann das Rendering aktiviert werden:
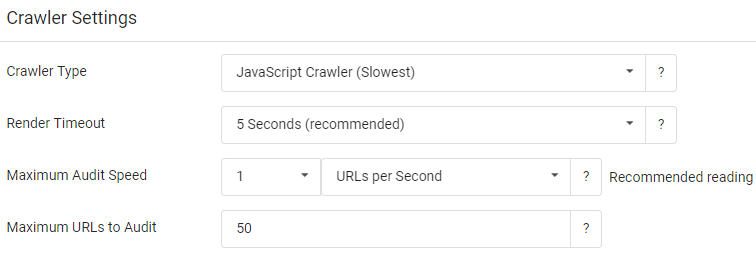
Über weitere Einstellungen wie Anzahl der Threads statt URLs, UserAgent etc. kann man ähnlich wie beim Frog “maximal unauffällig” sein.
Spuren in Google Analytics
Nach dem Start einer Untersuchung ist in der Echtzeitdatenansicht nichts zu sehen. Serverseitig sieht man dort hingegen parallel, wie der Crawler arbeitet.
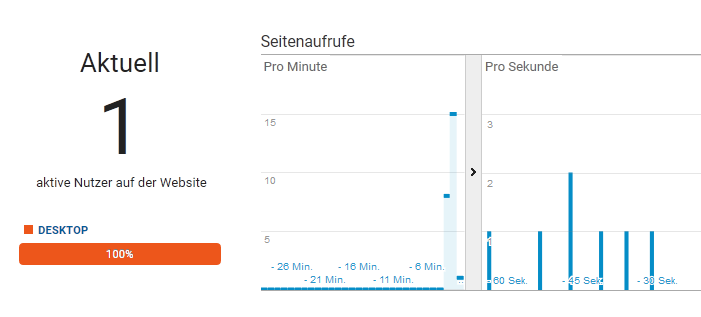
In den Client-Berichten sind auch hier keine Spuren des Tools zu finden. Was nach Rückfrage beim Anbieter darauf zurückzuführen ist, dass hier die Scripts von Analytics ebenfalls aktiv blockiert werden.
Umfangreiches Blocking
Anders als beim Screaming Frog hört man bei Sitebulb nicht bei GA auf - auch andere Scripts werden möglichst geblockt, um Trackingtools nicht zu verwässern. Zitat “Since then we've been very careful about what we do and don't fire, to make sure we don't cause widespread panic to all our users!”
Infolgedessen im auch im etracker nichts zu finden. Selbst die “vorsichtigste” Konfiguration kommt nicht durch - weil das Tool hier die Aufrufe ebenfalls vorbildlich blockiert. Da mag die Tatsache geholfen haben, dass “tracker” im Domainnamen vorkommt 😉
SearchMetrics
Es sei verraten: Auch mit aktivem Rendering scheint ein Crawl mit SearchMetrics keine Veränderungen in Google Analytics zu erzeugen. Obschon lt. Searchmetrics keine Scripts beim Laden oder feuern blockiert werden, die Hits also genauso “rausgehen” sollten, wie das bei SISTRIX der Fall ist (siehe unten).
In der Suite kann per Option “JavaScript Crawl” des Crawlers das Rendering aktiviert werden:
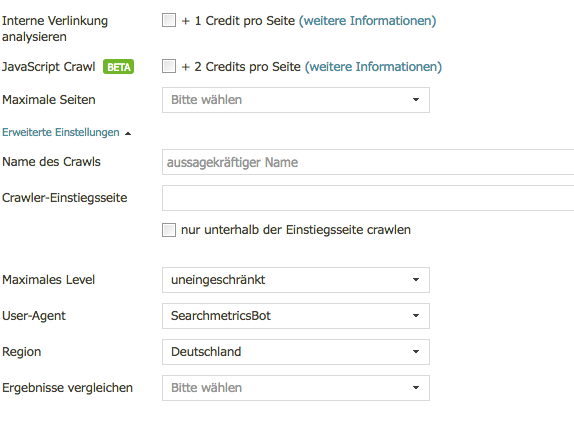
Der UserAgent ist entweder GoogleBot oder SearchMetrics Bot (Default). Der serverseitig aufgezeichnete UserAgent war im Test “Mozilla/5.0 (compatible; SearchmetricsBot; http://www.searchmetrics.com/en/searchmetrics-bot/)”.
Spuren in Google Analytics
Es gibt keine erkennbaren Spuren in der Webanalyse. Weder in Google Analytics noch im etracker.
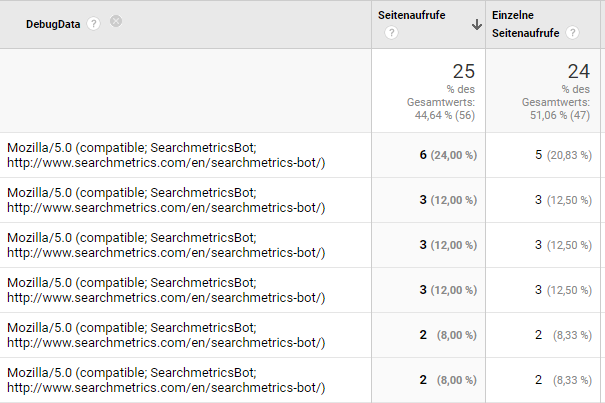
Es wurden zum Test zwei Durchgänge mit markierten Einstiegs-URLs auf unterschiedlichen Domains untersucht, mit und ohne Delay, UserAgent war der SearchMetrics Bot. Ein weiterer Versuch als GoogleBot sollte aber - wenn Google seinen Job versteht - keinen Unterschied ergeben. Dass Analytics und der etracker keine Daten aufweisen, mag daran liegen, dass die Untersuchung einer Seite mit einem Besuch nicht zwingend erledigt ist - hier die Daten zum Crawlvorgang aus dem serverseitigen Tracking, die aus einem einzelnen Crawl stammen (primäre, aber hier abgeschnittene Dimension ist die Seiten-URL):
SISTRIX
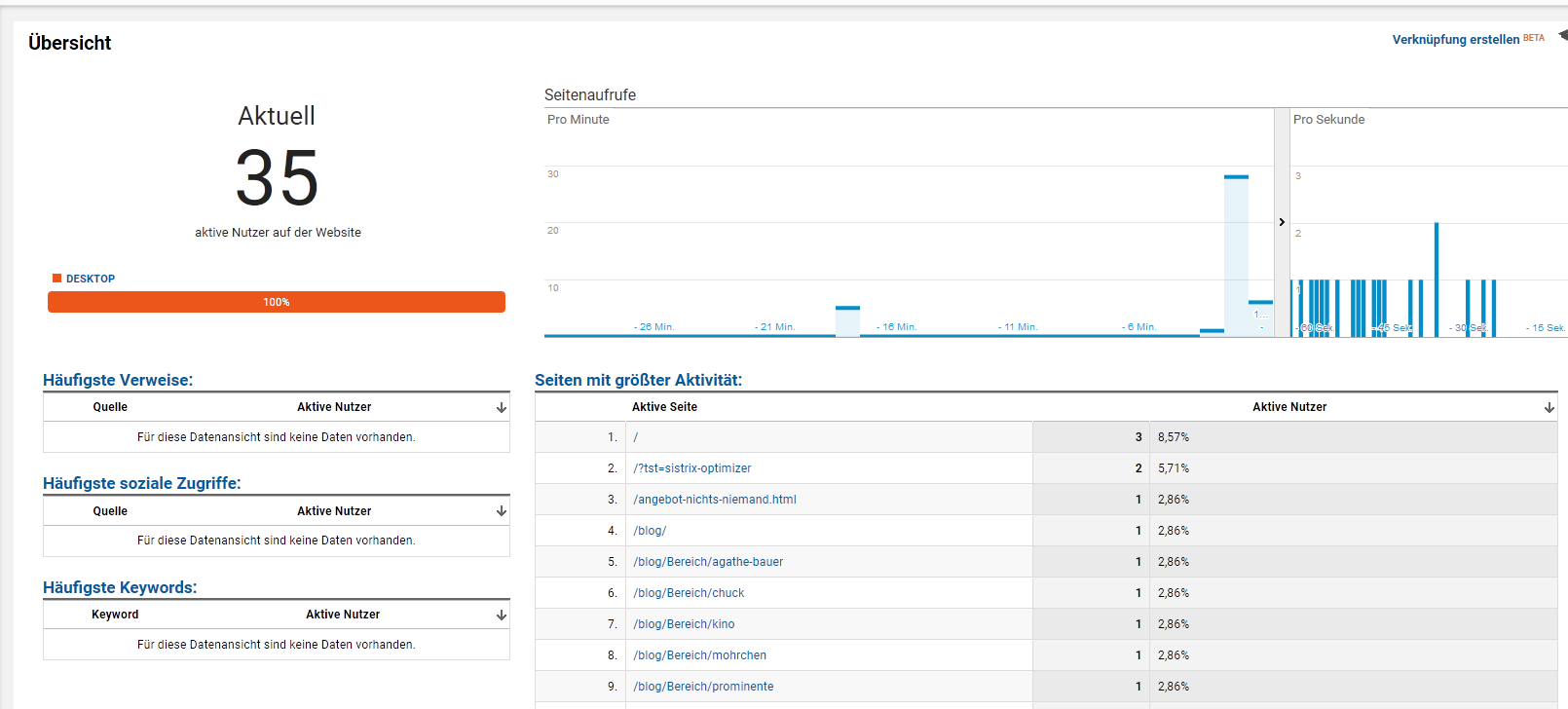
Der SISTRIX Optimizer ist ebenfalls in der Lage, Seiten zu rendern und so eingehender zu untersuchen, als es mit der “Nur-Text-Fassung” der Seite möglich wäre. Wird diese Option genutzt, landen alle Hits auch in Google Analytics.
Schon in der Echtzeit-Ansicht sind die parallel laufenden Besuche messbar.
Spuren in Google Analytics
Die Hits werden “ungebremst” in die Daten gelassen, wenn man nichts dagegen unternimmt. Wer viel und regelmäßig hiermit hantiert, mag also nennenswerte Veränderungen der Kennzahlen damit provozieren.
Auch im etracker waren die Ergebnisse des Crawls zu sehen (leider mit leerem “Browser” oder anderen Angaben wie Browserversion, Betriebssystem o. Ä. - siehe Abbildung beim Screaming Frog).
Lösung: Filtern
Wer über die eigene Site “herfällt”, kann in SISTRIX (und bei Bedarf auch Searchmetrics und anderen Tools) selbst bestimmen, welcher User Agent verwendet wird.
Der Headless Browser von SISTRIX verwendet im Standard zwar einen eigenen User Agent, allerdings ist er so nicht sicher anhand des Browser-Namens zu identifizieren. Um dies zu ändern, trägt man einfach einen eigenen User Agent ein.
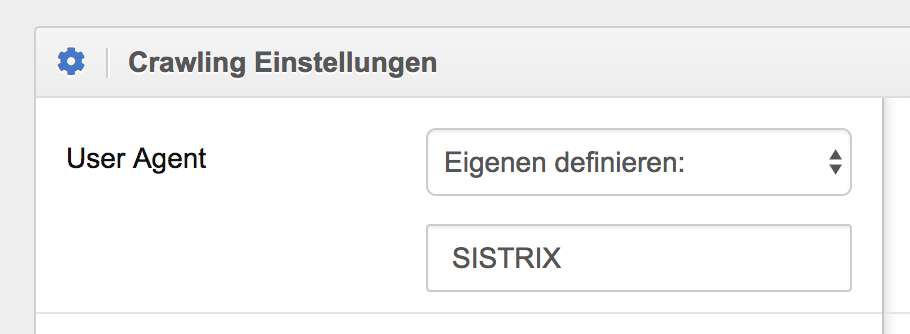
Das Ergebnis von zwei Besuchen - einmal mit Standardeinstellungen und einmal mit nichts als “SISTRIX” als User Agent (freilich kann man den Eintrag auch komplexer gestalten und dennoch einen erkennbaren Browser erzeugen, aber so geht es eben auch ;)):
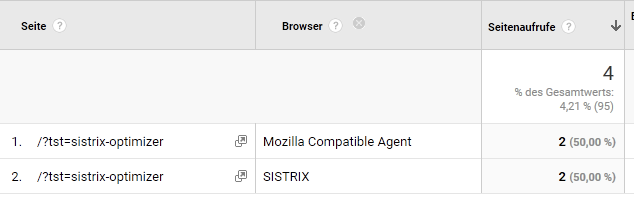
Im zweiten Fall erkennt man, dass nun auch der Browser passenderweise SISTRIX lautet.
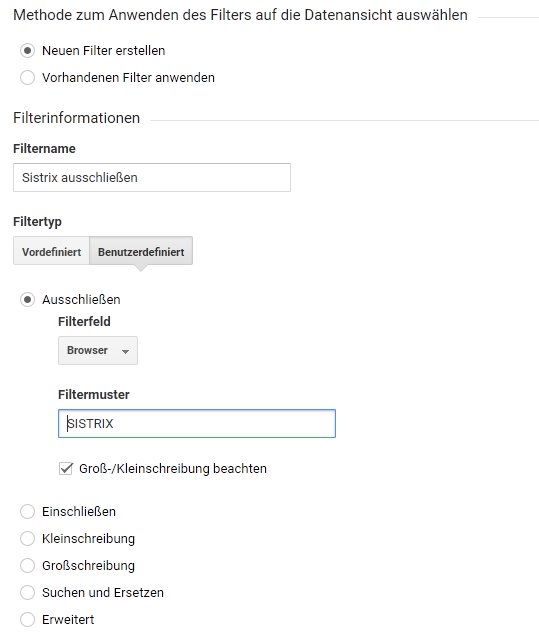
Wer in seinen Arbeitsdatenansichten also nichts von evtl. Crawls des Optimizers sehen will, kann alles ausschließen, was von diesem Browser an Hits im Analytics-Konto ankommt, wenn er den User Agent in den Crawler-Einstellungen anpasst. Ein solcher Filter sieht dann z. B. so aus:
XOVI
XOVI rendert nur die Einstiegsseite einer OnPage-Analyse, dieses Verhalten ist auch nicht konfigurierbar. Um es kurz zu machen: Diese Hits kommen durch; egal welche Einstellungen gemacht wurden, ob Cookies akzeptiert werden, Ein Crawl-Delay genutzt wird oder nicht - das alles kann auch keinen Einfluss haben, wenn es stets nur einen Hit pro Analyse gibt.
Spuren in Google Analytics
Serverseitig sind einzelne Checks unter “Mozilla/5.0 (compatible; XoviOnpageCrawler; +http://www.xovi.de/)” aufgezeichnet.
Die Spuren in der clientseitigen Webanalyse sind z. B. mit dem UserAgent “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/37.0.2062.120 Safari/537.36” angekommen. Nichts Filterbares also.
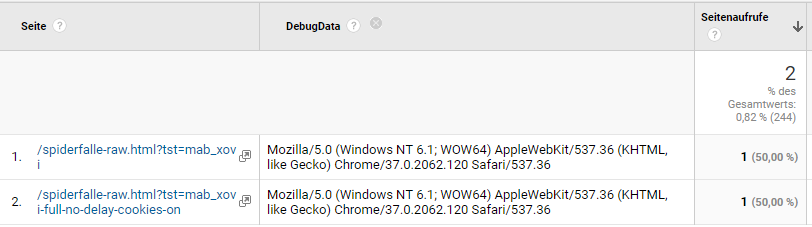
Im etracker erscheinen die Hits überraschenderweise nicht, auch nicht nach mehreren Versuchen. Eine Erklärung steht hier aus; ich habe nun aber aber ausreichend lange auf eine Rückmeldung gewartet 😐
Google Search Console
Da man auch hier über "Abruf wie durch Google-Bot" einzelne Seiten vom Googlebot oder seinem mobilen Kollegen besuchen und rendern lassen kann, soll der Vollständigkeit auch dieser Vorgang hier erwähnt werden. Wie XOVI sind es ohnehin nur einzelne Seiten, aber man könnte erwarten, dass zumindest Hits "aus dem eigenen Haus" die Daten von Analytics nicht betreffen.
Spuren in Google Analytics
Leider falsch geraten: Die Aufrufe, die hier über eine eindeutige URL beim Abruf gekennzeichnet werden, sind auch in GA wieder zu finden. Auch dann übrigens, wenn "Treffer von bekannten Bots und Spidern" in den Einstellungen der Datenansicht ausgeschlossen werden. Der Googlebot ist vermutlich zu exotisch 😉
Die einzig gute Nachricht für alle, die z. B. serverseitig - oder im Trackingcode - auf den User Agent reagieren wollen: Die Besuche des Crawlers aus der GSC weisen sich eindeutig mit "Search Console" im User Agent String aus.
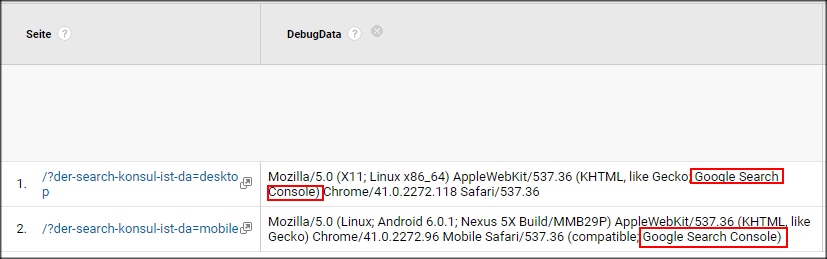
Außerdem steht auf der Haben-Seite, dass man sich diese Hits nur als verifizierter Webmaster der eigenen Domain selbst zufügen kann. Aber was tun gegen den Rest?
Lösungen
Ausschlüsse / Kennzeichnungen
Wie gezeigt ist Google Analytics nicht anfällig, wenn es um installierte Tools geht - zumindest bei den beiden hier betrachteten Kandidaten. Eine Seite bei XOVI tut niemandem weh und wer viel mit dem SISTRIX Optimizer oder anderen Tools arbeitet, kann sich per Filter befreien... solange er den Crawl-Vorgang selbst anstößt.
Wenn es in anderen Lösungen doch dazu kommen sollte, dass ein Crawl Spuren hinterlässt, gibt es darüber hinaus zahlreiche, wenngleich dazu vermutlich selten genutzte Einstellungsoptionen von Ausschlusslisten für URLs bis zu benutzerdefinierten Headern, die mit der Anfrage gesendet und ausgewertet werden können. Hier am Beispiel von Sitebulb (aber auch im Screaming Frog gibt es “Custom Headers”):
Kampagnenparameter für Google Analytics? Kaum
Will man - für welches Tool auch immer, das regelmäßig und umfangreich genug genutzt wird, um damit ansonsten Schaden anzurichten - eine generelle Lösung für das Problem nutzen, bieten sich als Ausweg theoretisch Kampagnen-Parameter bei der Einstiegs-URL an.
Werden dazu URL-Parameter wie https://www.domain-name.de/?utm_source=crawler&utm_medium=referral&utm_campaign=toolname-hier-angeben bei der Einstiegs-URL verwendet, könnte für die Quelle “crawler” ein Ausschluss-Filter definiert werden, so dass diese Hits sicher blockiert werden könnten. Problematisch ist diese Lösung allerdings deshalb, weil viele Tools mehrere Instanzen der Crawler in unabhängigen Prozessen parallel nutzen und dadurch als unterschiedliche Benutzer gemessen werden. Von denen wird dann nur derjenige ausgeschlossen, der beim Einstieg den Parameter mitgebracht hat, der Rest kommt durch. Es ist daher zu hoffen, dass auch künftige Tools so umsichtig sind, Ausschlusslisten anzubieten, die auch beim Rendern respektiert werden.
Webanalyse-Systeme schlauer, als man denkt?
Vermutlich sind Crawl-Vorgänge, wenn diese mehr als nur eine Seite rendern und von einer überschaubaren Anzahl von IPs aus operieren, für Google als Quellen von aus Sicht der Webanalyse “unerwünschten” Hits durchaus erkennbar. Die Tatsache, dass aber ohne Maßnahmen alle Hits von SISTRIX durchkommen, obschon diese von einem konstanten Server erfolgen, ist überraschend. Denn: Warum dann nicht auch die von Searchmetrics?
Inwiefern dabei auch die Verwendung eines Headless-Browsers einen erkennbaren Abdruck hinterlässt und / oder ob das Fehlen von Spuren in Analytics das Ergebnis von gezielt gegen Verunreinigung durch Crawler gerichteten Maßnahmen oder nur eine Nebenwirkungen des besser werdenden Ghost-Spam Schutzes bei Google ist, kann ich nicht beurteilen. Im Ergebnis bleibt aber, dass neben einzelnen Hits keine massenhafte und signifikante “Verunreinigung” durch die hier untersuchten Crawler zu befürchten ist, auch wenn diese die untersuchten Seiten rendern. Bei denen, die per Default blockieren - wie die installierten Tools oder - wenngleich der Grund hier unklar bleibt - auch Searchmetrics - ist es egal, ob der Crawl vom Betreiber selbst angestoßen wird oder nicht.
Dass der etracker Spuren von Crawls zeigt, wenn diese z. B. mit dem Screaming Frog durchgeführt werden (der nur explizit nichts an GA sendet), spricht dafür, dass es zwar vielleicht erkennbare Muster gibt, die dann vom Anbieter aus der Webanalyse herausgehalten werden könnten; dies aber offenbar nicht großflächig passiert. Ob man dabei mit einem “unauffälligen” UserAgent agiert oder nicht, scheint keine Rolle zu spielen.
Selbst testen, selbst blockieren. Aber die anderen?
Die Verantwortung bleibt also hauptsächlich beim Benutzer der Tools, wenn diese nicht zufällig - wie im Fall von Google Analytics - aktiv das Laden der Scripts im Rendering-Prozess blockieren. Das ist eine brauchbare Lösung für einen Großteil der Fälle, aber eben nicht alles. Wenn fremde Seiten untersucht werden und dort etwas anderes als Google Analytics betrieben wird, ist die Wahrscheinlichkeit groß, dass die Hits auch in der Webanalyse und den anderen Tools ankommen. Wer sich darüber Gedanken macht, kann nur die entsprechenden Tools in der robots.txt sperren und hoffen, dass dies auch akzeptiert wird. Da einige Tools aber das Ignorieren dieser Angabe als Option anbieten, hilft auch das nur bedingt. Andere wie SISTRIX respektieren die robots.txt aber z. B. “zwangsweise” - wer nicht be- / untersucht werden will, kann das also einstellen.
Fazit und Ausblick
Obschon in der Branche die Annahme bzw. Befürchtung besteht, dass zunehmendes Rendering durch die Toolanbieter zu steigenden Problemen mit unsauberen Webanalysedaten führen wird, ist davon bisher nichts oder nur sehr wenig zu sehen.
Was ohne Möglichkeit zur Filterung durchkommt, ist deutlich zu gering, um Analyseergebnisse nennenswert zu verfälschen. Da sind sogar der “Rest-Ghost-Spam” und selbstgemachte Störungen durch internen Traffic größere Probleme - jedenfalls zum jetzigen Stand der Dinge und Erkenntnisse im Rahmen dieser eher kleinen Testreihe.
Also kann zumindest als Benutzer von Google Analytics - vermutlich - einstweilen beruhigt sein. Crawlageddon in Analytics fällt also offenbar erst einmal aus. Zumindest in Bezug auf die untersuchten Tools.
Auch dass es in zahlreichen Agenturen und Marketingabteilungen selbst aufgesetzte Crawler gibt, die regelmäßig - z. T. mehrfach täglich - Websites besuchen, ist zur Zeit noch kein Problem. Wenn diese aber ebenfalls mit dem Rendering anfangen, können einzelne Websites (vor allem Shops) einiges an künstlichen Besuchen messen. Hier bleibt zu hoffen, dass die Masse der echten Besucher dies zu einem vernachlässigbaren Faktor degradiert. Zum Glück gibt es für die meisten dieser Crawler und Scraper aber keinen guten Grund zum Rendern und so werden sie dies nicht einfach tun, da Crawlvorgänge dadurch ungleich langsamer und ressourcenintensiver werden.
Websites, die andere Analyse-Tools einsetzen, haben aber auch jetzt schon - bezogen auf die o. a. Crawler - im Einzelfall ein größeres Problem, wenn der Hersteller nicht auch dafür eigens eine Blockade eingerichtet hat oder zumindest nicht nur einen erkennbaren User Agent, sondern auch für Filter üblicherweise nutzbaren Feldern wie dem Browser erkennbare Muster liefert, die dann auch in anderen Tools zur Segmentierung und / oder Filterung genutzt werden können. Die Ausschlusslisten der Tools wie dem Screaming Frog und Sitebulb schützen jedenfalls nur dann, wenn man sie auch nutzt, sobald es um Analysesysteme geht, die im jeweiligen Tool nicht aktiv blockiert werden.
Abspann: Danke!
Bei den Tests und Crawls haben einige nette Menschen tatkräftig geholfen. Dank gebührt Thorsten Biedenkapp für ausführliche Frog-Sessions, Markus Klöschen von Searchmetrics für Testcrawls und Hintergrundinfos, Johannes Beus von SISTRIX für seine Zeit, Testcrawls und blitzschnelle Bereitschaft, am UserAgent String zu schrauben, damit die Hits filterbar werden (und das an einem Sonntag!). Merci vielmals! Und abschließend muss auch Liam Sharp vom Screaming Frog SEO Spider gefeiert werden, der mir auf eine Anfrage von Samstagabend am Sonntag antwortet - selbst auf meine Rückfrage nahezu direkt. Hut ab, auch wenn Du das vermutlich nie lesen wirst! Gleiches gilt für Patrick Hathaway von Sitebulb - Top Support, schnell und hilfreich.
Anmerkungen, Kommentare, Toolvorschläge für andere “rendernde Crawler”? Dann freue ich mich über eine E-Mail.